
On November 17th, one of our European GridGain Systems' consultants visited Madrid to present a paper at Big Data Spain entitled “Better Together: Fast Data with Apache Ignite & Apache Spark”. The Big Data space has been growing rapidly over the past few years, with disk-based Hadoop systems and then hybrid disk and memory systems such as Apache Spark gaining significant mindshare. Whilst Apache Spark focuses on the analytical/machine-learning end of the Big Data world, Apache Ignite is primarily used for high-performance transactional data storage and grid-computation. So what common ground can these two very different products have?
Check our our blog on Apache Ignite vs Apache Spark: Integration using Ignite RDDs for further information.
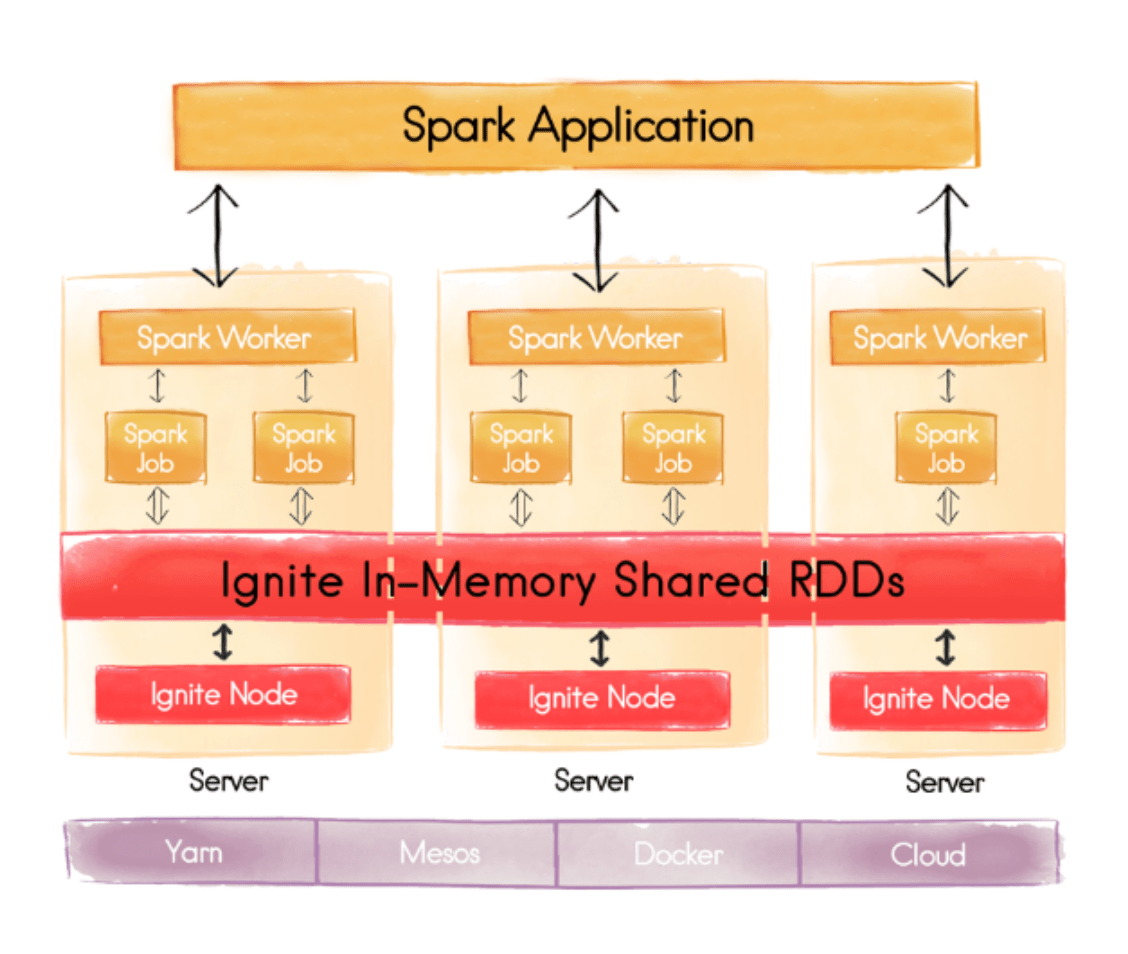
Apache Spark stores its data within Resilient Distributed Datasets, or RDDs. An RDD is an immutable, read-only, partitioned collection of records that exists in memory, and can also spill over to disk. By adding Apache Ignite to your Spark cluster, you gain three significant pieces of functionality:
- You can bypass the read-only restriction of Spark’s RDD and mutate the underlying data
- You can index your Spark data for incredibly fast SQL queries
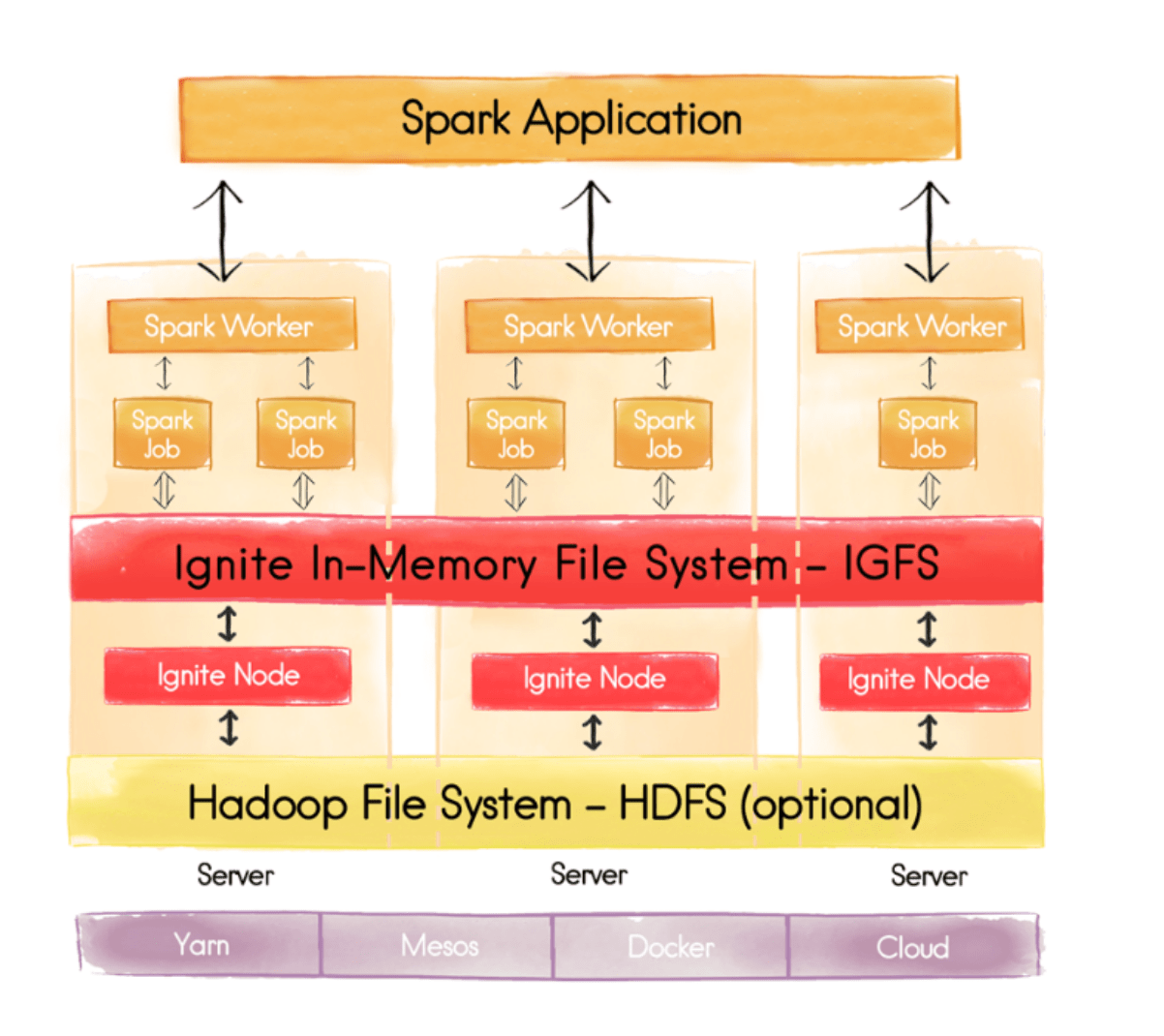
- You can harness the power of the Apache Ignite In-Memory File System, IGFS.
Apache Ignite RDDs can also live outside the lifetime of the Spark jobs and workers, in their own cluster. This can significantly improve the start-up time of a Spark cluster in the case of a restart being required.
Mutable RDDs
Spark RDDs are read-only in order to simplify the reasoning of multiple threads accessing the underlying data in parallel. The Ignite RDD lifts this restriction, and allows data to be updated during each task execution or job. The Ignite cache can be used to allow external applications and other Spark jobs to be notified of changes, and to read the state of the RDD.
Faster SQL queries with Apache® Spark™
Apache Spark supports SQL queries, but it must perform full scans each time a query is executed. This means that Spark queries may take minutes, even on relatively small data sets. In contrast, Apache Ignite can index data in the RDD, giving 1,000x improvements in Spark SQL query performance.
IGFS
The Apache Ignite File System (IGFS) is an implementation of the Hadoop HDFS interface, and can be plugged in natively to any Apache Hadoop or Apache Spark environment. It gives an immediate performance improvement for Hadoop or Spark, without any code changes.
General Conference Themes
Two significant themes arose at the conference as being big things for both 2016 and going forward into 2017 and beyond. The first is streaming, with Apache Spark’s streaming being mentioned in multiple sessions. Apache Ignite can help accelerate Apache Spark with both Apache Ignite's lightning-fast in-memory SQL database and support for Continuous Queries giving Complex Event Processing (CEP) capabilities out of the box.
The second theme was DevOps, environment management, and getting systems into production. It was very pleasing to be able to tell conference attendees that Apache Ignite is compatible with all of the major cloud computing providers, such as Amazon Web Services, Google Cloud and Microsoft Azure, and compatible with many container and deployment technologies, including Apache Mesos, Karaf, YARN and Docker.
Overall it was a successful conference, and great to get out and mix with existing users, potential users, and other companies in the data space.