
This is the fifth article in this blog series and I will focus this time on the support for a distributed SQL database in Apache® Ignite™.
Distributed SQL database
Today, SQL is still a very popular language for data definition, data manipulation and querying in database management systems. Although often associated with Relational database systems, it is now used far more widely with many non-Relational database systems also supporting SQL to varying degrees. Furthermore, there is a huge market for a wide-range of SQL-based tools that can provide visualization, reports and business intelligence. These use standards such as ODBC and JDBC to connect to data sources.
Apache Ignite has supported SQL query statements, such as SELECT, for a long time. The latest releases of the Apache Ignite project provide support for Data Manipulation Language (DML) commands, such as INSERT, UPDATE and DELETE. Additionally, some Data Definition Language (DDL) support has also been added. Furthermore, index support is also available and data can be queried both in RAM and on disk. A database in Apache Ignite is horizontally scalable, fault tolerant and the SQL is ANSI-99 compliant. Figure 1 show the high-level architecture and vision.
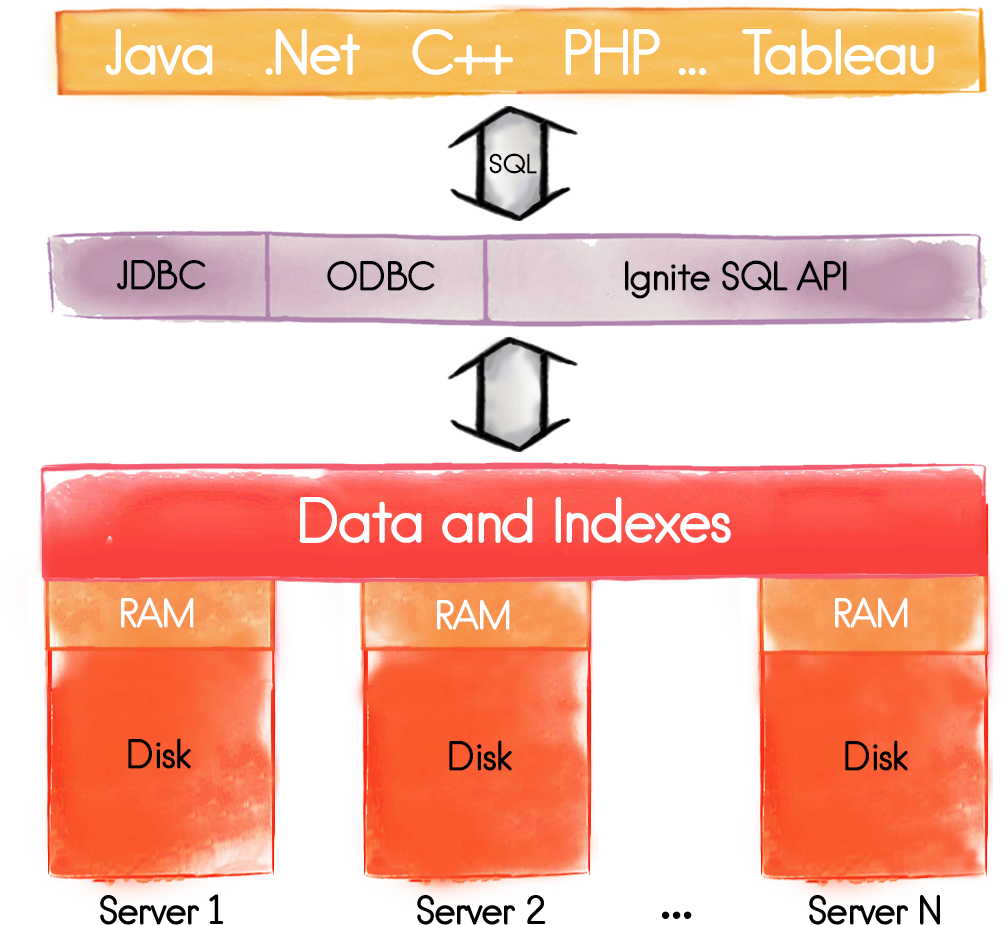
Figure 1. SQL support in Apache Ignite
As shown in Figure 1, users can interact with Apache Ignite through various APIs, such as Java, .NET and C++. Standard SQL commands can also be used through ODBC or JDBC. This provides cross-platform connectivity from many other languages, such as PHP and Ruby for example.
Figure 1 also shows that the database is distributed across the cluster. By default, the data are held in RAM. Persistence to disk can also be enabled, if required. The Apache Ignite Persistent Store, to be released in version 2.1, will allow a superset of data to be held on disk, whilst keeping a subset in RAM. Enabling the Persistent Store, we can execute SQL queries over the data that are in different memory layers and we don't need to warm-up RAM by pre-loading everything from disk in case of cluster restarts. The SQL database fully supports Atomicity, Consistency, Isolation and Durability (ACID) and provides all the benefits supported by Apache Ignite, such as high availability and scalability to thousands of cluster nodes. As mentioned in an earlier blog post, Apache Ignite also provides the flexibility and benefits of deployment on-premise or in the cloud.
The SQL supports all Data Manipulation Language (DML) commands, such as INSERT and UPDATE and some Data Definition Language (DDL) commands, such as CREATE and DROP, with additional commands under development, as of the time of writing this article.
In more detail, the DML supports distributed joins, aggregations and grouping. Furthermore, there is ad-hoc SQL support. Let's now see some DML code examples from a number of different languages.
In Figure 2, we can see an example of an SQL join from Java.
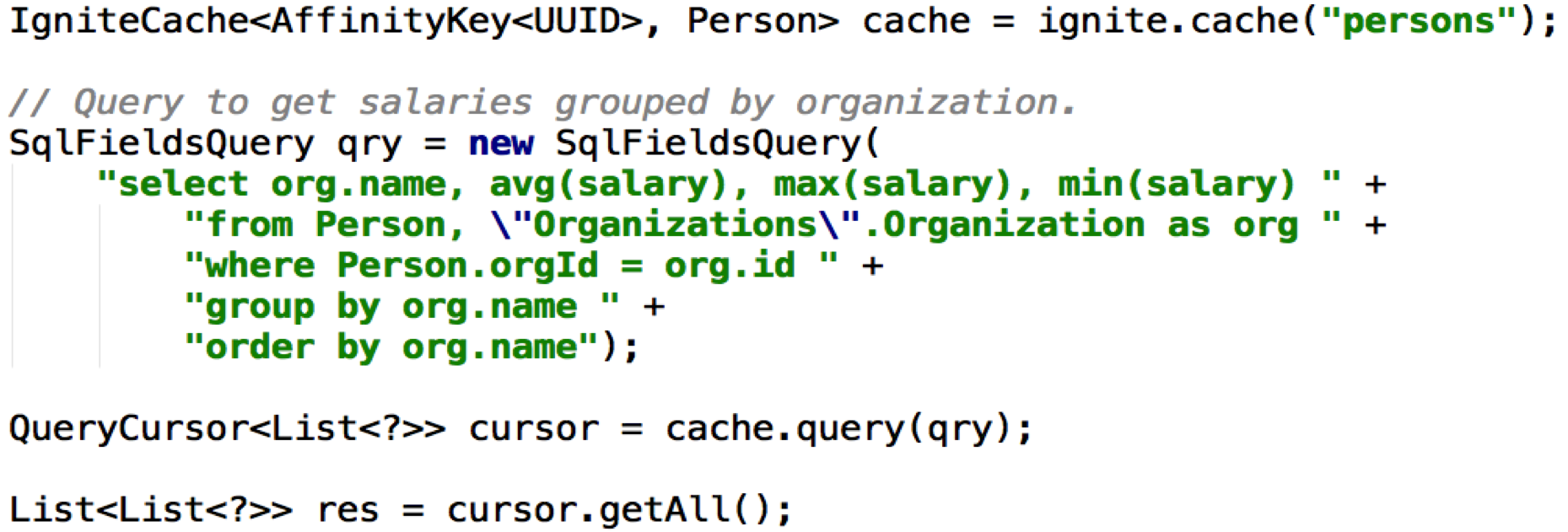
Figure 2. SQL Join using Java
In Figure 3, we can see an example of inserting data from PHP.
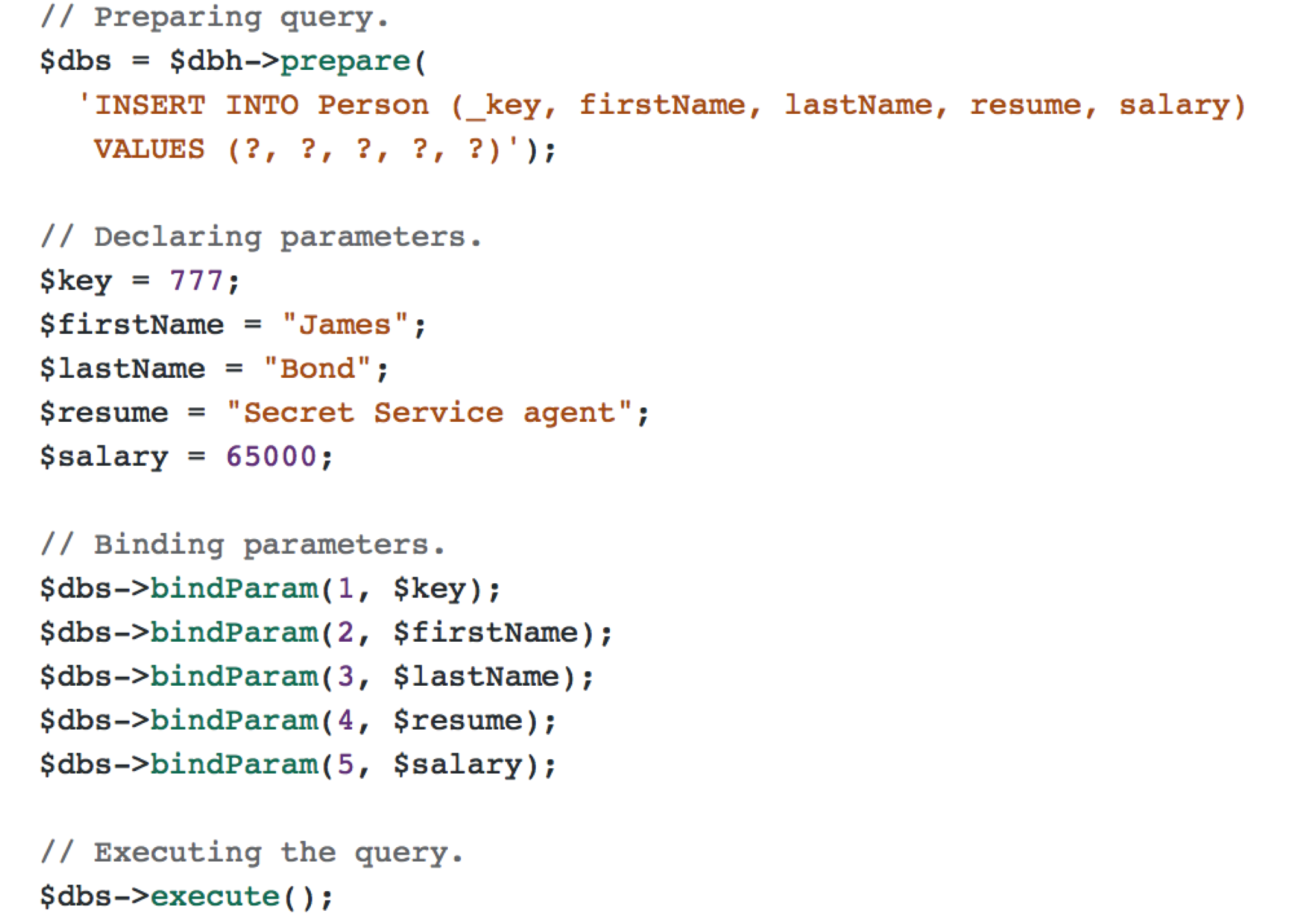
Figure 3. SQL INSERT using PHP
Figure 4 shows an example of how to update data from C++.

Figure 4. SQL UPDATE using C++.
In more detail, the DDL supports the creation and dropping of indexes, runtime or cluster-wide. Creation and dropping of SQL schemas will be available in the 2.1 release of Apache Ignite. Many additional features and capabilities are also planned.
Summary
The SQL features added to Apache Ignite enable it to be used as a fully distributed SQL database. Integration with the other components means that Apache Ignite is a true Swiss Army Knife, providing scalability and performance for many varied and demanding workloads.
This is part five of a seven-part series. You can find the rest of the series at the links below:
- Getting Started with Apache® Ignite™ Tutorial (Part 1: Introduction)
- Getting Started with Apache® Ignite™ Tutorial (Part 2: Data Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 3: Compute Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 4: Streaming Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 5: Distributed SQL Database) (this blog post)
- Getting Started with Apache® Ignite™ Tutorial (Part 6: Service Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 7: Machine Learning (ML) Grid)