Akmal B. Chaudhri

Position:
Technical Evangelist, GridGain Systems
Bio:
Bio:

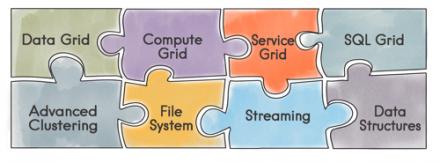
In this series of Apache Ignite Tutorial articles, I will describe what Apache Ignite is and how to deploy it at a beginner's level. In this first blog post, I will cover clustering and deployment.What is Apache Ignite?Apache Ignite is an in-memory data fabric. Its main goals are to provide performance and scalability. It partitions and distributes data within a cluster. The cluster provides very…