
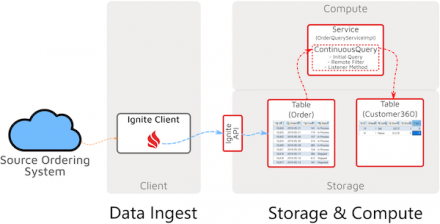
Using the initial-query, listener, and remote-filter features of Ignite continuous queries to detect, filter, process, and dispatch real-time events
(Note that this is Part 3 of a three-part series on Event Stream Processing.
GridGain Blog
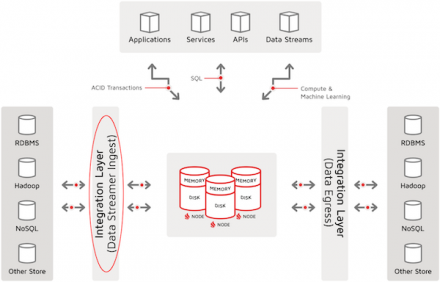
In this third article of the three-part series “Getting Started with Ignite Data Loading,” we continue to review data loading into Ignite tables and caches, but now we focus on using the Ignite Data Streamer facility to load data in large volume and with highest speed.
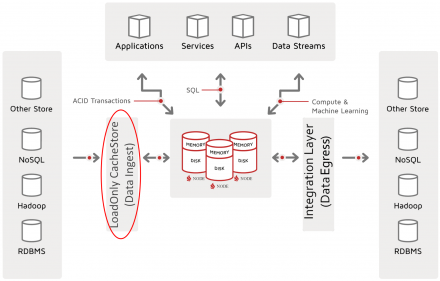
In this second article of the three-part “Getting Started with Ignite Data Loading” series, we continue our review of data loading into Ignite tables and caches. However, we now focus on Ignite CacheStore.
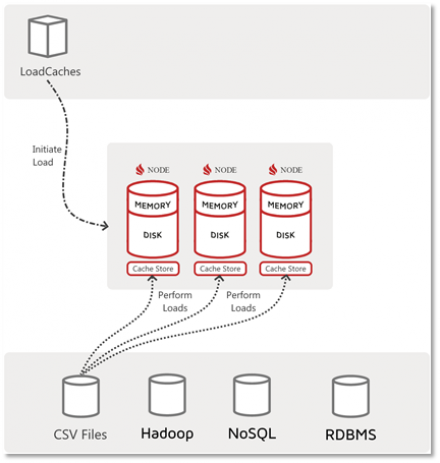
With this first part of “Getting Started with Ignite Data Loading” series we will review facilities available to developers, analysts and administrators for data loading with Apache Ignite.
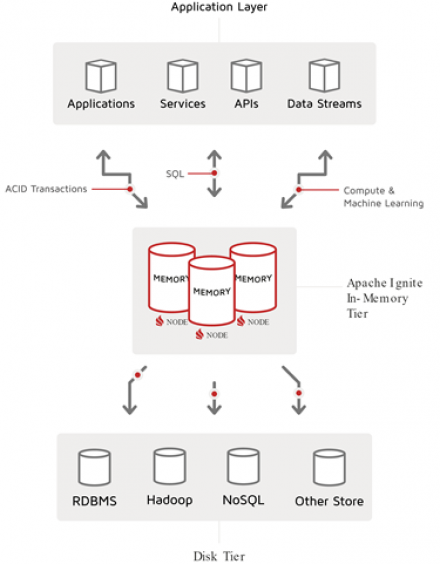
Apache Ignite Deployment Patterns
The Apache Ignite® in-memory computing platform comprises high-performance distributed, multi-tiered storage and computing facilities, plus a comprehensive set of APIs, libraries, and frameworks for consumption and solution delivery (all with a “memory first” paradigm).

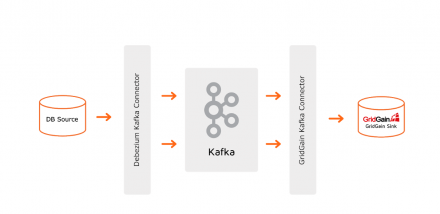
Kafka with Debezium and GridGain connectors allows synchronizing data between third party Databases and a GridGain cluster. This change data capture based synchronization can be done without any coding; all it requires is to prepare configuration files for each of the points. Developers and architects who can’t yet fully move from a legacy system can deploy this solution to give a performance…


When the Ignite project emerged in the Apache Software Foundation, it was thought of as a pure in-memory-solu


Apache Cassandra is one of the



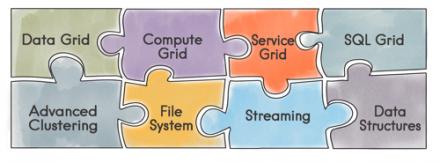
In this series of Apache Ignite Tutorial articles, I will describe what Apache Ignite is and how to deploy it at a beginner's level. In this first blog post, I will cover clustering and deployment.