
The Apache Ignite 3.0 Alpha 5 build recently became available.
GridGain Blog



The virtual Ignite Summit on June 14 attracted hundreds of Igniters from around the globe excited to learn and share
their experiences.


GridGain is a USA-based company that has always prided itself on being a global corporation, with employees and customers around the world. A proponent of open-source software and the original authors of the highly popular Apache Ignite in-memory platform, our company has always embraced the diversity of thought and contribution that can only come from a worldwide community.


Great news: The Apache Ignite Community has released the fourth alpha build of Ignite 3!

Customer 360 View is a significant aspect of digital transformation, enabling organizations to gain insights into customer behavior. Armed with this understanding, companies can make data-driven decisions to serve their customers with personalized experiences and promote growth through targeted marketing.

TIBCO DataSynapse GridServer and Apache Ignite are both distributed computing solutions that provide high-performance capabilities.

In my previous blog posts—Ignite 3 Alpha: A Sneak Peek into the Future of Apache Ignite and Just Released: Apache Ignite 3, Alpha 2—I talked about the Apache Ignite community's journey toward Ignite 3, the next generation of the Apache Ignite database.

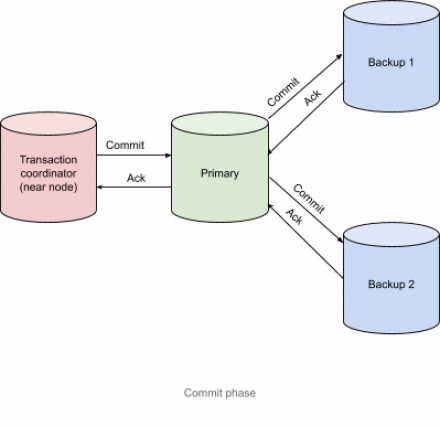
In this article, we look at how transactions work in Apache Ignite. We begin with an overview of Ignite’s transaction architecture and then illustrate how tracing can be used to inspect transaction logic. Finally, we review a few simple examples that show how transactions work (and why they might not work).

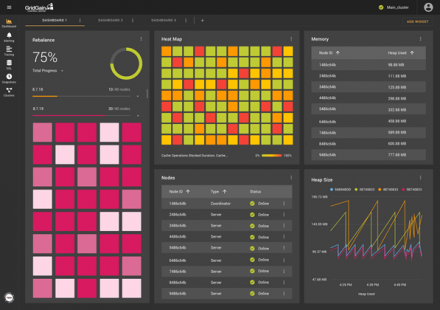
GridGain Control Center unifies monitoring, tracing, and management for Apache Ignite clusters, replacing complex multi-tool setups with one integrated platform.

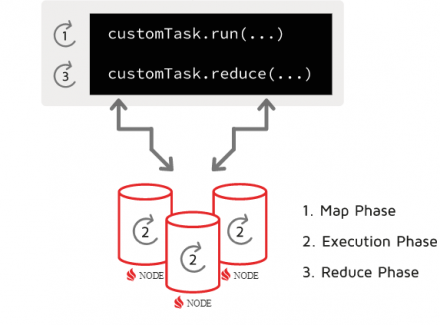
Publisher's Note: the article describes a custom data loading technique that worked best for a specific user scenario. It's neither a best practice nor a generic approach for data loading in Ignite. Explore standard loading techniques first, such as IgniteDataStreamer or CacheStore.loadCache, which can also be optimized for loading large data sets.