
Apache Ignite Deployment Patterns
The Apache Ignite® in-memory computing platform comprises high-performance distributed, multi-tiered storage and computing facilities, plus a comprehensive set of APIs, libraries, and frameworks for consumption and solution delivery (all with a “memory first” paradigm). This rich set of capabilities enables one to configure and deploy Ignite in many diverse system patterns. The platform can be used as a simple cache, an in-memory data grid (IMDG) that offloads an underlying relational database for the acceleration of web applications. It can function as a full-fledged, in-memory database that serves analytic and operational applications, thus functioning as an in-memory database (IMDB) with its own persistence tier. Finally, the platform can function as a digital integration hub (DIH) with its external system integration and compute and event-based processing in a fully integrated business system architecture.
Apache Ignite In-Memory Data Grid
In-memory data grid (IMDG) is the traditional “grid” solution. The solution is also known as “read-through/write-through caching strategy”. Data is loaded from and synchronized with a persistence layer that is ultimately responsible for durability and persistence of the data, as required by the business. This process is the classic “caching” pattern. However, with Ignite, one can use both the classic cache key-value paradigm or APIs and the relational or tabular SQL APIs to access the “cached” data.
Given a view that moves from consumers at the top to source data at the bottom, the Ignite IMDG slides in between to create a vertical data storage pattern, as shown in the following diagram:
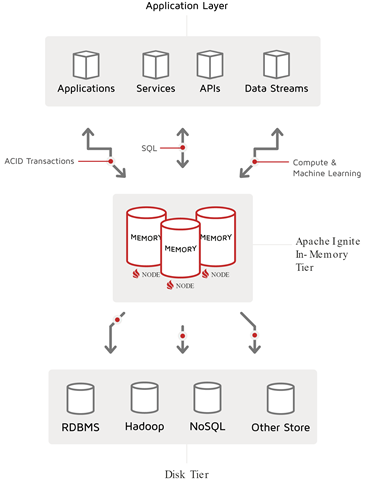
Apache Ignite In-Memory Database
With Ignite native persistence, an Ignite cluster can provide durable storage of cache or table data. Solutions can take responsibility for the lifecycle of the data (at least in this part of the data landscape):
- Data creation or data ingest
- Durable operation, with ACID level, transaction-based change management
- Data egress, or event-based data propagation
In addition to durability and resilience, support is provided for external data backup and restore, which handles cases of technical and business failures (for example, “Oops, we loaded the wrong trades in! Let’s restore to 7 am and run the correct trade import job.” See GridGain’s Data Snapshots and Recovery.)
A picture of the Ignite IMDB pattern is shown in the following diagram:
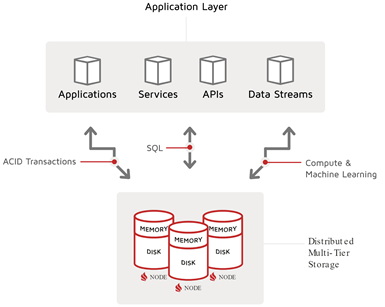
But… while Ignite with its durable storage and GridGain’s snapshots with PITR and data center replication can stand on their own, we know that, in the real world, data is not created in one place. By necessity, Ignite must integrate with external sources of data. This idea leads us directly to the final pattern we will discuss, the digital integration hub (DIH).
Apache Ignite Digital Integration Hub
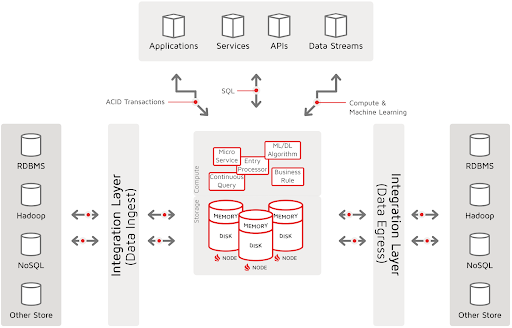
The digital-integration-hub (DIH) pattern does not originate from the in-memory computing world. Rather, it is a more complete system pattern that leverages the performance features of the Apache Ignite in-memory database (IMDB), plus integration facilities to ingest and egress data, and computing and event-processing facilities. At this nexus of data and computing, business rules are fired, machine-learning algorithms are calculated, and regressions and classifications are generated, thus producing actionable insights or events that other systems and system actors can act on.
The following diagram illustrates the Apache Ignite Digital Integration Hub:
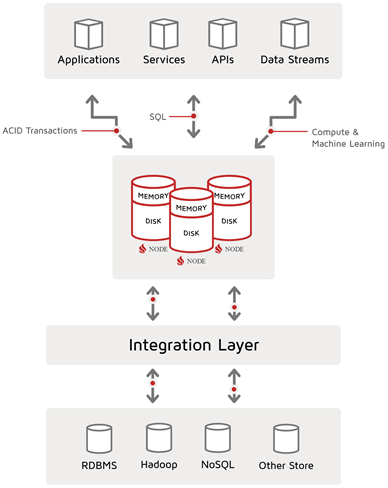
To this picture, one can add a distinction between data ingest and data egress. Then, if the source and target systems are included, a horizontal pattern is seen. In the horizontal data pattern, Apache Ignite is but one part of a broader data landscape, including operational source systems, external partners, and IoT devices. The horizontal-system landscape may also be segmented into technical data stages for technical consolidation, data landing, data quality and master-data management, and so on. Additionally, there are likely downstream systems that can take advantage of the powerful computing and analytic processing that Ignite delivers.
A simple refactoring of the original DIH diagram into a horizontal pattern is shown in the following diagram. This horizontal digital integration hub pattern will form the basis for my upcoming data-loading series:
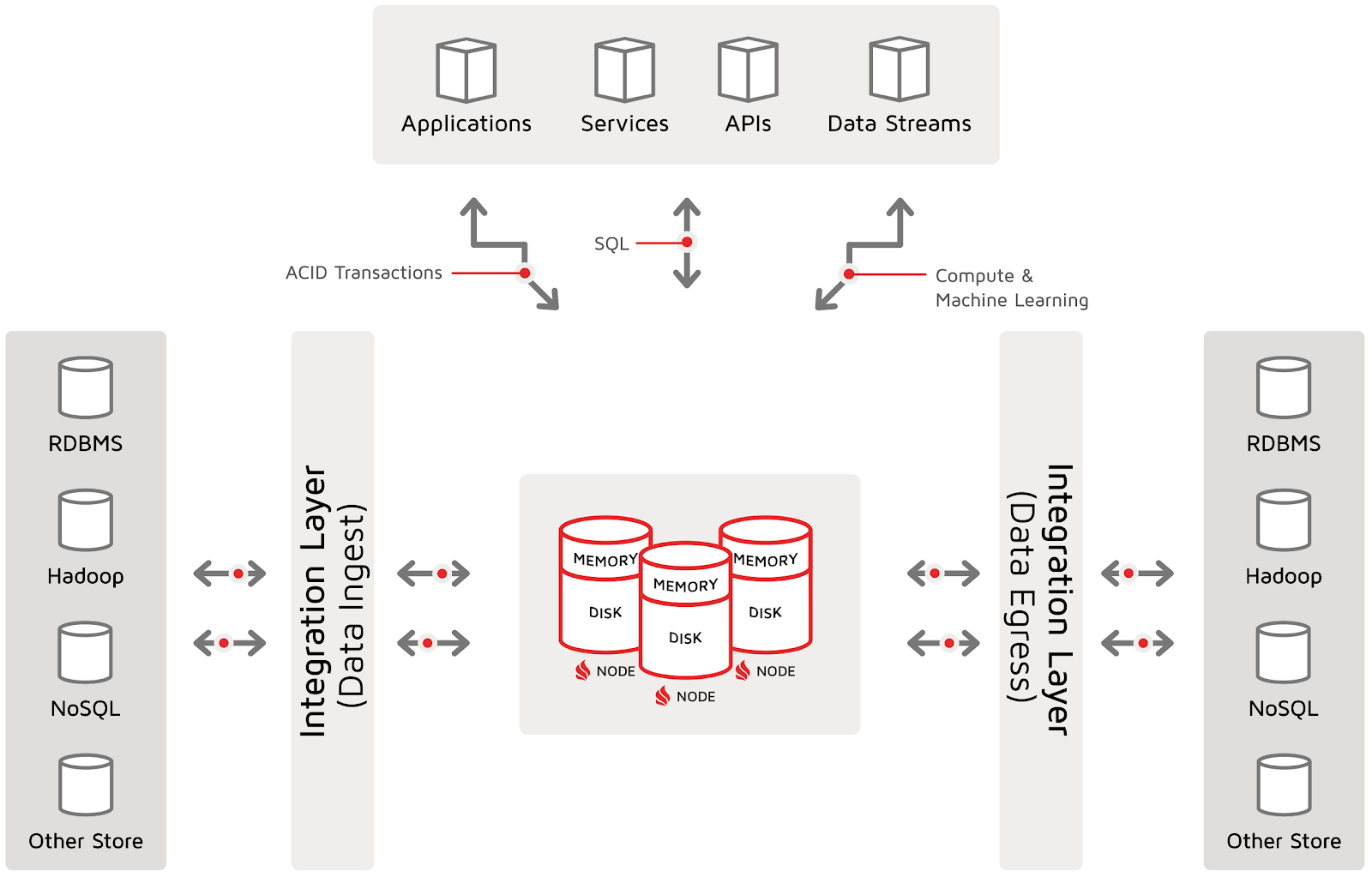
In this diagram, the DB (or, in Ignite’s case, the IMDB) is not responsible for, or characterized by synchronization with third-party systems for persistence. Instead, the DB (or IMDB) is responsible for all of the following:
- Durable operation: Ignite must responsibly hold the data in accordance with the quality of service contract for this part of the data landscape
- External integration: Ignite must integrate with prior and posterior systems. In this pattern, data flows from sources on the left to targets on the right.
Each stage in the data landscape has its own contract. This view resonates with our common experience in other areas:
- The data warehouse does not have the same performance guarantees or storage contracts as operational systems.
- IoT devices rarely persist data beyond a short temporal period (like 24 hours) and are used strictly to maintain state until data can be offloaded. Data can be flushed as soon as data delivery is performed.
- Business partners send CSV files to us but are rarely responsible for persisting those files, once the files are transferred to our systems.
Ignite Deployment Patterns: Data versusPlus Compute
In this article, we have mostly focused on the data landscape and how Ignite fits within or delivers various system patterns. However, it is important to note that a key feature of Ignite, especially as it relates to a digital integration hub (DIH), is its ability to deliver compute facilities at the hub. Especially important in the age of big data and real-time analytics is the ability to efficiently execute compute with the storage (what Ignite calls “co-located compute”). Here, knowledge of the data structure, locality, and indexing enables calculations, rules, services, algorithms, and complex events to effectively be processed where the data sits.
It is the ability to perform and detect interesting data events and to calculate or invoke business rules or machine-learning algorithms that enables the hub to generate business events and forward the events to interested parties or target systems. The following diagram of the DIH incorporates both the storage and compute capabilities at the hub:
Summary
In this article, we looked at three of the core patterns in which the Apache Ignite in-memory computing platform is deployed. We saw the in-memory data grid (IMDG), where Ignite synchronizes and “caches” data with a third-party system of record to deliver speed, scale, and potentially new API access to legacy and slower systems. We looked at the in-memory database (IMDB) that delivers not only the same speed and scale as the IMDG but also provides its own reliable storage and durable memory. The resilient operation of the IMDB does not need an external persistence store to “cache” or synchronize with. Finally, we saw how an IMDB like Apache Ignite can fulfill the pattern and objectives of the digital integration hub (DIH) and leverage the integration facilities to ingest data, to provide a central processing hub for calculation of business logic, and to generate events that flow to other target systems that may need to act on what happens in the hub.
Apache Ignite and its rich set of capabilities provides many deployment-pattern options. Many GridGain customers begin by using Ignite to improve the speed and scale of their data-centric interactions with existing data sources. But, then, they often progress to hybrid implementations that bring in the resilient operations of the IMDB and the integrated business-system landscape that is characterized by the DIH.