
This is the fourth article in this blog series and I will focus this time on the Streaming component of Apache Ignite.
Streaming Grid
Streaming represents data that continuously enters a system. The quantity of data may vary in size. The challenge is to store the streamed data and process it without running out of memory. To achieve this processing, the concept of a sliding window is used. This window could be based upon a time period or number of events. For example, we may be interested in the data that were streamed within the last five minutes or we may be interested in the last three events. Figure 1 shows an example of an event-based sliding window.
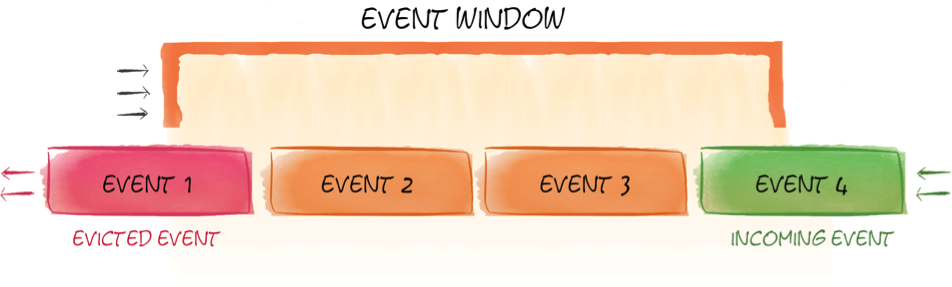
Figure 1. Event-based sliding window
In Figure 1, we have a sliding window for the last three events. As a new event arrives, an older event is evicted.
In either time-based or event-based windows, the size of the sliding window is predictable and we can perform operations on the data within the window, such as indexing the data, querying the data using SQL, and so on.
In Apache Ignite, sliding windows are implemented using the cache mechanism. Therefore, all the cache API features are available with sliding windows. We may also have multiple windows if we have multiple streams. And we can perform operations across these windows, such as SQL joins.
Apache Ignite sliding windows can be viewed as customized eviction policies for caches. We have already mentioned time-based and event-based windows. However, we could also have sliding windows based upon other criteria, such as FIFO and LRU. Eviction policies are a pluggable component of Apache Ignite and new policies can be designed and configured.
With streaming data we need to be mindful of two things:
- Data ingestion
- Configuring the sliding window
The Apache Ignite Data Streamer API can be used for data ingestion. The Data Streamer is designed to inject large quantities of data, whether finite or continuous, into caches. It can also use automatic data partitioning between cluster nodes, as shown in Figure 2.
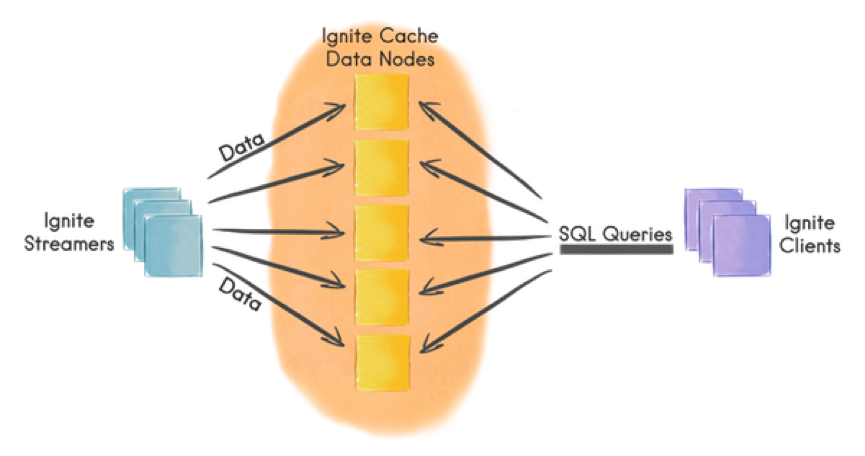
Figure 2. Apache Ignite Data Streamer
On the left-hand side of Figure 2, we can see Ignite Streamers. Data are automatically partitioned amongst the five cluster nodes. Furthermore, the data can be batched together for each node allowing more efficient resource utilization.
In Apache Ignite there is also a Stream Receiver. This allows data to be processed on a node where it will be cached. Processing could include applying transformations to key-value pairs and storing the data in another cache.
Apache Ignite integrates with many different data sources, such as TCP/IP sockets, JMS, Apache Kafka, MQTT, Apache Camel, Twitter, and so on. New data sources can also be easily created.
Summary
In this article we have briefly looked at the Apache Ignite Streaming Grid component. Streaming data is becoming quite prevalent today with many sources, such as sensors, generating large quantities of data. Apache Ignite provides efficient ways to ingest, manage and query streaming data.
Next time, we'll look more closely at the SQL Grid.
This is part four of a seven-part series. You can find the rest of the series at the links below:
- Getting Started with Apache® Ignite™ Tutorial (Part 1: Introduction)
- Getting Started with Apache® Ignite™ Tutorial (Part 2: Data Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 3: Compute Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 4: Streaming Grid) (this blog post)
- Getting Started with Apache® Ignite™ Tutorial (Part 5: Distributed SQL Database)
- Getting Started with Apache® Ignite™ Tutorial (Part 6: Service Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 7: Machine Learning (ML) Grid)