
In the previous article, I discussed my motivation for writing this blog series. Also presented was the high-level component view of Apache® Ignite™, shown in Figure 1.
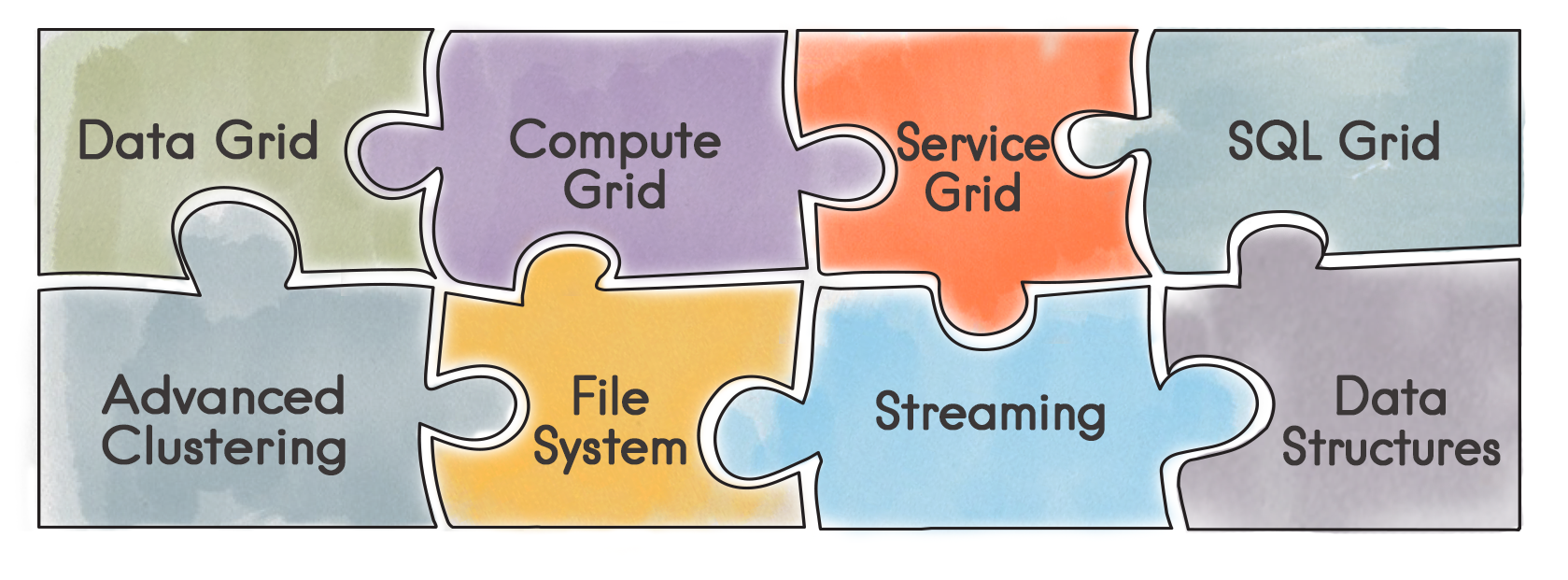
Figure 1. Main components of Apache Ignite
The previous article also briefly introduced Clustering and Deployment. This article will focus on the Data Grid.
Data Grid
In Apache Ignite, a Data Grid can be thought of as a distributed Key-Value (K-V) store or a distributed HashMap.
In Figure 2, we can see an example Apache Ignite cluster, where the entire data set is held in the Ignite Distributed In-Memory Cache.
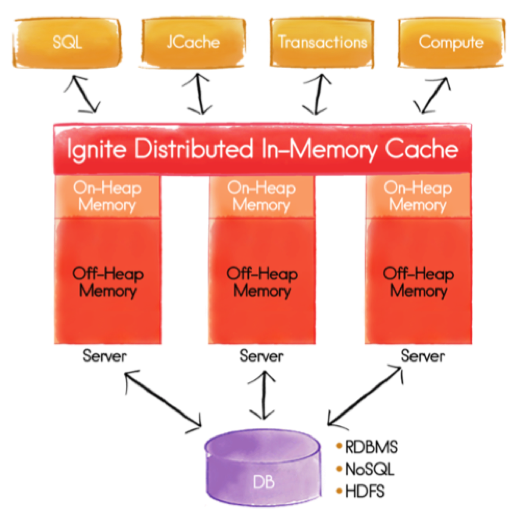
Figure 2. Apache Ignite Cluster
The cluster in Figure 2 consists of three servers and the data are distributed evenly across all three servers. Also shown in Figure 2, is that the data can be stored either On-Heap or Off-Heap. On-Heap is within the Java Heap and Off-Heap is outside the Java Heap. In On-Heap, Java Garbage Collection passes may cause the cluster to freeze so, to avoid this problem, Off-Heap can be used. Apache Ignite provides its own memory management for Off-Heap. We can also see in Figure 2 that Off-Heap memory is larger than On-Heap memory, which allows for unlimited scalability.
Apache Ignite can be used to cache data from an underlying data source, such as a Relational database system, a NoSQL database system or Hadoop/HDFS. When the data in the cache are updated, these updates can be propagated to the underlying data source. Similarly for read operations, if the cache does not have the data, it will read the data from the underlying data source.
Another very important feature is redundancy, where data can be backed-up with one or more in-memory copies. The number of backup copies can be configured. Apache Ignite also supports replicas, so that backup copies are available on other cluster nodes. This is very useful in the case where a node becomes unavailable for some reason, and another node in the grid that contains a backup copy of the data from the unavailable node can be promoted to become the primary source of the data. This failover is automatic and transparent to any applications.
Let's see some examples of caching strategies. First, we'll start with partitioned caching.
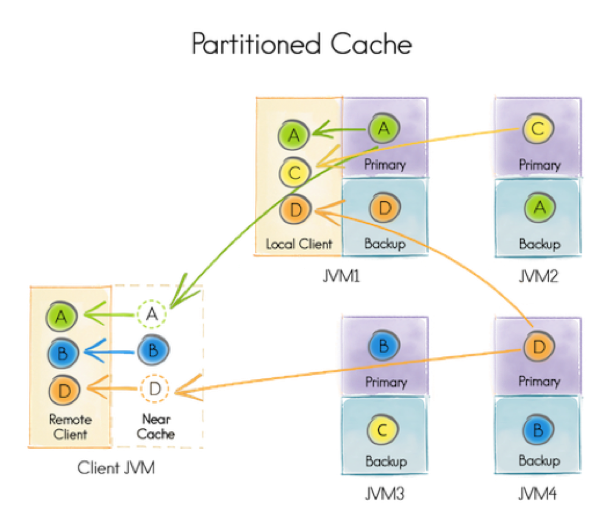
Figure 3. Partitioned Cache
In Figure 3, we have four keys: A, B, C and D. Apache Ignite automatically distributes these keys across four servers: JVM1, JVM2, JVM3, and JVM4. We can also see that there is a backup of each key and the four backup keys are also distributed across the four servers. So, in this scenario, each server has a small part of the whole data set. The advantage of this approach is that only the primary and backup servers need to be updated if there are key updates.
The arrows show possible access patterns for a Client JVM. The Near Cache shown on the Client JVM is optional. Suppose the client application wants to access key A and finds that it is not available in the Near Cache. It then checks JVM1, which holds the primary copy of key A. The key is then fetched to the Near Cache and then available for use by the client application. Next, the client wants to access key B and finds that it is in the Near Cache already, so no further work is required in this case. To find the node where a particular key resides, the client uses an affinity function; something we'll discuss in more detail in a future article.
Let's now look at how replicated caching works.
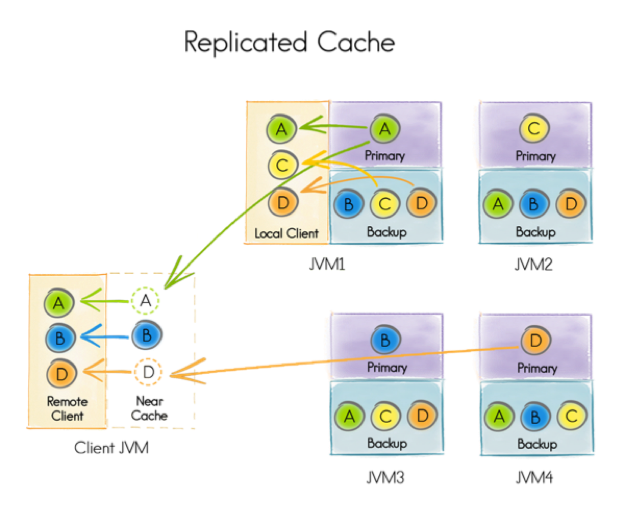
Figure 4. Replicated Cache
In Figure 4, we can see that every server has the whole data set. So, each server acts as a primary for each of the four keys A, B, C and D, and also as backup for all the other keys. So, in this approach, each server needs to have enough memory to hold the whole data set and any updates need to be propagated to all servers. However, this scenario could be useful for small data sets and where data do not change frequently.
Apache Ignite also supports transactions. These follow the well-known Atomicity, Consistency, Isolation, and Durability (ACID) requirements typically found in database systems. We’ll cover transactions in more detail in a future article.
Summary
In this article, we have briefly looked at the Apache Ignite Data Grid component. In particular, we have focussed on two caching strategies: partitioned caching and replicated caching.
Next time, we'll look more closely at the SQL Grid and how it can work with the Data Grid.
This is part two of a seven-part series. You can find the rest of the series at the links below:
- Getting Started with Apache® Ignite™ Tutorial (Part 1: Introduction)
- Getting Started with Apache® Ignite™ Tutorial (Part 2: Data Grid) (this blog post)
- Getting Started with Apache® Ignite™ Tutorial (Part 3: Compute Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 4: Streaming Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 5: Distributed SQL Database)
- Getting Started with Apache® Ignite™ Tutorial (Part 6: Service Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 7: Machine Learning (ML) Grid)