
In my previous post I have demonstrated benchmarks for atomic JCache (JSR 107) operations and optimistic transactions between Apache Ignite™ data grid and Hazelcast. In this blog I will focus on benchmarking the pessimistic transactions.
The difference between optimistic and pessimistic modes is in the lock acquisition. In pessimistic mode locks are acquired on first access, while in optimistic mode locking happens during the commit phase. Pessimistic transactions provide a more consistent view on the data, given that, since locks are acquired early, you are guaranteed that no changes will happen to the data between transaction start and commit steps.
Yardstick Framework
Just like before, I will be using Yardstick Framework for the benchmarks, specifically Yardstick-Docker extension.
Transparency
One of the most important characteristics of any benchmark is full transparency. The code for both, Apache Ignite and Hazelcast benchmarks is provided in the corresponding GIT repos:
- https://github.com/yardstick-benchmarks/yardstick-ignite
- https://github.com/yardstick-benchmarks/yardstick-hazelcast/
Both, Apache Ignite and Hazelcast teams were given the opportunity to review the configuration and provide feedback.
Hardware
Both benchmarks were executed on 4 AWS c4.2xlarge instances used as servers and 1 AWS c4.2xlarge instance used as the client and the driver for the benchmark.
Benchmarks
In this benchmark we attempt to compare pessimistic cache transactions only. Both, Ignite and Hazelcast have many other features that you can learn more about on their respective websites.
The benchmarks were run in 2 modes, synchronous backups and asynchronous backups. In case of synchronous backups, the client waited until both, primary and backup copies were updated. In case of asynchronous backups, the client waited only for the primary copies to be updated and the backups were updated asynchronously. This was controlled with configuration properties of both products.
Also, in both benchmarks clients were allowed to read data from backups whenever necessary.
The code used for the benchmark execution is very simple and can be found on GitHub:
Apache Ignite: IgnitePutGetTxBenchmark
Hazelcast: HazelcastPutGetTxPessimisticBenchmark
Apache Ignite:
try (Transaction tx = ignite().transactions().txStart()) {
Object val = cache.get(key);
if (val != null)
key = nextRandom(args.range() / 2, args.range());
cache.put(key, new SampleValue(key));
tx.commit();
}
Hazelcast:
TransactionContext tCtx = hazelcast().newTransactionContext(txOpts);
tCtx.beginTransaction();
TransactionalMap<Object, Object> txMap = tCtx.getMap("map");
Object val = txMap.getForUpdate(key);
if (val != null)
key = nextRandom(args.range() / 2, args.range());
txMap.put(key, new SampleValue(key));
tCtx.commitTransaction();
Result:
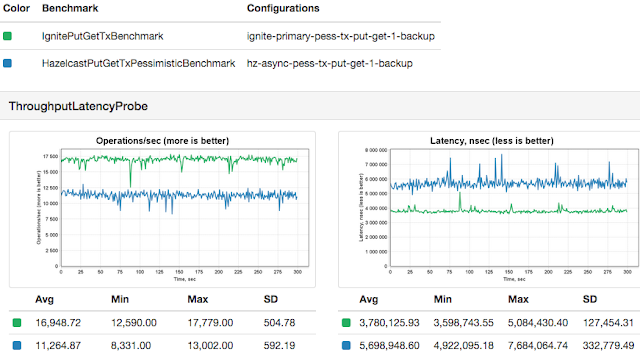
Just like with optimistic transactions, we found that in pessimistic mode, Apache Ignite data grid is about 44% faster than Hazelcast. Apache Ignite averaged approximately 16,500 transactions per second, while Hazelcast came in at about 11,000 transactions per second.
Here is a sample graph produced by Yardstick:
Also, when running Hazelcast benchmarks, the following exception kept popping up in the logs, which keeps me wondering about the consistency of the data cached in Hazelcast overall:
SEVERE: [172.30.1.95]:57500 [dev] [3.4.2] Lock is not owned by the transaction! Caller: fa705359-7154-4346-a5f2-292e1a2a75a5, Owner: Owner: fa705359-7154-4346-a5f2-292e1a2a75a5, thread-id: 105
com.hazelcast.transaction.TransactionException: Lock is not owned by the transaction! Caller: fa705359-7154-4346-a5f2-292e1a2a75a5, Owner: Owner: fa705359-7154-4346-a5f2-292e1a2a75a5, thread-id: 105
at com.hazelcast.map.impl.tx.TxnPrepareBackupOperation.run(TxnPrepareBackupOperation.java:48)
at com.hazelcast.spi.impl.Backup.run(Backup.java:92)
at com.hazelcast.spi.impl.BasicOperationService$OperationHandler.handle(BasicOperationService.java:749)
at com.hazelcast.spi.impl.BasicOperationService$OperationHandler.access$500(BasicOperationService.java:725)
at com.hazelcast.spi.impl.BasicOperationService$OperationPacketHandler.handle(BasicOperationService.java:699)
at com.hazelcast.spi.impl.BasicOperationService$OperationPacketHandler.handle(BasicOperationService.java:643)
at com.hazelcast.spi.impl.BasicOperationService$OperationPacketHandler.access$1500(BasicOperationService.java:630)
at com.hazelcast.spi.impl.BasicOperationService$BasicDispatcherImpl.dispatch(BasicOperationService.java:582)
at com.hazelcast.spi.impl.BasicOperationScheduler$OperationThread.process(BasicOperationScheduler.java:466)
at com.hazelcast.spi.impl.BasicOperationScheduler$OperationThread.doRun(BasicOperationScheduler.java:458)
at com.hazelcast.spi.impl.BasicOperationScheduler$OperationThread.run(BasicOperationScheduler.java:432)