GridGain Blog


Those who're keeping an eye on the realm of distributed systems should have mentioned that Apache Ignite community announced an absolutely new grid component as a part of the latest 1.8.0 release - In-Memory SQL Grid. The ability to query data with ANSI-99 SQL queries existed a long time ago in Apache Ignite. But that wasn't a finish line and now Apache Ignite users can both query and modify…


The number of smart devices making up the Internet of Things (IoT) has soared. From traditional printers and scanners to refrigerators, from smart watches and clothing to self-driving cars and drones, Gartner expects the IoT to include over 20 billion connected things by 2020. With all these connected devices transmitting information that needs to be analyzed, companies will need to deploy data…

Distributed In-Memory SQL Queries in Apache® Ignite™ Webinar Recap
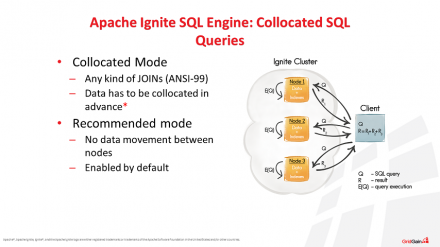
Apache® Ignite™, the foundation of the GridGain in-memory computing platform, contains an in-memory SQL engine that is fully ANSI-99 compliant. This means that developers don’t have to rewrite existing SQL queries to take advantage of the performance and scale offered by Ignite. There is a significant performance gain running SQL…


While most applications use distributed in-memory caching for fast data access, they heavily rely on relational databases for data persistence purposes. For such applications, Apache Ignite supports read-through and write-through modes to read/write the data from/to the underlying persistent store, respectively. Moreover, Ignite can import database schemas and automatically generate all the…

Join us on Wednesday, November 30, 2016 at 11:00 AM PDT/2:00 PM EDT for a webinar discussing tuning Apache® Ignite™ and GridGain for optimal performance with Valentin Kulichenko, Lead Architect at GridGain Systems.
Distributed in-memory computing systems such as Apache Ignite can be used to improve the performance and scalability of data-driven applications. Distributed systems, though, depend…

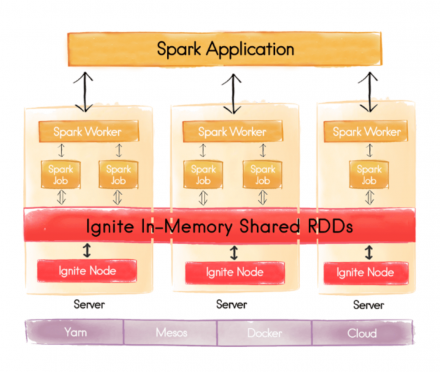
On November 17th, one of our European GridGain Systems' consultants visited Madrid to present a paper at Big Data Spain entitled “Better Together: Fast Data with Apache Ignite & Apache Spark”. The Big Data space has been growing rapidly over the past few years, with disk-based Hadoop systems and then hybrid disk and memory systems such as Apache Spark gaining significant mindshare.…
When securities prices move, trading firms can make more money the faster they react. High-frequency securities trading is now the norm and financial services firms are incentivized to maximize the performance of their high-frequency trading infrastructure. Performance plays a critical role in each basic step of high-frequency securities trading, including obtaining market information, processing…
Nowadays, there are tons of applications, services and use cases when it's needed to gather, store and process spatial data constantly. Generally speaking, when we talk about geospatial data, we imply location or dimension of an object like a building, mountain, car or group of people. Applications and services like Foursquare and Google Maps or solutions built for logistics and…
Banks and other financial services firms face a slow economic recovery, pessimistic economic forecasts worldwide, demands to improve their balance sheets, and more. As a result, banks are cutting costs, restructuring, optimizing business lines, and exiting less profitable activities – all while under pressure to satisfy new compliance regulations designed to protect against another economic…
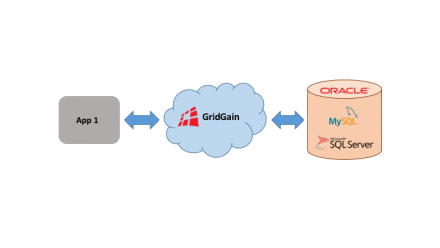
Almost any In-Memory Data Grid (IMDG) solution available can be used as-is without an underlying persistent storage layer. Based on my experience, there are different use cases and real production scenarios when the entire data set is fully located in an IMDG and it is not synced to disk at all.
However, in a variety of deployments, companies still prefer to keep data both in memory and…