
With this first part of “Getting Started with Ignite Data Loading” series we will review facilities available to developers, analysts and administrators for data loading with Apache Ignite. The subsequent two parts will walk through the two core Apache Ignite data loading techniques, the CacheStore and the Ignite Data Streamer.
We are going to review these facilities in relation to specific Apache Ignite deployment patterns as documented here. As we describe below the different loading facilities have their benefits and costs and this may lead one to use one facility over another.
Apache Ignite Data Loading Facilities
In this article we are going to discuss the facilities available to Ignite for the above External Integration, and in particular loading from external systems. Ignite provides a number of facilities that can be brought to bear to deliver or load data from external, source systems.
Cache Store
The CacheStore is the primary vehicle used in the Data Grid (IMDG) scenario for synchronizing with external, or 3rd party persistence stores. The Ignite CacheStore interface implements the Cache Read-Through and Write-Through features of the Cache with its underlying source. Additionally Ignite’s CacheStore interface has a Cache Load method that is used for hot-loading the cache at initialization time (though it is not limited to init-time execution). A pictorial representation of the API-Cache-CacheStore-DataStore relationship is shown below, highlighting the read-through, write-through and cache-load functionalities:
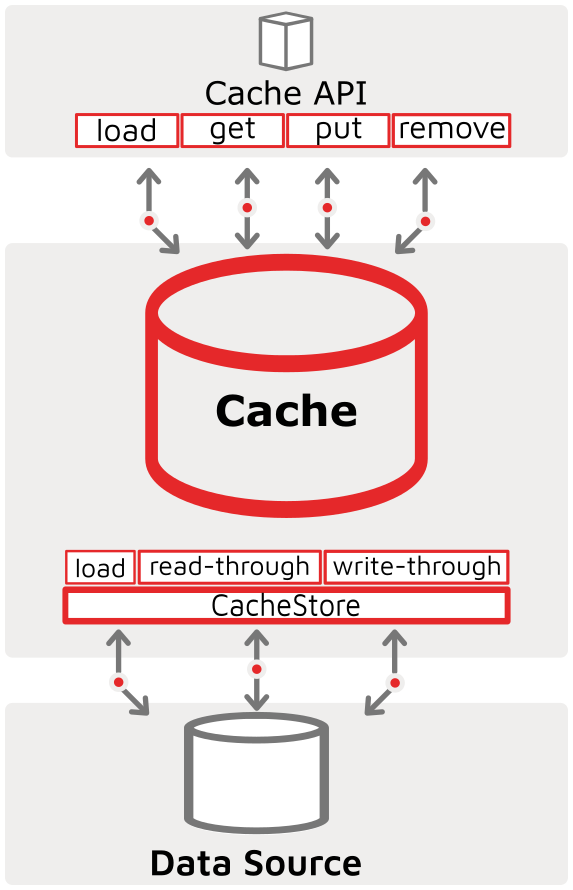
Ignite has quite a few implementations of the CacheStore interface to synchronize Ignite caches with external systems like RDBMS, Hibernate, NoSQL systems like Cassandra and other custom 3rd party systems. These implementations will ensure that any Create (cache put new or SQL insert) or, Update (cache put, SQL update) or Delete (cache remove, SQL delete) changes from KeyValue or SQL APIs will be synchronized down to the 3rd party system. It also provides a vehicle for the cache to be hot-loaded with data from the data source.
It is this last, cache load interface that we will be reviewing in our article Getting Started with Ignite Data Loading - Part 2: CacheStore Loading.
Data Streamers
As we see on the Ignite Data Loading & Streaming page, the IgniteDataStreamer API and streamers using it are “... built to inject large amounts of continuous streams of data into Ignite stream caches. Data streamers are built in a scalable and fault-tolerant fashion and provide at-least-once-guarantee semantics for all the data streamed into Ignite.”
Ignite comes out of the box with a collection of pre-build data streamers for many systems you may already use, like Kafka, JMS, MQTT, and others.
put / putAll /SQL Insert APIs
A normal part of business and technical applications interacting with an Ignite cache/table is the cache put/putAll and the SQL API and these are perfectly amenable to storing data into the cache. While the putAll API is significantly faster than multiple puts, these both pale next to the DataStreamer interface and its ability to load data at speed.
Data loading through these API’s would generally be used for incremental data loading and be handled with a specialized or custom loading application, and will not be discussed as part of this general data loading topic. This general topic has a bias towards the bulk data loading that targets full or bulk load routines with large volumes.
The SQL API supports integrated streaming with its SET STREAMING [ON|OFF] option. In this scenario SQL INSERTS will be batched together by the JDBC/ODBC driver and executed asynchronously across the full collection of cluster nodes for maximum throughput.
Tools / Applications
With the breadth of Ignite’s APIs, including common interfaces like JDBC/ODBC, there are many tools available that can be used to load data into Ignite. Ignite also ships with one of these tools, SQLline that supports the Ignite SQL COPY from file INTO TABLE command:

Other ETL tools like Informatica and Talend are also great tools for loading into Ignite via ODBC/JDBC. As with the put/putAll cache and SQL APIs, we will not be discussing these options for loading data into Ignite.
Data Load Flow
When using Ignite with its thick Client and Server APIs, there are two primary data loading flows:
Client Passes Data to Server
By most people, this will be considered the standard data loading flow where the agent performing the load has access to and reads or gets the source data and IT writes that data to the database (i.e. the Ignite Server Nodes / Cluster). A diagram of this data load flow pattern is shown below:
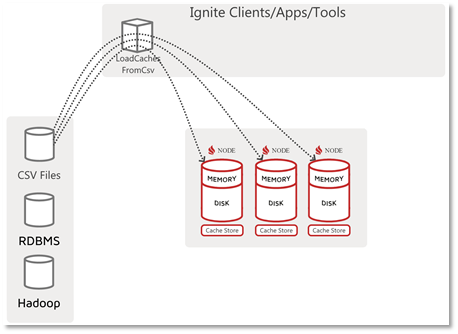
In the above diagram we have an Ignite Client application written for a particular data source (in this case CSV files, so it is named “LoadCachesFromCsv”) and it knows how to reach out and get or receive the data. This application then also performs the writing or “loading” of the data into the cluster. In this data load flow, one could use any of the Ignite write APIs, put(), putAll(), SQL Insert, etc., but this is where the Ignite DataStreamer would be most applicable and deliver the fastest load performance.
Client Signals Server to Load Data
An alternate data load flow is one where the client merely tells the server to load the data (maybe with an argument to indicate what or where to get it). A diagram of this flow is shown below:
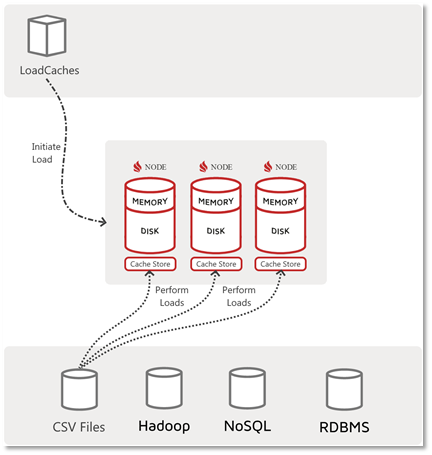
As we see above, the “LoadCache” application merely “initiates” the load, but in fact, the actual loading logic and data movement happens at, to/from the cluster/node resident CacheStore.
Data Load Flow Comparison
Of the two load flows (client-based data loading and client signalled, server data loading) we see that in the first pattern the client takes all responsibility AND its context, data access, security, network visibility, etc. is in force relative to the source data. This may be a benefit as only the client node need have access to the data and may act as a proxy between the source system and the target cluster, shielding the cluster from direct outside access. However, when the client performs the load, it must read ALL the data itself and write to the cluster (which might also need to re-distribute the data to the correct target node).
Alternatively a client signalled, but server executed data load CAN take advantage of the power and context of the server cluster. Here the cluster nodes may be the only agents in the network that have been configured for connectivity and security to reach the source data. Also, IF the data and target data partitioning is amenable to co-located loading, we can split the load by node and load only the data for the partitions resident on each node. This gains massive scalability benefits (i.e. each node handles its piece and this horizontally scales out for all nodes). For a more thorough description please see the partition-aware loading documentation. Note, if partition-aware loading is not possible or not implemented, there is a duplication of data read IO as each node will read ALL data and throw out those records not applicable to the local node.
In the next two parts of this “Getting Started with Ignite Data Loading” series we will build examples for both of these two types of Ignite data loaders.