
In this article I will focus on the new Machine Learning (ML) Grid. This is in development, but already offers a number of capabilities that may be very useful to Data Scientists.
Machine Learning (ML) Grid
Machine learning is a method of data analysis that automates the building of analytical models. By using algorithms that iteratively learn from data, computers are able to find hidden insights without the help of explicit programming. These insights bring tremendous benefits into many different domains. For business users, in particular, these insights help organizations improve customer experience, become more competitive, and respond much faster to opportunities or threats. The availability of powerful in-memory computing platforms, such as Apache Ignite, means that more organizations can benefit from machine learning today.
Many machine learning algorithms were developed decades ago. However, the availability today of increased computational power, as well as affordable data storage, has meant that previously complex machine learning algorithms can now be easily applied to many modern problems, as well as large data sets that are common to big data. With big data, we commonly see the "3 Vs" mentioned - volume, variety and velocity. The volume of data that organizations must manage increases each year and many modern technologies provide the ability to store these data using off-the-shelf hardware. The variety of data also increases as we no longer deal with just text data, but complex data types, such as graphics, sound, videos, and so on. Using machine learning, we can gain insights into this volume and variety of data. This may provide significant competitive advantages. Furthermore, on the velocity side, the ability to create many thousands of models quickly means that we can make automatic business predictions for better decision-making in real-time.
Support for machine learning was introduced in Apache Ignite version 2.0 and Figure 1 shows the high-level architecture and vision.
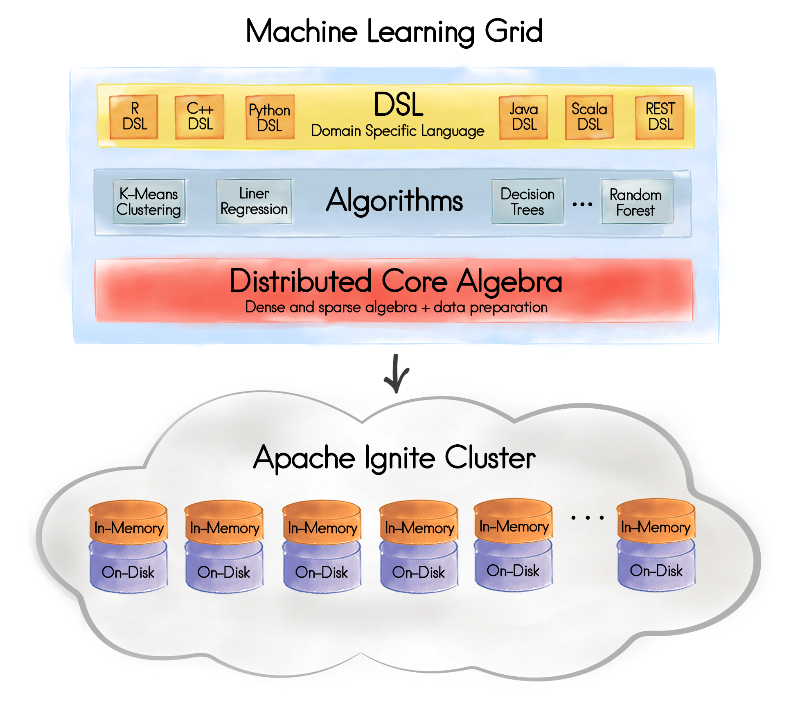
Figure 1. Apache Ignite Machine Learning Grid
Previously, to perform machine learning, it was necessary to export data from Apache Ignite into other systems using ETL. This resulted in two major drawbacks:
- A costly ETL process.
- An inability to use and benefit from Apache Ignite's distributed processing architecture.
The goal of the ML Grid is to eliminate the ETL and allow algorithms to run directly on the data stored in Apache Ignite, whilst making full use of its distributed processing architecture. The focus is on real-time machine learning and deep learning for large, sparse data sets. The initial beta offering in Apache Ignite version 2.0 supported core vector and matrix algebra implementations in a distributed machine learning library. Figure 2 shows a basic matrix API usage example.
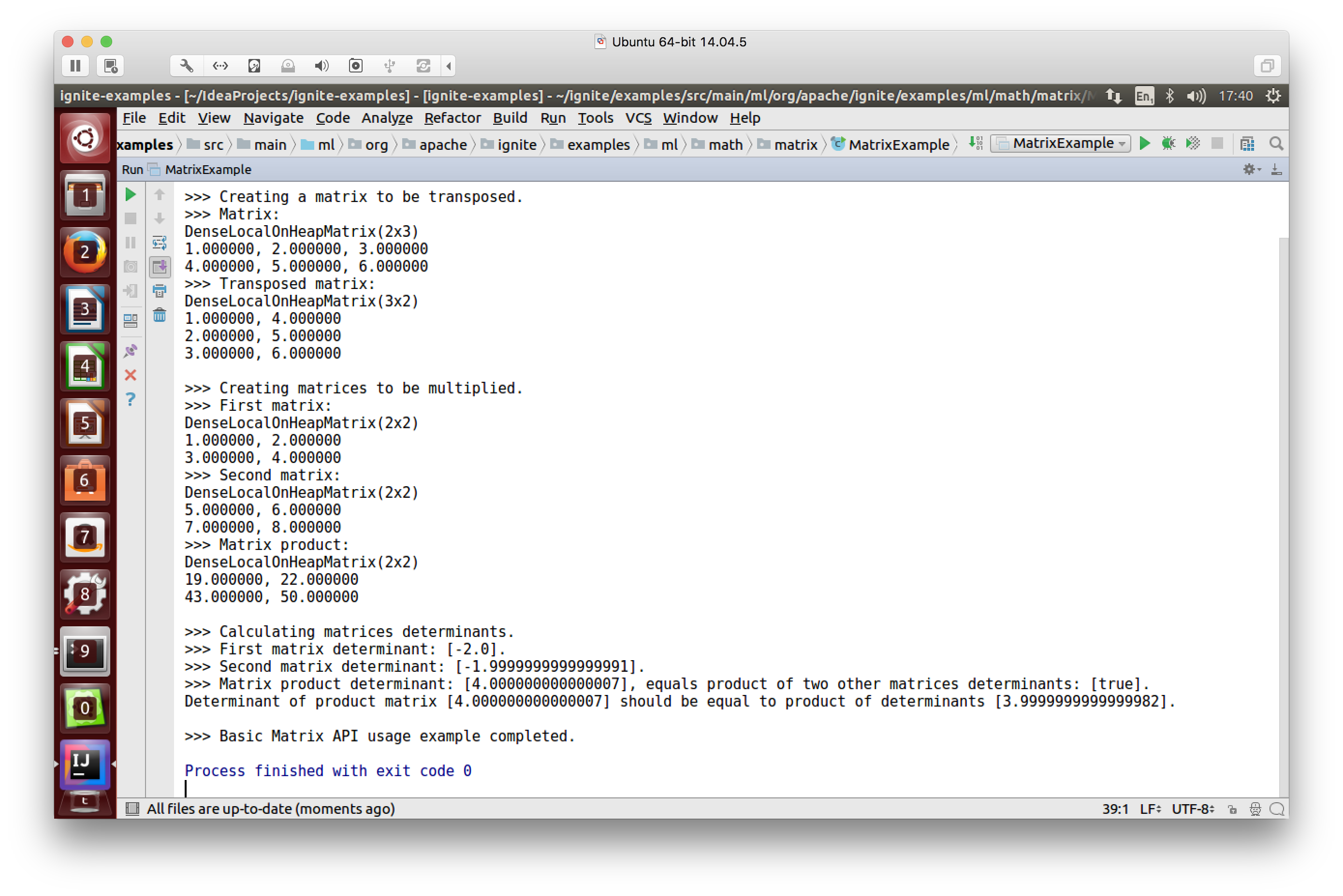
Figure 2. Basic Matrix API example
In Figure 3, we have an example of tracer output to the console in ASCII.
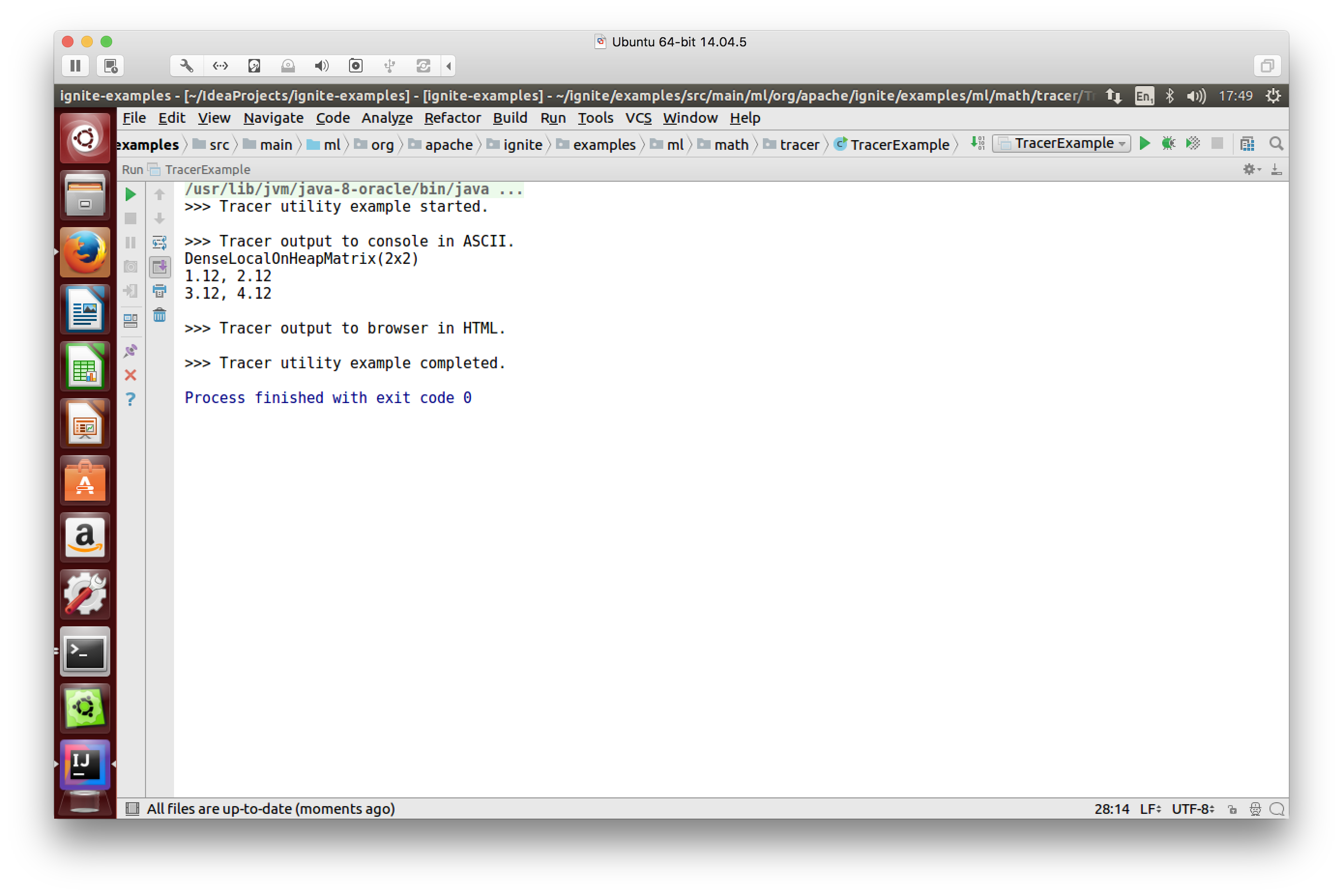
Figure 3. Tracer output to console in ASCII
After calculating the Max and Min for the matrix shown in Figure 3, the result can be output to HTML, as shown in Figure 4.
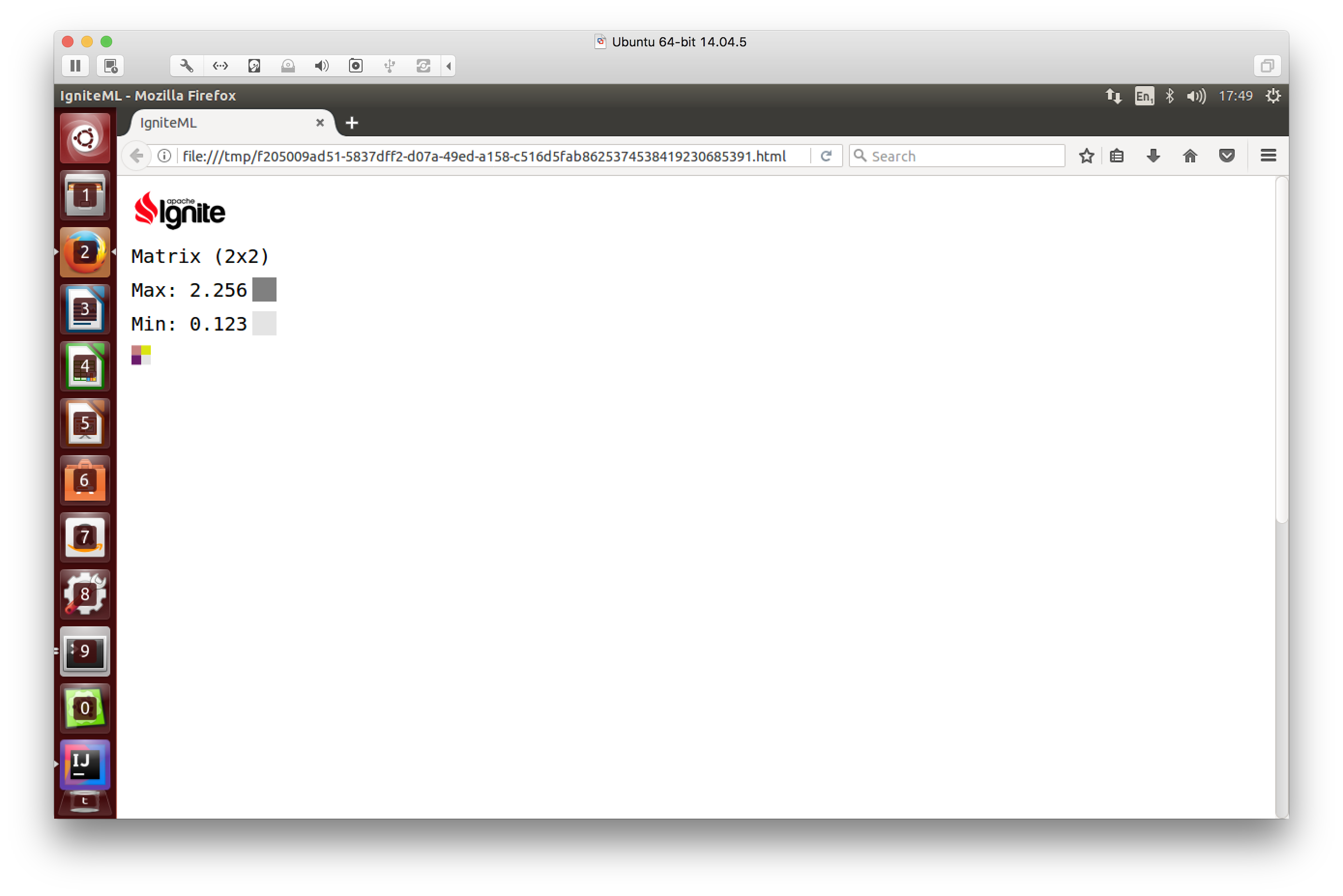
Figure 4. Tracer output to browser in HTML
Future versions will bring support for various programming languages, such as Python, R and Scala. Various well-known algorithms will also be supported including Linear and Logistic Regression, Decision Trees, and K-Means Clustering. For example, Apache Ignite version 2.1 already supports K-Means Clustering for both local and distributed data sets. There is also support for Ordinary Least Squares (OLS) Multiple Linear Regression.
In future releases of the ML Grid, support is also planned for neural networks and TensorFlow.
Summary
Machine learning techniques are increasing in popularity today as new computing platforms, such as Apache Ignite, emerge to store and query vast quantities of data. Apache Ignite also offers in-memory processing capabilities, which can decrease query execution times significantly and allow very large data sets to be processed. This efficiency provides significant benefits to organizations, as they can interactively uncover new insights into big data using graphical dashboards and other visualization tools.
This is part seven of a seven-part series. You can find the rest of the series at the links below:
- Getting Started with Apache® Ignite™ Tutorial (Part 1: Introduction)
- Getting Started with Apache® Ignite™ Tutorial (Part 2: Data Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 3: Compute Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 4: Streaming Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 5: Distributed SQL Database)
- Getting Started with Apache® Ignite™ Tutorial (Part 6: Service Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 7: Machine Learning (ML) Grid) (this blog post)