
Those who're keeping an eye on the realm of distributed systems should have mentioned that Apache Ignite community announced an absolutely new grid component as a part of the latest 1.8.0 release - In-Memory SQL Grid. The ability to query data with ANSI-99 SQL queries existed a long time ago in Apache Ignite. But that wasn't a finish line and now Apache Ignite users can both query and modify data relying on good-old SQL statements like SELECT, UPDATE, INSERT or DELETE. Even more, we're free to do it from every tool or programming language that works with JDBC or ODBC drivers.
There is a quick guide on Apache Ignite site that explains how to use PHP with SQL Grid. In addition, the guide includes simple SQL queries for reference. As a part of this blog post I want to provide an advanced PHP example that will show:
- How to setup several Apache Ignite caches and collocate their data both at the configuration and code level.
- How to fill in caches with data.
- How to query data using both simple queries and queries with collocated JOINS.
The whole source code is provided on GitHub. Below you'll find a walk-through of the examples.
Prerequisites
The following initial steps have to be completed before we walk-through the example:
- Download Apache Ignite 1.8.0 and build the ODBC driver.
- Set up ODBC DSN on a target system.
- Install PHP environment and enable PHP PDO for it.
We're not going to cover these steps under this blog post as we've already covered this in the original Apache Ignite PHP guide. So, please go ahead and complete those steps on your own.
The only thing to note is ODBC DSN configuration requirements for the purpose of the example. When you get to this point make sure to set all the parameters to the values you see in the picture below.
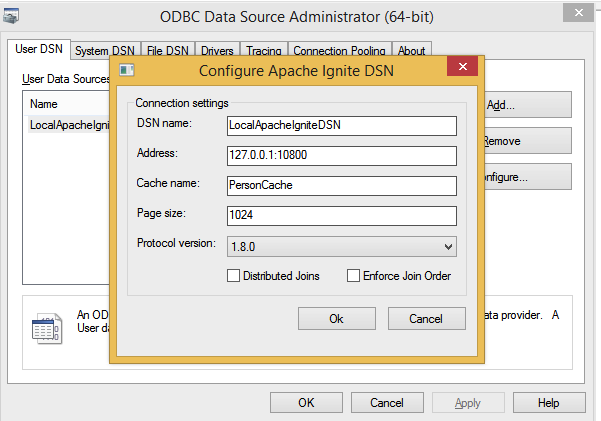
The "DSN name" parameter's value will be used from the PHP code at the connection time and "Cache name" value will be treated as default schema name (cache name) on the SQL Grid side. The definition of the rest of the parameters can be found in Apache Ignite's ODBC documentation.
Cluster Configuration and Start
The cluster configuration, available as a part of the example, is located under the following path "IgnitePhpExample/config/ignite-cluster-config.xml". Use it as a configuration for your Apache Ignite cluster nodes.
Start at least one Apache Ignite node using a command similar to the one below:
{apache_ignite_1.8.0_path}/bin/ignite.bat {path_to_the_example}/IgnitePhpExamle/config/ignite-cluster-config.xml
Use ignite.sh if you're on a Unix machine.
Let's review some of the configuration parameters that are relevant to our example.
ODBC Processor
<property name="odbcConfiguration">
<bean class="org.apache.ignite.configuration.OdbcConfiguration"/>
</property>
The processor has to be explicitly activated in the configuration. The ODBC driver communicates to the cluster over it. The address that we're set above in the DSN configuration window includes the port where the processor listens to incoming connections and requests.
Query Entity
<bean class="org.apache.ignite.cache.QueryEntity">
<property name="keyType" value="java.lang.Integer"/>
<property name="valueType" value="Person"/>
....
</bean>
A query entity is a special gateway object in between Data Grid and SQL Grid in Ignite. Essentially, it tells SQL Grid what type of objects (key-value pairs) are stored in a concrete distributed cache and the SQL engine will leverage this information in runtime when it needs to index, query or modify the data set.
In the code snippet above we inform SQL Grid that there is a key of Integer type and a value of Person type stored in the cache. The name of the value type (Person) will be used as a table name in SQL statements.
Furthermore, we don't need to create a Java POJO class for Person. Platform's BinaryMarshaller will be able to construct Person for us on the fly. What we need to do is to list all the fields that are supposed to be used in SELECT and DML (INSERT, UPDATE, etc.) queries so that BinaryMarshaller knows how to properly construct new objects and the SQL engine is aware of all the fields that might be accessed and indexed. The fields of Person type are listed under fields property as it's shown below:
<property name="fields">
<map>
<entry key="firstName" value="java.lang.String"/>
<entry key="lastName" value="java.lang.String"/>
<entry key="age" value="java.lang.Integer"/>
<entry key="address" value="java.lang.String"/>
</map>
</property>
Affinity Collocation and Custom Keys
In addition to Persons, we're going to store Vehicles in the cluster in their own cache. Moreover, we want to make sure that Vehicles will be collocated with their owners (Persons). In other words, we want to be sure that all the Vehicles that belong to a specific Person reside on the same node. This will allow executing SQL queries with JOINs in the collocated mode.
To achieve this we need to go through several steps at the configuration level.
First, we will define a custom key type for Vehicles and will set it in the corresponding query entity. The name of the new type is VehicleKey.
<bean class="org.apache.ignite.cache.QueryEntity">
<property name="keyType" value="VehicleKey"/>
<property name="valueType" value="Vehicle"/>
...
</bean>
Second, all the VehicleKey's fields have to be added to fields property of the query entity
<property name="fields">
<map>
<!-- These are fields stored in the key. -->
<entry key="vehicleId" value="java.lang.Integer"/>
<entry key="personId" value="java.lang.Integer"/>
<!-- Below are fields stored in the value -->
...
</map>
</property>
and be listed in keyFields property.
<property name="keyFields">
<set>
<value>vehicleId</value>
<value>personId</value>
</set>
</property>
After this is done, key's fields can be directly referenced from SQL statements.
Third, to enable the affinity collocation in between Persons and their Vehicles, personId field must be set as an affinity key of VehicleKey. This will ensure that all the Vehicles with the same personId will be stored on the node where the Person 's record is placed.
<bean class="org.apache.ignite.cache.CacheKeyConfiguration">
<!-- Passing key's type name. -->
<constructor-arg value="VehicleType"/>
<!-- Passing the name of the field which will be the affinity key. -->
<constructor-arg value="personId"/>
</bean>
Finally, since the keys will be generated on the fly, BinaryMarshaller has to be instructed how to calculate the hash code and execute the equals method for our custom key type. There are several ways to accomplish this and we will rely on BinaryFieldIdentityResolver which will use the values of personId and vehicleId fields.
<bean class="org.apache.ignite.binary.BinaryFieldIdentityResolver">
<property name="fieldNames">
<list>
<value>vehicleId</value>
<value>personId</value>
</list>
</property>
</bean>
PHP Access
Assuming that the cluster nodes are started with the configuration elaborated above, we're ready to connect to the cluster from PHP side. The PHP code of the example is located under IgnitePhpExample/source folder which includes two scripts. The first script (ignite_preload.php) fills in the caches with dummy data while the second (ignite_query.php) retrieves the data from there.
Let's look over some of PHP methods that are used to communicate to the cluster.
Connecting to Cluster
To connect to the cluster we simply need to pass the DSN name configured before to PDO object.
$dbh = new PDO('odbc:LocalApacheIgniteDSN');
This call will establish a connection to the cluster over the ODBC driver and ODBC processor running on the cluster side.
Data Preloading
DML's INSERT statements are used to fill in caches with exemplary data.
$dbh->prepare('INSERT INTO Person (_key, firstName, lastName, age, address)
VALUES (?, ?, ?, ?, ?)');
All the fields except _key were listed as a part of the query entity configuration before and known by SQL Grid. As for _key, it's a special predefined field and it refers to the whole key's object which is of Integer type for Persons.
This special field is not used by statements that insert Vehicles into their own cache. Values of personId and vehicleId fields are used to construct a resulting key and the key will be used on the cluster side at the time the whole cache entry will be being added to the cache.
$dbh->prepare('INSERT INTO "VehicleCache".Vehicle (personId, vehicleId, type, model, year)
VALUES (?, ?, ?, ?, ?)');
Also, VehicleCache has to be explicitly set as a schema name for Vehicles. A schema name is equal to a cache name that is defined in the configuration. For Persons the schema name is set in the DSN configuration and, thus, can be omitted while for Vehicles it has to be specified in a query all the time.
Querying Data
It's time to see how to get the data back from the cluster. Since Apache Ignite is SQL ANSI-99 compliant we're not limited to any queries' format.
It means that we're free to execute elementary queries like the one below
$res = $dbh->query('SELECT count(*) FROM Person');
and complex queries that JOIN data located in different caches and on different cluster nodes.
$res = $dbh->query('SELECT p.lastName, min(v.year) as year_res FROM Person as p
JOIN "VehicleCache".Vehicle as v ON p._key = v.personID
WHERE p.age > 30 and p.age < 50 GROUP BY p.lastName ORDER BY year_res');
Conclusion
This example illustrates how the introduction of Apache Ignite's SQL Grid establishes a bridge between Apache Ignite and a variety of programming languages not natively supported by the data fabric. Even more, you're free to use familiar SQL statements from your existing applications which will make a migration from a relational database to Apache Ignite much easier.