
 |
Recently I have been doing many benchmarks comparing the incubating Apache Ignite™ (incubating) project to other products. In this blog I will describe my experience in comparing Apache Ignite ™ (incubating) Data Grid vs Hazelcast Data Grid.
Yardstick Framework
I will be using Yardstick Framework for the benchmarks, specifically Yardstick-Docker extension. Yardstick is an open source framework for performing distributed benchmarks. One of the best things about Yardstick is that it generates graphs at the end, so we can observe how the benchmark behaved throughout the whole execution.
Transparency
One of the most important characteristics of any benchmark is full transparency. The code for both, Apache Ignite ™ (incubating) and Hazelcast benchmarks is provided in the corresponding GIT repos:
On startup, Yardstick simply accepts the URL of a GIT repo as a parameter and executes all the benchmarks provided in that repository. This approach makes it really easy to change existing benchmarks or add new ones.In the interest of full disclosure, I should also mention that I am one of the committers for Apache Ignite project. However, to the best of my ability, I try to stay away from any opinions and simply state the discovered facts here.
Hardware
Both benchmarks were executed on 4 AWS c4.2xlarge instances used as servers and 1 AWS c4.2xlarge instance used as the client and the driver for the benchmark.
Benchmarks
Yardstick S3 functionality automatically adds benchmark results to the specified S3 bucket on Amazon S3 store. Moreover, if you run multiple sets of benchmarks, e.g. Apache Ignite and Hazelcast benchmarks, then Yardstick will automatically generate comparison graphs and store them in S3 bucket as well.
After some tweaking and tuning, here is what I found about Ignite and Hazelcast:
In this benchmark we attempt to compare Data Grid basic cache operations and transactions only. Both, Ignite and Hazelcast have many other features that you can find out on their respective websites.
After some tweaking and tuning, here is what I found about Ignite and Hazelcast:
- Both, Apache Ignite and Hazelcast, support distributed data grids (i.e. distributed partitioned caches). In short, they can be viewed as distributed partitioned key-value in-memory stores.
- Both, Apache Ignite and Hazelcast, implement JCache (JSR 107) specification
- Both are fairly easy to configure and introduce minimal dependencies into the project.
- Both have redundancy and failover. In the benchmarks, we configure both products with 1 primary and 1 backup copies for each key stored in cache.
- Apache Ignite and Hazelcast have different configuration properties, but it is possible to configure them in the same way for the benchmark.
- Both have support for ACID transactions. Ignite allows to set OPTIMISTIC or PESSIMISTIC mode for transactions, but I could not find the same in Hazelcast. I believe Hazelcast supports something close to OPTIMISTIC mode only.
- The querying capabilities of both products are very different. I will be benchmarking them in the nearest future and will describe them in my next blog.
Basic Atomic Operations
We compared basic puts and puts-and-gets into the cache.The code used for the benchmark execution can be found on GitHub:
Result:
We found that both Ignite and Hazelcast exhibit about the same performance with Ignite being about 4% to 7% faster on most of the runs.
Here are the graphs produced by Yardstick:


We compared basic transactional puts and puts-and-gets into the cache.
The code used for the benchmark execution can be found on GitHub:
Result:
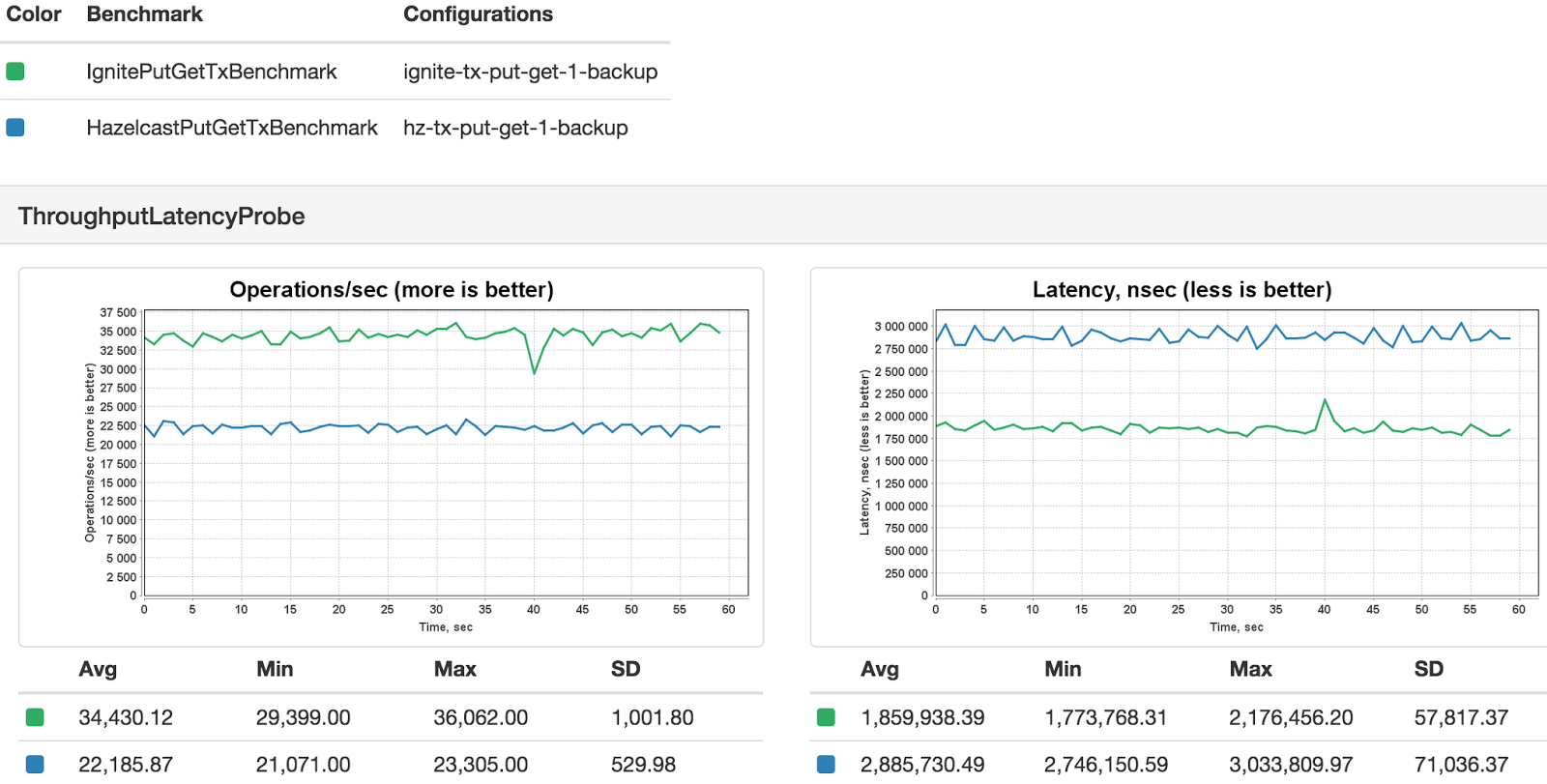
The performance difference for transactions was much bigger, with Ignite transactions outperforming Hazelcast transactions by about 35% to 45%.
Here are the graphs produced by Yardstick:

- Apache Ignite: IgnitePutBenchmark and IgnitePutGetBenchmark.
- Hazelcast: HazelcastPutBenchmark and HazelcastPutGetBenchmark.
Result:
We found that both Ignite and Hazelcast exhibit about the same performance with Ignite being about 4% to 7% faster on most of the runs.
Here are the graphs produced by Yardstick:
Basic Transaction Operations
We compared basic transactional puts and puts-and-gets into the cache.
The code used for the benchmark execution can be found on GitHub:
- Apache Ignite: IgnitePutTxBenchmark and IgnitePutGetTxBenchmark.
- Hazelcast: HazelcastPutTxBenchmark and HazelcastPutGetTxBenchmark.
Result:
The performance difference for transactions was much bigger, with Ignite transactions outperforming Hazelcast transactions by about 35% to 45%.
Here are the graphs produced by Yardstick:
In my following blogs I will compare the query performance of both products as well and will post my findings.
Try GridGain for free
Stop guessing and start solving your real-time data challenges: Try GridGain for free to experience the
ultra-low latency, scale, and resilience that powers modern enterprise use cases and AI applications.