
Publisher's Note: the article describes a custom data loading technique that worked best for a specific user scenario. It's neither a best practice nor a generic approach for data loading in Ignite. Explore standard loading techniques first, such as IgniteDataStreamer or CacheStore.loadCache, which can also be optimized for loading large data sets.
Now, in-memory cache technology is becoming popular, motivating companies to experiment with distributed systems. The technology is advertised to be fast, and data-load speed is often critical for building a successful solution prototype. This blog post provides a technical tutorial on how to populate a distributed Apache Ignite cluster with values that originate from large relational tables. All the code in the tutorial is available from the FastDataLoad repository at the GitHub.
Introduction
One day, a company decided to accelerate a slow business application by replacing an RDBMS with a contemporary in-memory cluster and tasked a developer to lead the project. The usage of the distributed system is dictated by the volume of data: A database server is reaching its performance limits, and data volume is expected to increase. The slow application is only one of the many entities that form the processing pipeline of the production system, so there are strict latency requirements for data processing and for the data-loading phase. However, before the developer can tap into the distributed cluster, he needs to pre-load the cluster with the data that resides in the RDBMS. Loading small tables might be a trivial task, but loading X gigabytes or terabytes of data in Y amount of time might be a challenging task. Active googling indicates that there are few examples that can be scaled up to ten million or one hundred million row tables—examples that are easy to clone, compile, and debug. However, reading Apache Ignite and GridGain web resources, watching webinars, and attending meetups provide a glimpse of the internal design of the GridGain cluster. So, when someday a head officer asks “did you knock it out of the park”, the answer is “yes”. But the resulting code is kind of self-invented, homemade with an internal architecture flavor. The rest of this post covers the technical details of a straightforward data load. We’ll describe caches and underlying relational tables and see how to create a user POJO that is based on a SQL query result set and how to use ComputeTaskAdapter to distribute objects across the cluster. The interested reader can get deeper into code details. A complete implementation can be found in the FastDataLoad repository.
Dataset Used for the Experiment (World Database)
Because the volume of data is high, we use data partitioning to distribute data across the cluster and data collocation to ensure that logically linked cache values are stored on the same data node. This tutorial uses the data file “world.sql,” which is shipped with Ignite releases. The file was split into three CSV files, each emulating a SQL query result set. This tutorial shows how to populate each cache with values that are based on its result set:
- countryCache - country.csv;
- cityCache - city.csv;
- countryLanguageCache - countryLanguage.csv.
The country table is the first table to load. The table’s code field identifies key-values, which consist of three symbols each. The cache key type is String, and the cache values are the country objects, which are derived from the values in the name, continent, and region fields.
| Code | Name | Continent | Region |
| ABW | Aruba | North America | Caribbean |
| AFG | Afganistan | Asia | Southern and Central Asia |
| AGO | Angola | Africa | Central Africa |
Other tables are similar; one field provides the key values and the items in the other fields form the cache values.
Naive Data-Loading Method
The naive approach for data loading comes from single-host, non-distributed, JAR application development. A user POJO for Country should be created for each table row and placed into the cache before the next row is iterated. Internally, the Ignite cluster uses the H2 database. The org.h2.tools.Csv library is present on every node. The library can be used to convert a CSV file into java.sql.ResultSet. The naive code looks like the following:
// define countryCache
IgniteCache<String,Country> cache = ignite.cache("countryCache");
try (ResultSet rs = new Csv().read(csvFileName, null, null)) {
while (rs.next()) {
String code = rs.getString("Code");
String name = rs.getString("Name");
String continent = rs.getString("Continent");
Country country = new Country(code,name,continent);
cache.put(code,country);
}
}
This code works fine for small datasets and for single-node clusters. But, when we try to load a table that has ten million rows, the application performs sluggishly. With the naive approach, as the size of the dataset increases, the data-load time increases. The time problem occurs because the cache is distributed and the nodes are in sync and so every cache operation must spread across the cluster. To load the data fast, we must consider an internal cluster architecture.
Partition-Aware Approach to data Loading
An Apache Ignite cluster usually holds several key-value caches. When data volume is high, a cache is created in PARTITIONED mode. In PARTITIONED mode, every key-value pair is stored in the partition on the specific data node. For fault-tolerance reasons, a copy of that partition might exist on another node, but, for simplicity, we’ll think of the node as “alone.” To determine how to store the key-value pair, the cluster uses the affinity function to map the key to the partition and the partition to the node. Thus, the dataset is divided into partitions, with each partition coming to and lying on its data node. We want to load the ResultSet to the client node and distribute the partitions across the cluster. The client node does not hold data, so a partition distribution involves traffic over the network. In the following diagram, the client node uses a map-reduce task to communicate with three data nodes. The idea is to minimize cluster overhead by pre-arranging the data during the mapping phase on the client.
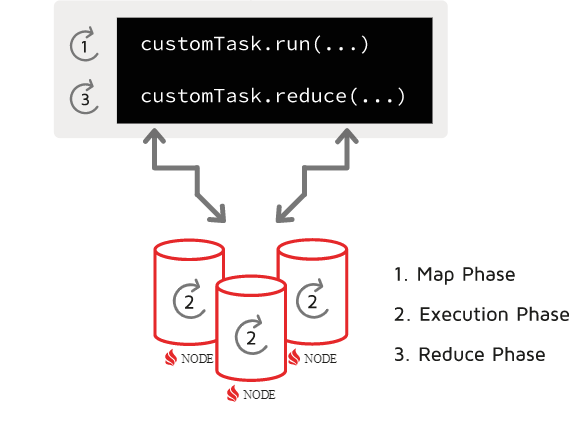
To load the data, we perform the following steps:
-
Instead of using a
cache.put()operation for each table row, we populate theresult map, which was preloaded on the client:Map<Integer, Map<String, Country>>result = new HashMap<>(); try (ResultSet rs = new Csv().read(csvFileName, null, null)) { while (rs.next()) { String code = rs.getString("Code"); String name = rs.getString("Name"); String continent = rs.getString("Continent"); Country country = new Country(code,name,continent); result.computeIfAbsent(affinity.partition(key), k -> new HashMap<>()).put(code,country); } }The affinity function provides the partition number for the key, and the key-value pair goes to the specified partition-data chunk.
- We use ComputeTaskAdapter, which creates multiple ComputeJobAdapter jobs. In this tutorial, the number of jobs is 1024, as determined by the number of partitions. Each job object is created with the data chunk inside it. The object is then mapped to a specific data node.
- When a job is executed on a data node, the added value count is returned to the client node. The client node reduces the results. In our case, it calculates the total count of added values.
Compute Task, how it Looks from the Inside
ComputeTaskAdapter initiates the simplified, in-memory, map-reduce process. The process involves 1024 data-node jobs and 1 client-node task.
Data node Job (RenewLocalCacheJob)
No matter what kind of data is loaded, a partition journey begins on the client node and finishes on one of the data nodes. The RenewLocalCacheJob object is involved in every step of the process. The object is created on the client node with the data map inside it. Then, the object goes over the network to the destination node and places the data inside the local cache:
targetCache.putAll(addend);
RenewLocalCacheJob is a basic over-the-partition operation. In this tutorial, it is used by all data loading tasks. For demo purposes, when execution is complete, a diagnostic message is printed on the remote node.
Client node Task (AbstractLoadTask)
In the loader package, each load task extends the AbstractLoadTask. The load tasks extract different fields out of the query result and create different user POJO objects. Caches may have different key types, either primitive or user-created. Therefore, AbstractLoadTask has the type parameter TargetCacheKeyType, and the preloaded map is defined as
Map<Integer, Map<TargetCacheKeyType, BinaryObject>>
In this tutorial, only the countryCache has a primitive key type (String). The other caches have compound keys and the type parameter is BinaryObject. That is because the compound key classes are user-defined POJOs and we must use BinaryObject on the data nodes.
Why BinaryObject Instead of user POJO
We want to populate remote data nodes with user POJO objects. The class definitions of the POJOs are inside the application JAR file that is used by the client node and are not available in the data node server’s classpath. Thus, if you try to access Country records on a data node via IgniteCache<String,Country> countryCache Ignite will try to deserialize the records. Then, because it cannot find the Country class in the classpath, Ignite will generate a ClassNotFound exception.
There are two ways to eliminate the exception. The first way is to add application-specific classes to the classpath. But, this method is impractical, because the node must be restarted:
- Create the JAR file with all client POJOs.
- Place the JAR file on the servers’ classpath of every data node.
- Do not forget to replace the JAR file after every change in any of the classes.
- After the JAR file is changed, restart the node.
The second, more sustainable approach, is to use the BinaryObject interface to access the records on the data nodes in their raw (serialized) representation. The following steps detail how the interface is used to populate the preloaded map:
- First, Get the Country cache reference is defined in binary form:
IgniteCache<String, BinaryObject> countryCache; - When the countries are loaded (see LoadCountries.java), the Country POJO object is created and converted to BinaryObject
Country country = new Country(code, name, .. ); BinaryObject binCountry = node.binary().toBinary(country); - Third, the binary object is put in the result map, which also uses the binary format:
Map<Integer, Map<String, BinaryObject>> result
Preprocessing is done on the client node, with all class definitions present. The remote data nodes do not need class definition, so ClassNotFoundException is eliminated.
Practice: Starting Ignite Cluster
We’ll use the minimum Apache Ignite cluster that is sufficient for the demo: two data nodes and one client node.
Data Nodes
Data nodes are in the out-of-the-box state with a minimal change in the "default-config.xml" file. Peer class loading is enabled. The following steps detail the installation process:
- Install GridGain CE via ZIP Archive (see using ZIP Archive).
- Because the repository code is built on gridgain-community-8.7.10, on the download page, choose version 8.7.10.
- Go to
{gridgain}\config, open the default-config.xml file and add the following lines:
This change will ensure custom object loading from the client node to the data nodes.<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="peerClassLoadingEnabled" value="true"/> </bean> - Open a command-line window, navigate to the
{gridgain}\binfolder and start the data node by usingignite.bat. For testing or development, the two nodes can be placed on the same machine. For production, use separate machines. - In another command-line window, repeat the previous step. Output similar to the following indicates that the two server nodes are up and ready:
[08:40:04] Topology snapshot [ver=2, locNode=d52b1db3, servers=2, clients=0, state=ACTIVE, CPUs=8, offheap=3.2GB, heap=2.0GB]
Important. If you choose the latest version to download, for example 8.7.25, do not forget to change the following line in the pom.xml to specify the version that you’re downloading:
<gridgain.version>8.7.25</gridgain.version>
The client and the data node versions must be the same. If they’re not the same, an exception is thrown:
class org.apache.ignite.spi.IgniteSpiException: Local node and remote node have different version numbers (node will not join, Ignite does not support rolling updates, so versions must be exactly the same) [locBuildVer=8.7.25, rmtBuildVer=8.7.10]
Client Node
All the work is done by the client application that contains the cache definitions, user POJOs, map-reduce logic, and so on. The application is a JAR file that starts the GridGain client node, and uses a compute task to load data. For the demo, we use a Windows host machine that has three command windows. For production, multiple hosts, each in a Linux environment, is preferable. Now, follow these steps to run the loader:
- Clone the FastDataLoad repository to the folder that you prefer.
- Go into the root directory of the project and build the project with Maven:
mvn clean package - Open another command-line window and start the application that was built in Step 2:
java -jar .\target\fastDataLoad.jar
The entry class LoadApp creates a user POJO that contains file and cache names, converts the POJO to binary form, and executes the LoadCountries map-reduce process.
First, the two data nodes print their messages. For each processed partition, Node 1 prints diagnostic messages that show partition number.
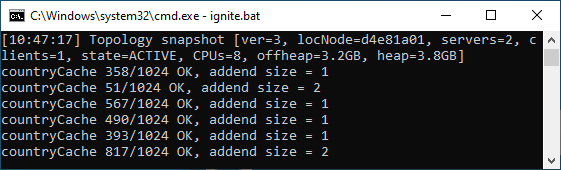
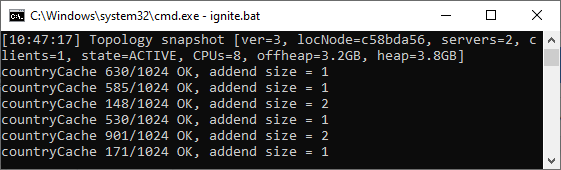
Node 2 shows its numbers. Notice that the number sets of the two nodes do not intersect.
Second, the client node reports the loaded row count.
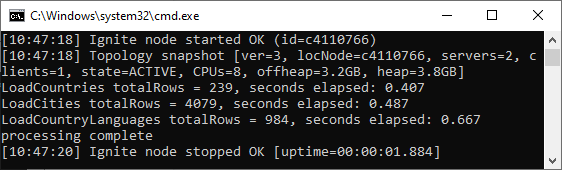
The country.csv file is loaded, CountryCode keys are collected in partitions, and each partition is placed in memory on its data node. The process is executed again for cityCache and countryLanguageCache, the client application prints the row counts and the uptime, and stops.
Summary
Partition-aware data loading produces acceptable performance. Naive loading requires an unacceptable amount of time. In fact, naive loading is so much slower that there’s no comparison between the two methods.
The partition-aware approach was tested and used in a real production environment. The following example gives a general idea of how fast this approach can be:
- table properties (SQL Server Management Studio):
- row count—44,686,837
- data space—1.071GB
- time to pre-process the SQL result set on the client node—0H:1M:35S
- time to map the jobs and reduce the result—0H:0M:9S
The pre-arranged data is distributed in the cluster much faster than it is loaded.