
Figure 1 shows a high-level component view of Apache Ignite. So far in this blog series, I have briefly discussed Clustering and Deployment and the Data Grid.
Figure 1. Main components of Apache Ignite
I mentioned in the previous article that I could cover the SQL Grid next. However, because of late-breaking developments, I have postponed this for a few weeks. Instead, I will focus on the Compute Grid in this article.
Compute Grid
The Compute Grid is one of the most mature components of Apache Ignite. Its main function is to ensure that tasks can be executed in parallel within the grid. Parallelism ensures that results are returned very quickly and this also provides fault-tolerance.
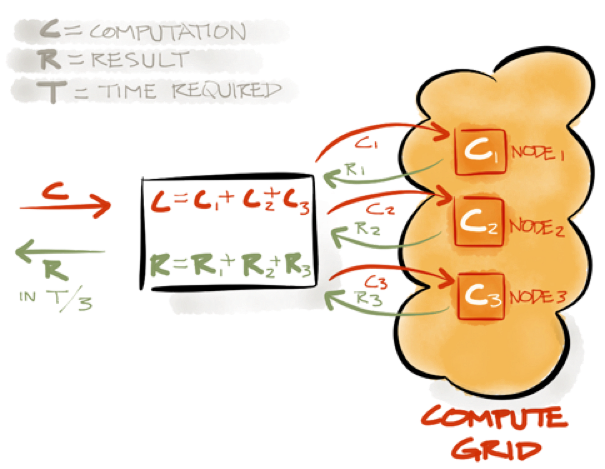
Figure 2. Compute Grid
Figure 2 shows the main elements of the Compute Grid. We have an example computation called C that is split into multiple parts C1, C2, and C3.
In Apache Ignite, a computation is referred to as a task and each part that the task is split into is referred to as a job. Once the task has been split into jobs, Apache Ignite will assign each job to a node for execution, as shown in Figure 2. The jobs are then executed in parallel. Once the execution is complete, the results are returned to the caller, aggregated and then the final answer returned to the user. This type of processing is referred to as ForkJoin. Apache Ignite also supports other processing models, such as MapReduce. ForkJoin could be viewed as an example of MapReduce where the map and reduce operations are performed by the caller.
Not all situations require that the task be split into multiple jobs and Apache Ignite also supports Distributed Closure Execution. As described in the Apache Ignite documentation, "a closure is a block of code that encloses its body and any outside variables used inside of it as a function object. You can then pass such function object anywhere you can pass a variable and execute it." Additional capabilities include load balancing and fault tolerance.
Once a task has been split into multiple jobs, the jobs often need to be able to communicate with each other or share state with each other. In Apache Ignite this is referred to as a Task Session. A Task Session's scope can be either local or global. The order of modification of session attributes is preserved. Furthermore, Apache Ignite supports Checkpoints that are very useful for saving the intermediate states of jobs, particularly useful for long-running jobs. Checkpoints can be saved to permanent storage, such as a database.
There are also several other methods to share state between jobs.
The first method is by job context, which belongs only to the job and is attached as the job executes. If the job moves to another node, the job context will move with it.
The second method is by per-node shared state, called node local map. This approach uses the standard Java Concurrent Map API to read or update the state of the node local map.
The third and final method is to use a distributed cache by partitioning or replication. We discussed these two methods in a previous article.
Summary
In this article, we have briefly looked at the Apache Ignite Compute Grid component.
Next time, we'll look more closely at Streaming and Complex Event Processing (CEP).
This is part three of a seven-part series. You can find the rest of the series at the links below:
- Getting Started with Apache® Ignite™ Tutorial (Part 1: Introduction)
- Getting Started with Apache® Ignite™ Tutorial (Part 2: Data Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 3: Compute Grid) (this blog post)
- Getting Started with Apache® Ignite™ Tutorial (Part 4: Streaming Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 5: Distributed SQL Database)
- Getting Started with Apache® Ignite™ Tutorial (Part 6: Service Grid)
- Getting Started with Apache® Ignite™ Tutorial (Part 7: Machine Learning (ML) Grid)