
Distributed In-Memory SQL Queries in Apache® Ignite™ Webinar Recap
Apache® Ignite™, the foundation of the GridGain in-memory computing platform, contains an in-memory SQL engine that is fully ANSI-99 compliant. This means that developers don’t have to rewrite existing SQL queries to take advantage of the performance and scale offered by Ignite. There is a significant performance gain running SQL queries in Ignite because they are run in a distributed fashion.
In order to accomplish this, Apache Ignite leverages several components from the open source Java-based H2 Database. H2 Database is a fast in-memory and disk-based database engine. Apache Ignite’s SQL engine uses components from the H2 Database SQL such as the query parser and optimizer, the query execution planner, and the indexing module. All the indexes and data are stored inside Ignite’s in-memory data grid. When SQL queries are submitted to Apache Ignite, Ignite calls H2 to parse and plan the query, then H2 hands the query over to Ignite to run it.
SQL Query Execution Flow in Apache Ignite
When an application executes a SQL query, the query is sent through the Apache Ignite client node (think of this as a software gateway to the Ignite cluster) to all the Ignite server nodes in a cluster that store the data being queried. As each server node receives the query, the node executes the query over the local data set and returns partial results to the Ignite client node. The Ignite client node then assembles the partial results from the Ignite server nodes and returns it to the application.
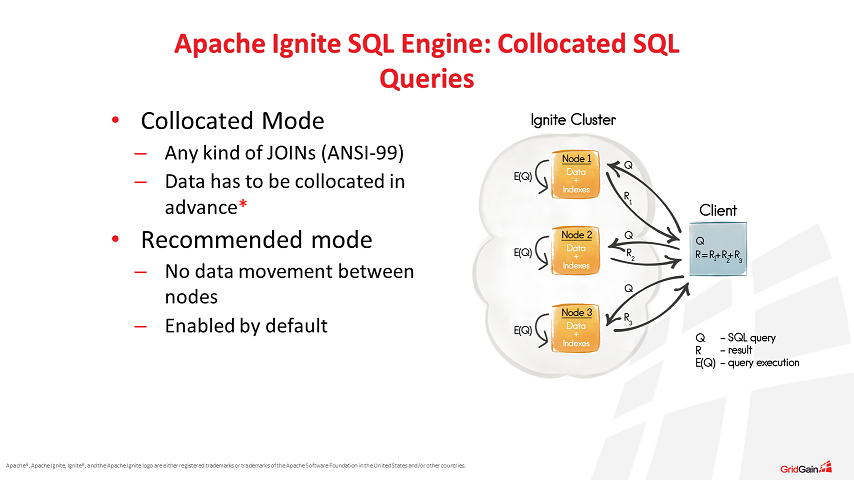
Apache Ignite supports distributed SQL queries over collocated and non-collocated data, with collocated being the default. Collocated data, like in the example above, results in the most performant SQL queries. However, it is not always possible to collocate all the data in a single cache on a single node. In order to address this possibility, Apache Ignite version 1.7 introduced non-collocated SQL query mode whereby additional requests are sent between nodes in the cluster to ask for the missing data. Data is then pushed between nodes, combined, queried, and results are sent to the client node for presentation to the application.
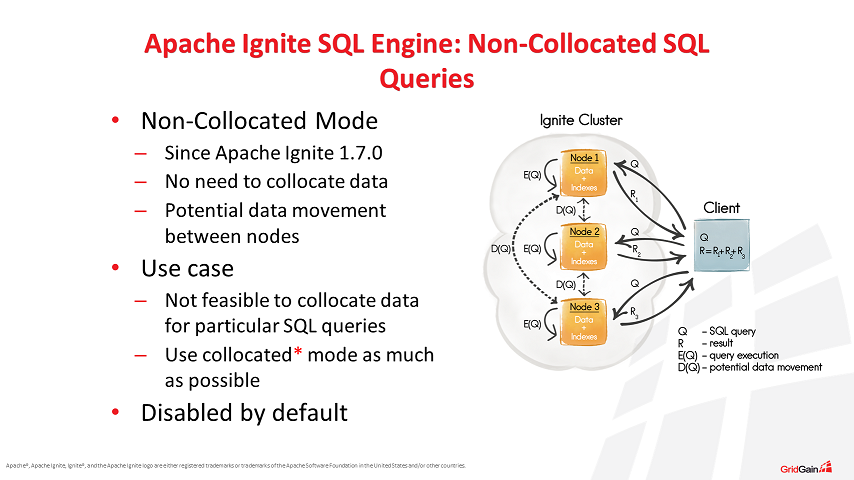
As you can imagine, asking for and pushing data between server nodes presents performance challenges. This is the reason that we recommend a collocated data approach wherever possible.
Apache Ignite APIs
The Apache Ignite SQL engine provides unified multi-language APIs for Java, Scala, .NET, and C++. When using other programming languages, it’s possible to connect using JDBC or ODBC drivers.
Tips for Better Distributed In-Memory SQL Queries in Apache Ignite
- Set up indexes in advance to return SQL query responses quickly.
- Create group indexes when operating on multiple individual indexes
- Be comprehensive in indexing but don’t go overboard. Too many indexes slow Ignite cache updates.
- Collocate data wherever possible to avoid additional data movement between nodes.
- If the performance of your SQL query is not satisfactory, then double check that the execution plan relies on the appropriate indexes. You can do this using the EXPLAIN statement.
- To further troubleshoot SQL query performance, use the free GridGain Web Console to execute and monitor queries over your cluster.