
Kafka with Debezium and GridGain connectors allows synchronizing data between third party Databases and a GridGain cluster. This change data capture based synchronization can be done without any coding; all it requires is to prepare configuration files for each of the points. Developers and architects who can’t yet fully move from a legacy system can deploy this solution to give a performance boost to their applications or allow applications to access data from multiple data silos into one place.
Introduction
There are several use cases of GridGain In-Memory Platform, powered by Apache Ignite™, where it needs to communicate with external databases like MySQL to exchange data updates between a GridGain cluster and another storage. Two such use case scenarios are database caching and digital integration hub.
With the caching use case, a GridGain cluster is deployed on top of an existing database. GridGain keeps the underlying store in sync with its write-through and write-behind capabilities. An application serves all the data from GridGain and uses the underlying database merely as a backup storage. GridGain, in turn, propagates all data changes transactionally to the database, thereby maintaining the consistency between these two layers.
With a digital integration hub scenario, applications have to read from and write to several backend databases as well as serve data from GridGain as a high-performance distributed store. In such a case, architects cannot rely only on GriGain’s built-in synchronization capabilities and turn to change data capture (CDC) frameworks to maintain data consistency between all the data silos.
Connect MySQL and GridGain With Debezium Change Data Capture
Debezium is a platform for change data capture that can connect to your databases and stream changes between them as well as applications. Currently, connectors for MySQL, MongoDB, PostgreSQL, PostgreSQL, SQL Server, and Cassandra are available for Debezium. You can use any of them, but in this article, we will use MySQL as an example.
Using Debezium and the GridGain Kafka connector, you can configure Codeless CDC - all you need to do is to prepare a few config files.
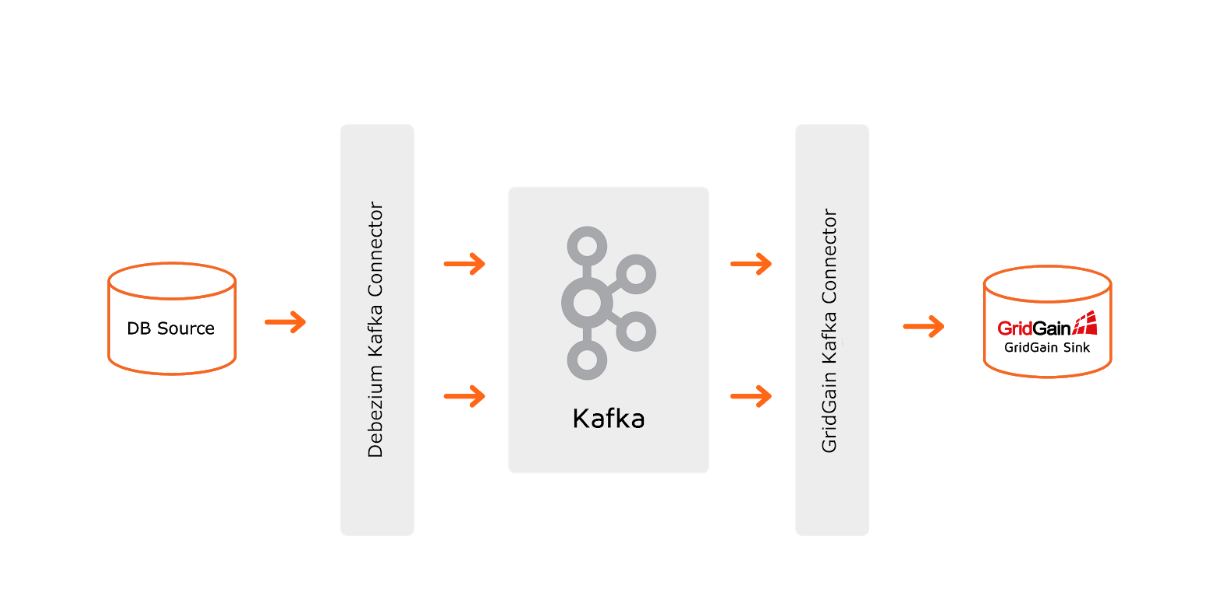
A working example that starts Docker containers for all components is here: https://github.com/GridGain-Demos/gridgain-mysql-debezium-demo.
This demo runs four containers:
- 2 GridGain cluster node containers
- 1 Kafka container with configured Debezium Source and GridGain Sink connectors
- 1 Mysql container with created tables
All containers run on the same machine, but in production environments, the connector nodes would probably run on different servers to allow scaling them separately from Kafka brokers. In this demo, they are co-located with the Kafka broker but this is just for simplicity purposes.
Synchronization can be checked using command line tools. Alternatively, you can use any of the other tools that you have or, if you want to use pre-installed GUI tools, you can start them using the start_tools.sh script. It contains a PhpMyAdmin image for MySQL and WebConsole for GridGain.
Prerequisites
- You have Docker installed. Please use this guide if you don’t have it yet: Get started with Docker
Start-up and verification
After cloning the repository with demo or downloading it, run start.sh (from the directory with demo) to build and run all docker images. This script downloads Kafka binaries and a Debezium connector if they’re not provided manually.
Now let's check the connection to the GridGain cluster and get the sizes of the tables. To do this, you can use SQLLine from the GridGain binaries if you have one on your computer. If you don’t have them, you can run it from the Docker container:
docker exec -it gridgain-node-1 /bin/bash
bin/sqlline.sh --verbose=true -u jdbc:ignite:thin://localhost:10800
!tables
jdbc:ignite:thin://localhost:10800> SELECT COUNT(*) FROM CITIES;
jdbc:ignite:thin://localhost:10800> SELECT COUNT(*) FROM COUNTRIES;To avoid starting a new container for the utility tool, let’s open a MySQL container and use the command line tool from MySQL binaries:
docker exec -it sql /bin/bash
mysql -ucdc_user -pcdc_passwd
mysql> use exampleAfter this, run the SQL script to insert test data.
Let’s return to SQLLine and run some commands to check that data was propagated from MySQL:
jdbc:ignite:thin://localhost:10800> SELECT * FROM CITIES;
jdbc:ignite:thin://localhost:10800> SELECT * FROM COUNTRIES;When you’re ready to stop all containers, run the stop.sh script.
Now let’s take a look at what you should pay attention to when configuring Debezium CDC for GridGain
MySQL
MySQL server should be prepared for binary logs record reading. Here is the documentation that describes how to do that:
MySQL Debezium Connector
Mysql Debezium Connector configuration example.
Now we are ready to install the MySQL source connector. For the basic steps, I recommend using the documentation.
The most significant part here is the configuration associated with the database itself - parameters with the prefix “database.”. When you are ready to run the connector with your database, make sure that the connection is properly configured. For demo purposes, there is no need to change anything because we are using preconfigured MySQL in this example.
GridGain Connector
GridGain Connector configuration example.
GridGain Connector starts a client node internally in order to connect to the cluster and put data there. To do this, all the required libraries should be added to the Kafka plugin directory. GridGain Kafka Connector quick start guide describes how to do this. At the same time, this example already contains the required libraries from GridGain 8.7.14.
To start a client node, we will also need to provide a GridGain client configuration file.
As you can see, the only thing that’s required there is a correct configuration for addresses of the server nodes in the cluster so that the client could connect to it.
GridGain Configuration
GridGain configuration example.
On the GridGain side, it is necessary to create tables to write the data received from Debezium into them. You can do this in 3 ways - CREATE TABLE, classes with annotations, and Query Entities configuration. The configuration of this example uses the Query Entities method.
Note that key and value types have names like dbServerName.databaseName.tableName.Key and dbServerName.databaseName.tableName.Value
Conclusions
As we saw, the Debezium and GridGain connectors allow no-code synchronizations between third party Databases and a GridGain cluster. I hope you were able to try the coding example above to get a concrete feel for the combined solution.