
My acquaintanceship with PostgreSQL started back in 2009 - the time when many companies were trying to board the social networking train by following Facebook's footsteps. An employer I used to work for was not an exception. Our team was building a social networking platform for a specific audience and faced various architectural challenges. For instance, soon after launching the product and getting a high load, we noticed that Postgres was beginning to "choke". We moved the database to machines with more CPUs, RAM, and faster disks, which restored the performance of the service, but only until more users signed up, and we faced the same issue all over again. So, we researched on how Facebook had tackled a similar challenge and, following the best practices, implemented a custom sharding for Postgres by allocating multiple Postgres servers to distribute data evenly and manage load balancing.
Over the years, the tech industry has been disrupted by mobile, big data, and IoT revolutions. This simply means that now Postgres needs to store and process much more data and at a much faster speed. Let me introduce some of the well-known solutions, such as caching, in-memory data grids, Postgres-XL and others that help Postgres withstand these modern challenges. If you prefer watching than reading, check this webinar that provides more details.
Tapping into RAM with shared and OS caches
Postgres is a disk-based database, and it's important to tap into RAM even if your entire architecture is designed around disk access. This can reduce the latency from days to minutes if you judge by the latency at human scale (Figure1). Just glance at the table below that shows how tremendously faster access to RAM or Intel Optane DC PM in comparison to disk I/O.
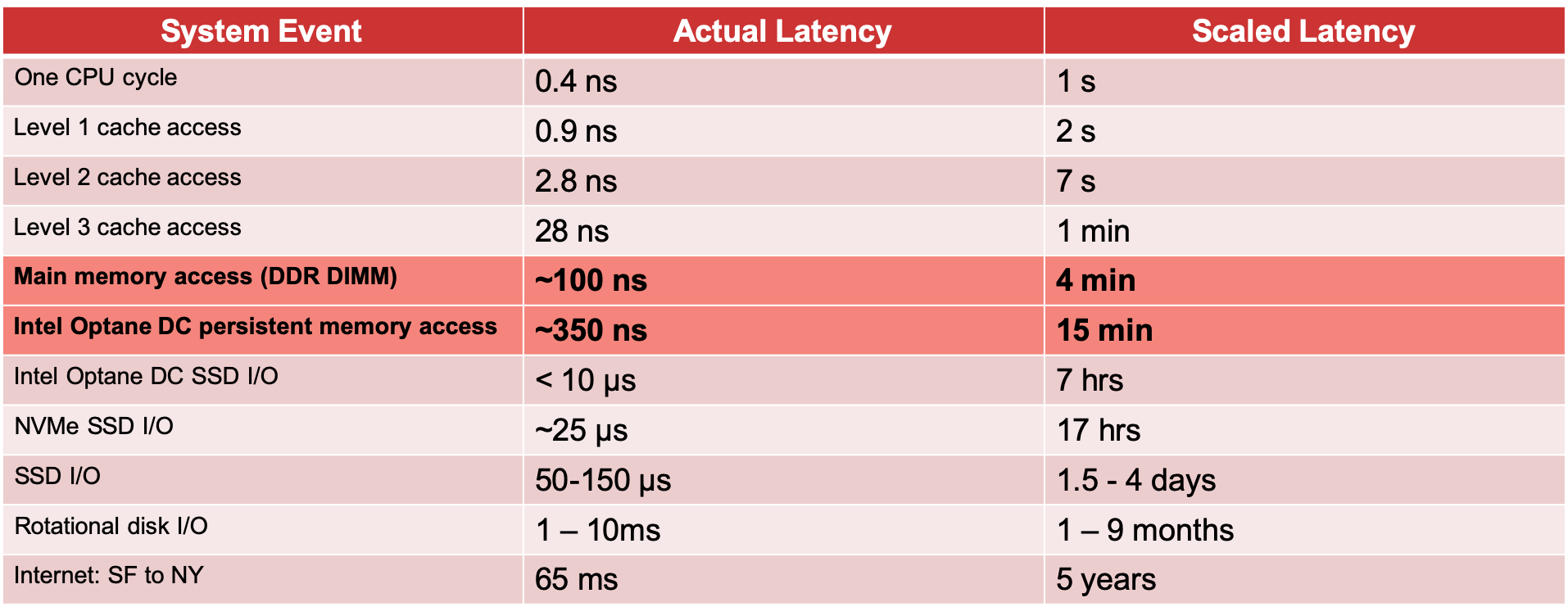
Figure 1. Computer Latency at Human Scale
There are two common solutions for standard Postgres deployments - shared buffer cache and generic OS Page Cache. The former caches data and indexes of relations, and Postgres fully manages this component, while the latter is provided by an operating system to all the applications and simply keeps pages/blocks of files in memory. Which one is better depends on the use case.
However, these caching techniques are adequate if Postgres is running on a single machine with enough RAM and there isn't any need to scale out. But once the data volume and load exceeds the capacity of even the most powerful machine, we'll be on the road to search for another solution. Well, we wouldn't have distributed in-memory databases if shared buffers or OS Page Cache were applicable for all scenarios.
Load balancing with Pgpool-II
Let's forget about advanced caching solutions for a brief moment and suppose that a single-machine Postgres cannot withstand the ever-growing load, which is a classical load-balancing problem.
Pgpool-II needs to be reviewed as the first possible option, especially if your use case is read-heavy. As shown in the picture, you need to deploy several Postgres instances, put them behind a Pgpool coordinator instance, and let it load balance queries.
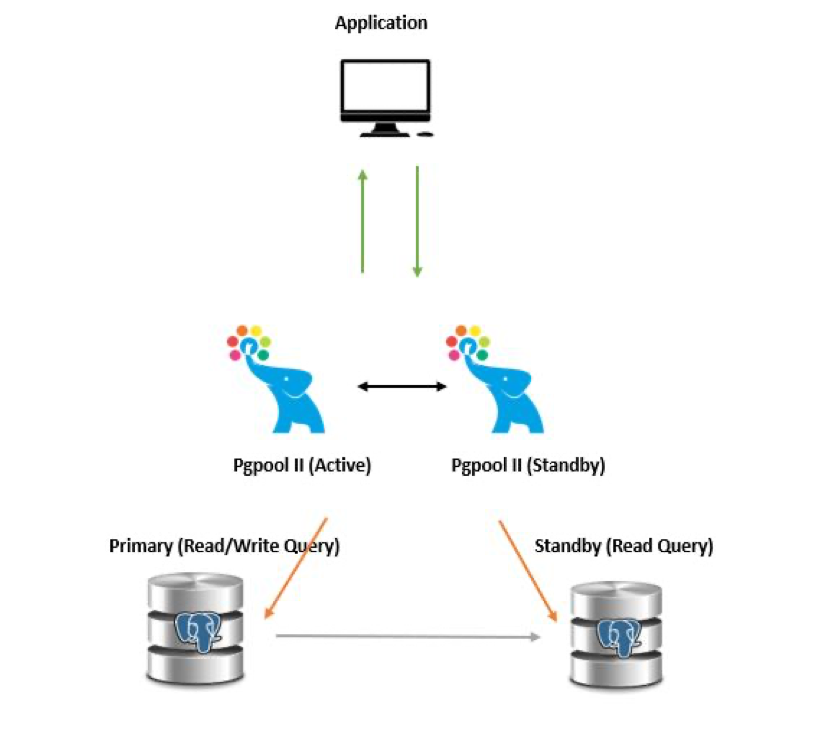
Figure 2. Load balancing with Pgpool-II
However, there are several points to consider and make your architectural checklist:
- The more replicas you have, the slower the updates. A primary database instance has to keep the slaves in sync. For many scenarios, the replication needs to be synchronous if ACID guarantees have to be preserved for the application regardless of the replica that will serve requests.
- Having a replica means that the useful capacity of the solution is bound by storage space available on the primary instance. For example, in a cluster with three replicas, even if each Postgres machine runs with 2 TB of disk, that is 6 TB in total, you cannot store more than 2 TB of unique data generated by the application. If you need to store more, you will need to allocate machines with more capacity.
So, how can we support write-heavy or mixed workloads with elastic and unlimited scalability? Let's review in the following section.
Scaling with Postgres-XL and Cloud Solutions
Sharding and partitioning allow Postgres to convert from a single-machine database into a pure distributed storage. Postgres-XL, CitusData and Azure Database for Postgres are among solutions that can distribute data evenly tapping into the whole storage space of the cluster, thus, supporting write-heavy and mixed workloads and, potentially, capable of storing unlimited sets of data.
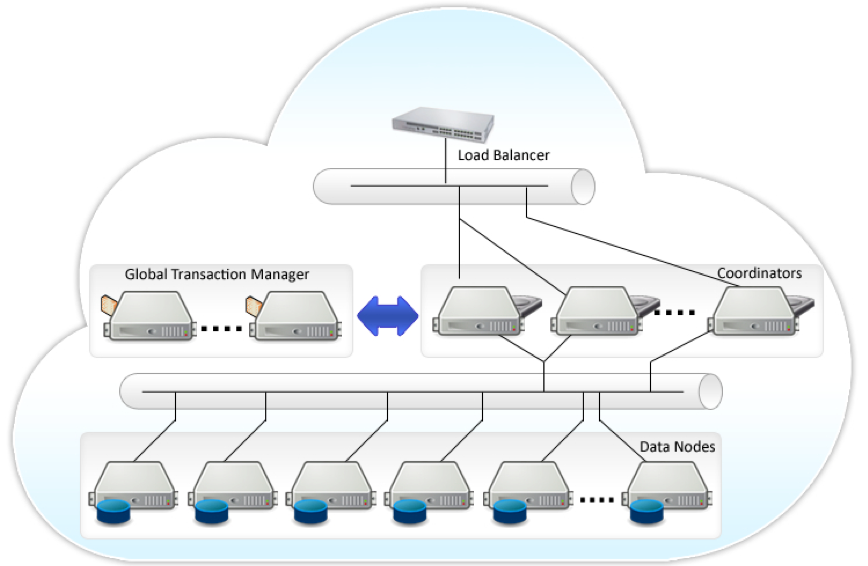
Figure 3. Postgres-XL Architecture
The architecture of such solutions doesn't vary significantly. Refer to the Postgres-XL architecture (Figure 3), which comprises data nodes that store distributed data sets, a coordinator that is aware of data distribution and processes requests of the applications, and global transaction manager that enforces transactional consistency across the cluster.
But even these solutions are not enough for all the usage scenarios. So what else is missing or needed? The answer is - memory. These solutions are still disk-based and although shared buffers and OS page cache can be enabled for every data node, such a configuration will be clumsy and hard to manage to ensure a consistent and predictable latency at scale.
Finally, let's talk about distributed in-memory stores that are designed for RAM and Intel Optane DC PM to ensure that we can tap into the full potential of distributed memory storage.
Caching and scaling with in-memory data grids
An in-memory data grid is a distributed memory store that can be deployed on top of Postgres and offload the latter by serving application requests right off of RAM. The grids help to unite scalability and caching in one system to exploit them at scale.
Apache Ignite and GridGain are one of the examples of such solutions that, as shown in the picture below, interconnect with Postgres and keep it in sync with the in-memory data set:
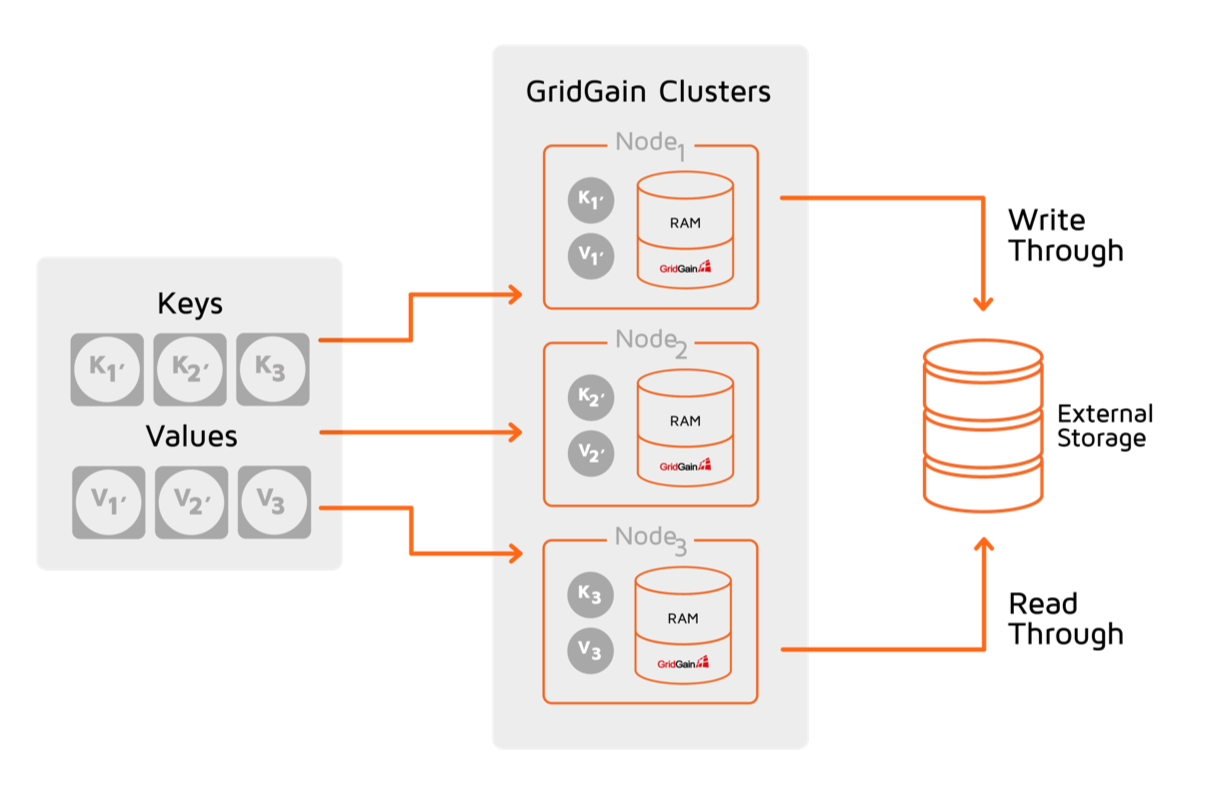
Figure 3. GridGain as In-Memory Data Grid
Ignite and GridGain partition data in a way similar to how Postgres-XL does with only one exception - the memory becomes your primary storage while Postgres is preserved as secondary disk storage. Both Ignite and Gridgain support unlimited horizontal scalability, SQL, distributed transactions, and more. You can literally store terabytes and petabytes of data in RAM.
In conclusion, let's sum up all the options discussed for boosting and scaling Postgres:
- Shared buffers and OS page cache are good for single-machine deployments as a way to exploit memory.
- Pgpool-II solves load balancing issues perfectly for read-heavy workloads.
- Postgres-XL and similar solutions turn Postgres into a distributed disk-based database for write-heavy and mixed workloads.
- Apache Ignite and GridGain, as in-memory data grids, let us go distributed and exploit memory at scale, preserving Postgres as disk storage. For more details on how to get-started with in-memory data grids for Postgres, see this webinar.