Distributed Computing
GridGain 9 lets you run your own code on the cluster in a distributed, balanced, and fault-tolerant way.
Tasks can run on a single node, multiple nodes, or across the entire cluster, and you can choose between synchronous and asynchronous execution.
In addition to standard compute tasks, GridGain 9 supports Colocated Execution. This means your tasks can run directly on the nodes that store the required data, reducing network overhead and improving performance. The cluster also supports MapReduce Tasks, allowing for efficient processing of large datasets. In this case, tasks will be executed on nodes that hold the data required for them.
When sending code and data between nodes, objects are converted into a transferable format so they can be accurately rebuilt. GridGain 9 automatically handles marshalling for common types like tuples, POJOs, and native types, but for more complex or custom objects, you may need to implement your own marshalling logic.
Compute Job Code Deployment
Before submitting your compute job, ensure that the required code is deployed to the nodes where it will execute.
If you are using embedded nodes, any code that is included in the project classpath will also be available to your compute jobs.
Configuring Jobs
In GridGain 9, compute job’s execution is defined by two key components: JobTarget and JobDescriptor. These components determine on which nodes the job will run and how it will be structured, including input and output types, marshallers, and the deployed class that represents the job.
Job Target
Before submitting a job, you must create a JobTarget object that specifies which nodes will execute the job. Job target can point to a specific node, any node on the cluster, or start a colocated compute job, that will be executed on nodes that hold a specific key. The following methods are available:
-
JobTarget.anyNode()- the job will be executed on any of the specified nodes. -
JobTarget.node()- the job will be executed on the specific node. -
JobTarget.colocated()- the job will be executed on a node that holds the specified key.
Job Descriptor
The JobDescriptor object contains all the details required for job execution. The following arguments must be provided:
-
The job descriptor is created using a builder that specifies the input type for the job arguments, the expected output type, and the fully qualified name of the job class to execute.
-
unitstakes your deployment unit. You create it with the unit’s name and specifyVersion.LATESTso that your job always runs the most recently deployed version. -
resultClasssets the expected result type so the system can correctly process the job’s output. -
argumentMarshallerandresultMarshallerdefines how to serialize the job’s input argument and output result. For common types, you can omit the marshallers and passnullto the builder since GridGain 9 automatically handles marshalling.
Examples below assumes that the NodeNameJob class has been deployed to the node by using code deployment.
-
If you are working with common types, you don’t need to define custom marshallers. GridGain will handle them automatically. The following example shows a simpler job descriptor that uses built-in marshalling:
JobDescriptor<String, Integer> job = JobDescriptor.builder(WordCountJob.class) .units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION)) .build(); JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes()); String phrase = "Count characters using callable"; System.out.println("\nExecuting compute job for the phrase '" + phrase + "'..."); Integer wordCnt = client.compute().execute(jobTarget, job, phrase); -
This example shows how to create a custom job descriptor for a job that takes a user-defined
MyJobArgument, runs on a random cluster node, and returns aMyJobResultobject using custom marshallers:JobDescriptor<String, WordInfoResult> job = JobDescriptor.builder(WordInfoJob.class) .resultMarshaller(new WordInfoResultMarshaller()) .units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION)) .build(); JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes()); ArrayList<WordInfoResult> results = new ArrayList<>(); String phrase = "Count characters using compute job"; for (String word : phrase.split(" ")) { System.out.println("\nExecuting compute job for the word '" + word + "'..."); WordInfoResult result = client.compute().execute(jobTarget, job, word); results.add(result); }
For more details on configuring jobs refer to the corresponding API section.
Deployment Unit Information
The JobExecutionContext object contains the information about the deployment units the job is using as a collection of DeploymentUnitInfo for each deployment unit involved in the job.
Each DeploymentUnitInfo object provides the following information:
-
name()- The name of the deployment unit -
version()- The version of the deployment unit -
path()- The filesystem path to the deployment unit contents
public class DiagnosticJob implements ComputeJob<Void, String> {
@Override
public CompletableFuture<String> executeAsync(JobExecutionContext context, Void input) {
// Access deployment unit information
String deploymentInfo = context.deploymentUnits().stream()
.map(unit -> String.format("%s:%s at %s",
unit.name(),
unit.version(),
unit.path()))
.collect(Collectors.joining(", "));
return CompletableFuture.completedFuture(deploymentInfo);
}
}Executing Jobs
GridGain compute jobs can run on a specific node, any node, or using a colocated approach when job is executed on the node holding the relevant data key.
Single Node Execution
Often, you need to perform a job on one node in the cluster. In this case, there are multiple ways to start job execution:
-
submitAsync()- sends the job to the cluster and returns a future that will be completed with theJobExecutionobject when the job is submitted for execution. -
executeAsync()- sends the job to the cluster and returns a future that will be completed when job execution result is ready. -
execute()- sends the job to the cluster and waits for the result of job execution.
try (IgniteClient client = IgniteClient.builder()
.addresses("127.0.0.1:10800")
.build()
) {
System.out.println("\nConfiguring compute job...");
JobDescriptor<String, Void> job = JobDescriptor.builder(WordPrintJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes());
for (String word : "Print words using runnable".split(" ")) {
System.out.println("\nExecuting compute job for word '" + word + "'...");
client.compute().execute(jobTarget, job, word);
}
}ICompute compute = Client.Compute;
IList<IClusterNode> nodes = await Client.GetClusterNodesAsync();
IJobExecution<string> execution = await compute.SubmitAsync(
JobTarget.AnyNode(nodes),
new JobDescriptor<string, string>("org.example.NodeNameJob"),
arg: "Hello");
string result = await execution.GetResultAsync();using namespace ignite;
compute comp = client.get_compute();
std::vector<cluster_node> nodes = client.get_nodes();
// Unit `unitName:1.1.1` contains NodeNameJob class.
auto job_desc = job_descriptor::builder("org.company.package.NodeNameJob")
.deployment_units({deployment_unit{"unitName", "1.1.1"}})
.build();
job_execution execution = comp.submit(job_target::any_node(nodes), job_desc, {std::string("Hello")}, {});
std::string result = execution.get_result()->get<std::string>();Multiple Node Execution
To execute the compute task on multiple nodes, you use the same methods as for single node execution, except instead of creating a JobTarget object to designate execution nodes you use the BroadcastJobTarget and specify the list of nodes that the job must be executed on.
The BroadcastJobTarget object can specify the following:
-
BroadcastJobTarget.nodes()- the job will be executed on all nodes in the list. -
BroadcastJobTarget.table()- the job will be executed on all nodes that hold partitions of the specified table.
You can control what nodes the task is executed on by setting the list of nodes:
JobDescriptor<String, Void> job = JobDescriptor.builder(HelloMessageJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
BroadcastJobTarget target = table("Person");
System.out.println("\nExecuting compute job...");
client.compute().execute(target, job, "John");ICompute compute = Client.Compute;
IList<IClusterNode> nodes = await Client.GetClusterNodesAsync();
IBroadcastExecution<string> execution = await compute.SubmitBroadcastAsync(
BroadcastJobTarget.Nodes(nodes),
new JobDescriptor<object, string>("org.example.NodeNameJob"),
arg: "Hello");
foreach (IJobExecution<string> jobExecution in execution.JobExecutions)
{
string jobResult = await jobExecution.GetResultAsync();
Console.WriteLine($"Job result from node {jobExecution.Node}: {jobResult}");
}using namespace ignite;
compute comp = client.get_compute();
std::vector<cluster_node> nodes = client.get_nodes();
// Unit `unitName:1.1.1` contains NodeNameJob class.
auto job_desc = job_descriptor::builder("org.company.package.NodeNameJob")
.deployment_units({deployment_unit{"unitName", "1.1.1"}})
.build();
broadcast_execution execution = comp.submit_broadcast(broadcast_job_target::nodes(nodes), job_desc, {std::string("Hello")}, {});
for (auto &exec: execution.get_job_executions()) {
std::string result = exec.get_result()->get<std::string>();
}Colocated Execution
In GridGain 9, you can execute colocated computations by specifying a job target that directs the task to run on the node holding the required data.
In the example below, the job runs on the node that owns the partition for the row in the accounts table identified by the primary key accountNumber.
We pass the key both to JobTarget.colocated() to select the node and as the
job argument, so the job knows which record to read.
try (IgniteClient client = IgniteClient.builder()
.addresses("127.0.0.1:10800")
.build()
) {
client.sql().executeScript(
"CREATE TABLE accounts ("
+ "accountNumber INT PRIMARY KEY,"
+ "name VARCHAR)"
);
RecordView<Tuple> view = client.tables().table("accounts").recordView();
System.out.println("\nCreating account records...");
for (int i = 0; i < ACCOUNTS_COUNT; i++) {
view.insert(null, account(i));
}
System.out.println("\nConfiguring compute job...");
JobDescriptor<Integer, Void> job = JobDescriptor.builder(PrintAccountInfoJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
int accountNumber = ThreadLocalRandom.current().nextInt(ACCOUNTS_COUNT);
JobTarget jobTarget = JobTarget.colocated("accounts", accountKey(accountNumber));
System.out.println("\nExecuting compute job for the accountNumber '" + accountNumber + "'...");
client.compute().execute(jobTarget, job, accountNumber);
QualifiedName customSchemaTable = QualifiedName.parse("CUSTOM_SCHEMA.MY_QUALIFIED_TABLE");
client.compute().execute(
JobTarget.colocated(customSchemaTable, accountKey(accountNumber)),
JobDescriptor.builder(PrintAccountInfoJob.class).build(),
null
);
System.out.println("\nDropping the table...");
client.sql().executeScript("DROP TABLE accounts");
}string table = "Person";
string key = "John";
IJobExecution<string> execution = await Client.Compute.SubmitAsync(
JobTarget.Colocated(table, key),
new JobDescriptor<string, string>("org.example.NodeNameJob"),
arg: "Hello");
string result = await execution.GetResultAsync();using namespace ignite;
compute comp = client.get_compute();
std::string table{"Person"};
std::string key{"John"};
// Unit `unitName:1.1.1` contains NodeNameJob class.
auto job_desc = job_descriptor::builder("org.company.package.NodeNameJob")
.deployment_units({deployment_unit{"unitName", "1.1.1"}})
.build();
job_execution execution = comp.submit(job_target::colocated(table, key), job_desc, {std::string("Hello")}, {});
std::string result = execution.get_result()->get<std::string>();Alternatively, you can execute the compute job on all nodes in the cluster that hold partitions for the specified table by creating a BroadcastJobTarget.table() target. In this case, GridGain will automatically find all nodes that hold data partitions for the specified table and execute the job on all of them.
Partition-Local Queries with BroadcastJobTarget.table()
When using BroadcastJobTarget.table(), each job instance is routed to a node holding one partition of the table. Inside the job, call context.partition() to discover the assigned partition, then filter rows with the __PARTITION_ID virtual SQL column. This guarantees the query reads only local data — no cross-node data movement occurs.
JobDescriptor<Void, Long> partitionQueryJob = JobDescriptor.builder(PartitionQueryJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
Collection<Long> partitionCounts = client.compute().execute(table("Person"), partitionQueryJob, null);
long totalPersons = partitionCounts.stream().mapToLong(Long::longValue).sum();
System.out.println("\nTotal person count across all partitions: " + totalPersons);The PartitionQueryJob class uses context.partition() to obtain its assigned partition and filters rows with __PARTITION_ID:
/**
* Job that counts persons in a single table partition using the {@code __PARTITION_ID} virtual SQL column.
*
* <p>Designed for use with {@link BroadcastJobTarget#table}: one instance runs per partition,
* {@code context.partition()} is always non-null, and the SQL query reads only local data.
*/
public static class PartitionQueryJob implements ComputeJob<Void, Long> {
/** {@inheritDoc} */
@Override
public CompletableFuture<Long> executeAsync(JobExecutionContext context, Void arg) {
Partition partition = context.partition();
assert partition != null : "Partition must be non-null when using BroadcastJobTarget.table()";
long count = 0;
try (ResultSet<SqlRow> rs = context.ignite().sql().execute(
(Transaction) null,
"SELECT COUNT(*) FROM Person WHERE __PARTITION_ID = ?",
partition.id()
)) {
if (rs.hasNext()) {
count = rs.next().longValue(0);
}
}
return completedFuture(count);
}
}.NET Compute Jobs
When working with compute jobs written in .NET, resulting binaries (DLL files) should be deployed to server nodes and invoked by the assembly-qualified type name. Every deployment unit combination is loaded into a separate AssemblyLoadContext.
You can have multiple versions of the same job (assembly) deployed to the cluster as GridGain 9 supports deployment unit isolation. One job can consist of multiple deployment units. Assemblies and types are looked up in the order you list them.
Compute job classes may implement IDisposable and IAsyncDisposable interfaces. GridGain will call Dispose or DisposeAsync after job execution whether it succeeds or fails.
.NET Compute Requirements
-
.NET 8 Runtime or later (not SDK) is required on each server node.
-
When using ZIP, DEB, RPM installation, you have to install .NET runtime yourself. GridGain Docker image includes .NET 8 runtime, so you can run .NET jobs in Docker out of the box.
Implementing .NET Compute Jobs
Below is an example on implementing a .NET compute job:
-
First, prepare a "class library" project for the job implementation using
dotnet new classlib.dotnet new classlib -n MyComputeJobs cd MyComputeJobs dotnet add package Apache.Ignite -
Add a reference to
Apache.Ignitepackage to the class library project:dotnet add package Apache.Ignite -
Then create a class that implements
IComputeJob<TArg, TRes>interface, for example:public class HelloJob : IComputeJob<string, string> { public ValueTask<string> ExecuteAsync(IJobExecutionContext context, string arg, CancellationToken cancellationToken) => ValueTask.FromResult("Hello " + arg); } -
Publish the project by using the
dotnet publish -c Releasecommand:dotnet publish -c Release mkdir deploy cp bin/Release/net8.0/MyComputeJobs.dll deploy/ # Exclude Ignite assemblies; no subdirectories allowed ignite cluster unit deploy --name MyDotNetJobsUnit --path ./deploy -
Copy the resulting dll file and any extra dependencies to a separate directory, excluding GridGain dlls.
-
Use the GridGain CLI command
cluster unit deploy commandto deploy the directory to the cluster as a deployment unit. The deployed code will be available on the cluster.
Running .NET Compute Jobs
You can execute .NET compute jobs from any client (.NET, Java, C++, etc) as long as you created a JobDescriptor with the assembly-qualified job class name and set JobExecutionOptions with JobExecutorType.DotNetSidecar.
-
For example, this is how to run your job on a single node from .NET:
var jobTarget = JobTarget.AnyNode(await client.GetClusterNodesAsync()); var jobDesc = new JobDescriptor<string, string>( JobClassName: typeof(HelloJob).AssemblyQualifiedName!, DeploymentUnits: [new DeploymentUnit("MyDeploymentUnit")], Options: new JobExecutionOptions(ExecutorType: JobExecutorType.DotNetSidecar)); IJobExecution<string> jobExec = await client.Compute.SubmitAsync(jobTarget, jobDesc, "world");Alternatively, use the
JobDescriptor.Ofshortcut method to create a job descriptor from a job instance:JobDescriptor<string, string> jobDesc = JobDescriptor.Of(new HelloJob()) with { DeploymentUnits = [new DeploymentUnit("MyDeploymentUnit")] }; -
Explicit usage of
IMapper<T>inJobTarget.Colocatedmethod allows you to compute the key hash for object keys without reflection.public sealed class PocoMapper : IMapper<Poco> { public void Write(Poco obj, ref RowWriter rowWriter, IMapperSchema schema) => rowWriter.WriteLong(obj.Key); public Poco Read(ref RowReader rowReader, IMapperSchema schema) => new() { Key = rowReader.ReadLong()!.Value }; } var key = new Poco { Key = 42L }; IJobTarget<Poco> target = JobTarget.Colocated("PUBLIC.MY_TABLE", key, new PocoMapper()); IJobExecution<string> exec = await client.Compute.SubmitAsync(target, new JobDescriptor<string, string>("org.example.NodeNameJob"), "Hello"); string result = await execution.GetResultAsync(); -
You can call Java computing jobs from your .NET code, for example:
IList<IClusterNode> nodes = await client.GetClusterNodesAsync(); IJobTarget<IEnumerable<IClusterNode>> jobTarget = JobTarget.AnyNode(nodes); var jobDesc = new JobDescriptor<string, string>(JobClassName: "org.foo.bar.MyJob", DeploymentUnits: [new DeploymentUnit("MyDeploymentUnit")]); IJobExecution<string> jobExecution = await client.Compute.SubmitAsync(jobTarget, jobDesc, "Job Arg"); string jobResult = await jobExecution.GetResultAsync(); -
You can also run .NET compute jobs from Java client, for example:
try (IgniteClient client = IgniteClient.builder().addresses("127.0.0.1:10800") .build() ) { JobDescriptor<String, String> jobDesc = JobDescriptor.<String, String>builder().jobClassName("MyNamespace.HelloJob, MyComputeJobsAssembly").deploymentUnits(new DeploymentUnit("MyDeploymentUnit")).executionOptions(new JobExecutionOptions().executorType(JobExecutorType.DotNetSidecar)).build(); JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes()); for (String word : "Print words using runnable".split(" ")) { System.out.println("\nExecuting compute job for word '" + word + "'..."); client.compute().execute(jobTarget, job, word); } }
Using Qualified Table Names
If you do not specify the table schema, the PUBLIC schema will be used. To use a different schema, specify a fully qualified table name. You can provide it in a string or by creating the QualifiedName object:
QualifiedName customSchemaTable = QualifiedName.parse("CUSTOM_SCHEMA.MY_QUALIFIED_TABLE");
client.compute().execute(
JobTarget.colocated(customSchemaTable, accountKey(accountNumber)),
JobDescriptor.builder(PrintAccountInfoJob.class).build(),
null
);This API is not presently available for .NET.This API is not presently available for C++.Just like with execution on a single node, you can use the QualifiedName object to specify a qualified table name and run a job on multiple nodes using BroadcastJobTarget:
QualifiedName customSchemaTable = QualifiedName.parse("CUSTOM_SCHEMA.MY_QUALIFIED_TABLE");
String executionResult = client.compute().execute(BroadcastJobTarget.table(customSchemaTable),
JobDescriptor.builder(HelloMessageJob.class).build(), null
);
System.out.println(executionResult);You can also use the of method to instead specify the table name and the schema separately:
QualifiedName customSchemaTableName = QualifiedName.of("PUBLIC", "MY_TABLE");
client.compute().execute(BroadcastJobTarget.table(customSchemaTableName),
JobDescriptor.builder(HelloMessageJob.class).build(), null
);The provided names must follow SQL syntax rules for identifiers:
-
Identifier must start from a character in the “Lu”, “Ll”, “Lt”, “Lm”, “Lo”, or “Nl” Unicode categories;
-
Identifier characters (expect for the first one) may be
U+00B7(middle dot),U+0331(underscore), or any character in the “Mn”, “Mc”, “Nd”, “Pc”, or “Cf” Unicode categories; -
Identifiers that contain any other characters must be quoted with double-quotes;
-
Double-quote inside the identifier must be 2 double-quote chars.
Any unquoted names will be cast to upper case. In this case, Person and PERSON names are equivalent. To avoid this, add escaped quotes around the name. For example, \"Person\" will be encoded as a case-sensitive Person name. If the name contains the U+2033 (double quote) symbol, it must be escaped as "" (2 double quote symbols).
Job Ownership
If the cluster has Authentication enabled, compute jobs are executed by a specific user. If user permissions are configured on the cluster, the user needs the appropriate distributed computing permissions to work with distributed computing jobs. Only users with JOBS_ADMIN action can interact with jobs of other users.
Job Execution States
When using asynchronous API, you can keep track of the status of the job on the server and react to status changes. For example:
CompletableFuture<JobExecution<Void>> execution = client.compute().submitAsync(JobTarget.anyNode(client.cluster().nodes()),
JobDescriptor.builder(WordPrintJob.class).build(), null
);
execution.get().stateAsync().thenApply(state -> {
if (state.status() == FAILED) {
System.out.println("\nJob failed...");
}
return null;
});IList<IClusterNode> nodes = await Client.GetClusterNodesAsync();
IJobExecution<string> execution = await Client.Compute.SubmitAsync(
JobTarget.AnyNode(nodes),
new JobDescriptor<string, string>("org.example.NodeNameJob"),
arg: "Hello");
JobState? state = await execution.GetStateAsync();
if (state?.Status == JobStatus.Failed)
{
// Handle failure
}
string result = await execution.GetResultAsync();using namespace ignite;
compute comp = client.get_compute();
std::vector<cluster_node> nodes = client.get_nodes();
// Unit `unitName:1.1.1` contains NodeNameJob class.
auto job_desc = job_descriptor::builder("org.company.package.NodeNameJob")
.deployment_units({deployment_unit{"unitName", "1.1.1"}})
.build();
job_execution execution = comp.submit(job_target::any_node(nodes), job_desc, {std::string("Hello")}, {});
std::optional<job_status> status = execution.get_status();
if (status && status->state == job_state::FAILED)
{
// Handle failure
}
std::string result = execution.get_result()->get<std::string>();Possible States and Transitions
The diagram below depicts the possible transitions of job statuses:
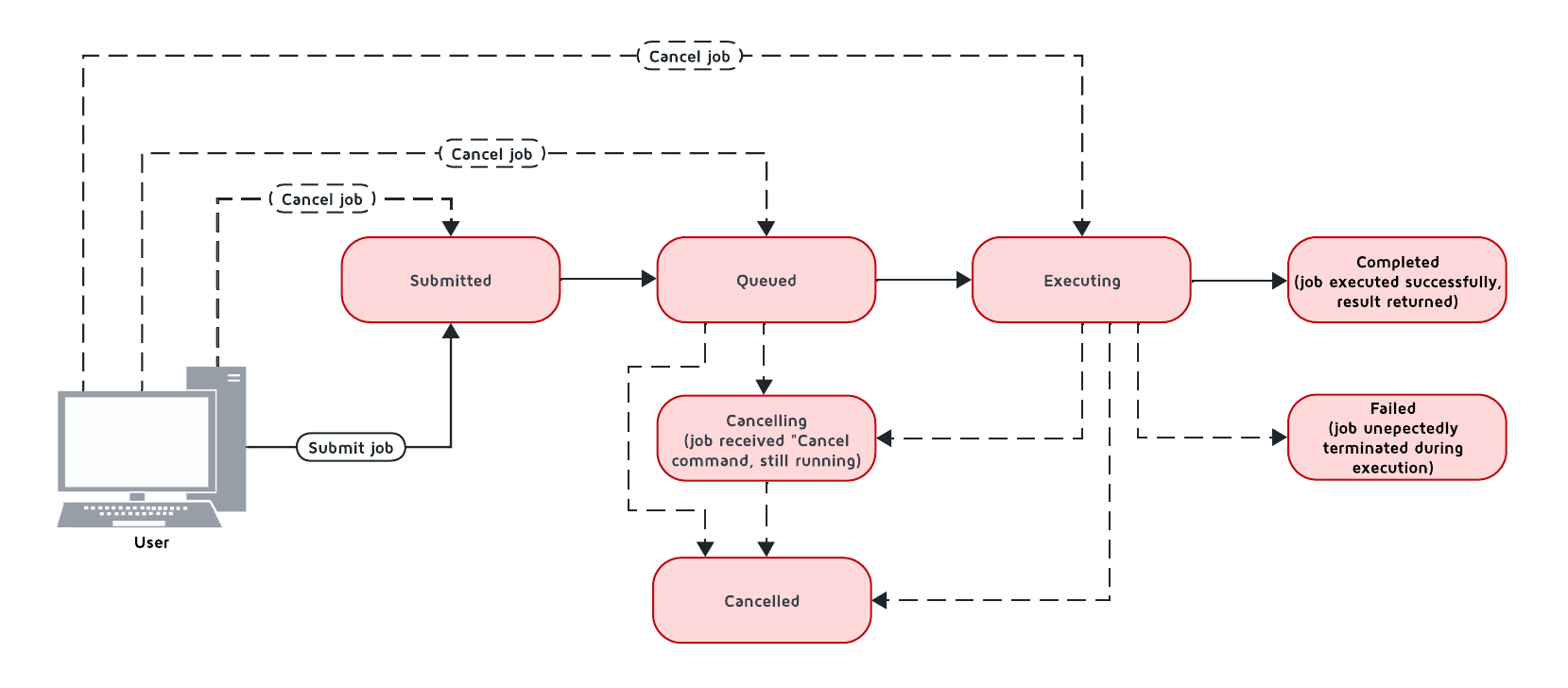
The table below lists the possible job statuses:
| Status | Description | Transitions to |
|---|---|---|
|
The job was created and sent to the cluster, but not yet processed. |
|
|
The job was added to the queue and waiting queue for execution. |
|
|
The job is being executed. |
|
|
The job was executed successfully and the execution result was returned. |
|
|
The job was unexpectedly terminated during execution. |
|
|
Job has received the cancel command, but is still running. |
|
|
Job was successfully cancelled. |
If all job execution threads are busy, new jobs received by the node are put into job queue according to their Job Priority. GridGain sorts all incoming jobs first by priority, then by the time, executing jobs queued earlier first.
Cancelling Executing Jobs
When the node receives the command to cancel the job in the Executing status, it will immediately send an interrupt to the thread that is responsible for the job. In most cases, this will lead to the job being immediately canceled, however there are cases in which the job will continue. If this happens, the job will be in the Canceling state. Depending on specific code being executed, the job may complete successfully, be canceled once the uninterruptible operation is finished, or remain in unfinished state (for example, if code is stuck in a loop). You can use the JobExecution.stateAsync() method to keep track of what status the job is in, and react to status change.
To be able to cancel a compute job, you first create a cancel handler and retrieve a token from it. You can then use this token to cancel the compute job:
JobDescriptor<Object, Void> job = JobDescriptor.builder(InfiniteJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes());
CancelHandle cancelHandle = CancelHandle.create();
System.out.println("\nExecuting compute job...");
CompletableFuture<Void> resultFuture = client.compute().executeAsync(jobTarget, job, null, cancelHandle.token());
System.out.println("\nCancelling compute job...");
cancelHandle.cancel();
try {
resultFuture.join();
} catch (CompletionException ex) {
System.out.println("\nThe compute job was cancelled: " + ex.getMessage());
}var cts = new CancellationTokenSource();
CancellationToken cancelToken = cts.Token;
IJobExecution<string> execution = await client.Compute.SubmitAsync(
JobTarget.AnyNode(await client.GetClusterNodesAsync()),
JobDescriptor.Of(new NodeNameJob()),
cancelToken);
cts.Cancel();Another way to cancel jobs is by using the SQL KILL COMPUTE command. The job id can be retrieved via the COMPUTE_JOBS system view.
Job Configuration
When jobs arrive at the destination node, they are submitted to a thread pool and scheduled for execution in random order.
However, you can change job ordering by configuring CollisionSpi.
The CollisionSpi interface provides a way to control how jobs are scheduled for processing on each node.
Ignite provides several implementations of the CollisionSpi interface:
-
FifoQueueCollisionSpi— simple FIFO ordering in multiple threads. This implementation is used by default; -
PriorityQueueCollisionSpi— priority ordering; -
JobStealingFailoverSpi— use this implementation to enable job stealing.
To enable a specific collision spi, change the IgniteConfiguration.collisionSpi property.
Job Priority
You can specify a job priority by setting the JobExecutionOptions.priority property. Jobs with a higher priority will be queued before jobs with lower priority (for example, a job with priority 4 will be executed before the job with priority 2).
JobDescriptor<Integer, String> lowPriorityJob = JobDescriptor.builder(LowPriorityJob.class)
.options(JobExecutionOptions.builder()
.priority(0)
.maxRetries(5)
.build())
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobDescriptor<Integer, String> highPriorityJob = JobDescriptor.builder(HighPriorityJob.class)
.options(JobExecutionOptions.builder().priority(1).build())
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes());var options = JobExecutionOptions.Default with { Priority = 1 };
IJobExecution<string> execution = await Client.Compute.SubmitAsync(
JobTarget.AnyNode(await Client.GetClusterNodesAsync()),
new JobDescriptor<string, string>("org.example.NodeNameJob", Options: options),
arg: "Hello");
string result = await execution.GetResultAsync();using namespace ignite;
compute comp = client.get_compute();
std::vector<cluster_node> nodes = client.get_nodes();
// Unit `unitName:1.1.1` contains NodeNameJob class.
auto job_desc = job_descriptor::builder("org.company.package.NodeNameJob")
.deployment_units({deployment_unit{"unitName", "1.1.1"}})
.build();
job_execution_options options{1, 0};
job_execution execution = comp.submit(job_target::any_node(nodes), job_desc, {std::string("Hello")}, std::move(options));
std::string result = execution.get_result()->get<std::string>();Job Retries
You can set the number the job will be retried on failure by setting the JobExecutionOptions.maxRetries property. If set, the failed job will be retried the specified number of times before moving to Failed state.
JobDescriptor<Integer, String> lowPriorityJob = JobDescriptor.builder(LowPriorityJob.class)
.options(JobExecutionOptions.builder()
.priority(0)
.maxRetries(5)
.build())
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobDescriptor<Integer, String> highPriorityJob = JobDescriptor.builder(HighPriorityJob.class)
.options(JobExecutionOptions.builder().priority(1).build())
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
JobTarget jobTarget = JobTarget.anyNode(client.cluster().nodes());var options = JobExecutionOptions.Default with { MaxRetries = 5 };
IJobExecution<string> execution = await Client.Compute.SubmitAsync(
JobTarget.AnyNode(await Client.GetClusterNodesAsync()),
new JobDescriptor<string, string>("org.example.NodeNameJob", Options: options),
arg: "Hello");
string result = await execution.GetResultAsync();using namespace ignite;
compute comp = client.get_compute();
std::vector<cluster_node> nodes = client.get_nodes();
// Unit `unitName:1.1.1` contains NodeNameJob class.
std::vector<deployment_unit> units{deployment_unit{"unitName", "1.1.1"}};
job_execution_options options{0, 5};
job_execution execution = comp.submit(nodes, units, NODE_NAME_JOB, {std::string("Hello")}, std::move(options));
std::string result = execution.get_result()->get<std::string>();Job Failover
GridGain 9 implements mechanics to handle issues that happen during job execution. The following situations are handled:
Worker Node Shutdown
If the worker node is shut down, the coordinator node will redistribute all jobs assigned to worker to other viable nodes. If no nodes are found, the job will fail and an exception will be sent to the client.
Coordinator Node Shutdown
If the coordinator node shuts down, all jobs will be cancelled as soon as the node detects that the coordinator is shut down. Note that some jobs may take a long time to cancel.
Client Disconnect
If the client disconnects, all jobs will be cancelled as soon as the coordinator node detects the disconnect. Note that some jobs may take a long time to cancel.
MapReduce Tasks
GridGain 9 provides an API for performing MapReduce operations in the cluster. This allows you to split your computing task between multiple nodes before aggregating the result and returning it to the user.
Understanding MapReduce Tasks
A MapReduce task must be executed on a node that has a deployed class implementing the MapReduceTask interface. This interface provides a way to implement custom map and reduce logic. A node that receives the task becomes a coordinator node, that will be responsible for both mapping tasks to other nodes, reducing their results and returning the final result to the client.
The class must implement two methods: splitAsync and reduceAsync.
The splitAsync() method should be implemented to create compute jobs based on input parameters and map them to worker nodes. The method receives the execution context and your task arguments and returns a completable future containing the list of the job descriptors that will be sent to the worker nodes.
The reduceAsync() method is called during the reduce step, when all the jobs have completed. The method receives a map from the worker node to the completed job result and returns the final result of the computation.
Creating a Mapper Class
All MapReduce jobs must be submitted to a node that has an appropriate class deployed. Below is an example of a map reduce job:
public static class PhraseWordLengthCountMapReduceTask implements MapReduceTask<String, String, Integer, Integer> {
/** {@inheritDoc} */
@Override
public CompletableFuture<List<MapReduceJob<String, Integer>>> splitAsync(
TaskExecutionContext taskContext,
String input) {
assert input != null;
var job = JobDescriptor.builder(WordLengthJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
List<MapReduceJob<String, Integer>> jobs = new ArrayList<>();
for (String word : input.split(" ")) {
jobs.add(
MapReduceJob.<String, Integer>builder()
.jobDescriptor(job)
.nodes(taskContext.ignite().cluster.nodes())
.args(word)
.build()
);
}
return completedFuture(jobs);
}
/** {@inheritDoc} */
@Override
public CompletableFuture<Integer> reduceAsync(TaskExecutionContext taskContext, Map<UUID, Integer> results) {
return completedFuture(results.values().stream()
.reduce(Integer::sum)
.orElseThrow());
}
}Executing a MapReduce Task
To execute the MapReduce task, you use one of the following methods:
-
submitMapReduce()- sends the MapReduce job to the cluster and returns theTaskExecutionobject that can be used to monitor or modify the compute task execution. -
executeMapReduceAsync()- sends the MapReduce job to the cluster in the cluster and gets the future for job execution results. -
executeMapReduce()- sends the job to the cluster and waits for the result of job execution.
The node that the MapReduce task is sent to must have a class implementing the MapReduceTask interface.
try (IgniteClient client = IgniteClient.builder().addresses("127.0.0.1:10800").build()) {
System.out.println("\nConfiguring map reduce task...");
TaskDescriptor<String, Integer> taskDescriptor = TaskDescriptor.builder(PhraseWordLengthCountMapReduceTask.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
System.out.println("\nExecuting map reduce task...");
String phrase = "Count characters using map reduce";
Integer result = client.compute().executeMapReduce(taskDescriptor, phrase);
System.out.println("\nTotal number of characters in the words is '" + result + "'.");
}ICompute compute = Client.Compute;
var taskDescriptor = new TaskDescriptor<string, string>("com.example.MapReduceNodeNameTask");
ITaskExecution<string> exec = await compute.SubmitMapReduceAsync(taskDescriptor, "arg");
string result = await exec.GetResultAsync();
Console.WriteLine(result);This API is not presently available for C++.Partition-Local Queries with MapReduce
You can also use PartitionDistribution in the split phase to dispatch one job per partition to its primary replica node. Each job receives the partition ID as its argument and queries only that partition’s rows using the __PARTITION_ID virtual SQL column.
/**
* MapReduce task that counts persons across all partitions of the {@code Person} table.
*
* <p>The split phase uses {@link PartitionDistribution#primaryReplicas()} to get the current primary replica node
* for each partition, then creates one {@link PartitionPersonCountJob} per partition targeted at that node.
* The reduce phase sums the per-partition counts.
*/
public static class PersonCountByPartitionTask implements MapReduceTask<Void, Long, Long, Long> {
/** {@inheritDoc} */
@Override
public CompletableFuture<List<MapReduceJob<Long, Long>>> splitAsync(
TaskExecutionContext taskContext,
Void input) {
// Run a SQL query to advance the node's observable timestamp tracker to the current
// server time. MapReduce jobs are submitted server-side using the node's own tracker
// (not the client's). Without this step, individual jobs may use a read timestamp
// that predates inserts committed by the client before the task was submitted.
try (ResultSet<SqlRow> rs = taskContext.ignite().sql().execute("SELECT COUNT(*) FROM Person")) {
while (rs.hasNext()) {
rs.next();
}
}
JobDescriptor<Long, Long> jobDescriptor = JobDescriptor.builder(PartitionPersonCountJob.class)
.units(new DeploymentUnit(DEPLOYMENT_UNIT_NAME, DEPLOYMENT_UNIT_VERSION))
.build();
Map<Partition, ClusterNode> primaryReplicas = taskContext.ignite().tables()
.table("Person")
.partitionDistribution()
.primaryReplicas();
List<MapReduceJob<Long, Long>> jobs = new ArrayList<>();
for (Map.Entry<Partition, ClusterNode> entry : primaryReplicas.entrySet()) {
jobs.add(MapReduceJob.<Long, Long>builder()
.jobDescriptor(jobDescriptor)
.nodes(Set.of(entry.getValue()))
.args(entry.getKey().id())
.build());
}
return completedFuture(jobs);
}
/** {@inheritDoc} */
@Override
public CompletableFuture<Long> reduceAsync(TaskExecutionContext taskContext, Map<UUID, Long> results) {
return completedFuture(results.values().stream().mapToLong(Long::longValue).sum());
}
}Each individual job filters rows to its assigned partition:
/**
* Job that counts persons in a single partition, identified by partition ID passed as the job argument.
*
* <p>The {@code __PARTITION_ID} virtual SQL column is used to filter rows to those belonging to the target
* partition. The partition ID is provided by {@link PersonCountByPartitionTask} during the split phase.
*/
public static class PartitionPersonCountJob implements ComputeJob<Long, Long> {
/** {@inheritDoc} */
@Override
public CompletableFuture<Long> executeAsync(JobExecutionContext context, Long partitionId) {
long count = 0;
try (ResultSet<SqlRow> rs = context.ignite().sql().execute(
null,
"SELECT COUNT(*) FROM Person WHERE __PARTITION_ID = ?",
partitionId
)) {
if (rs.hasNext()) {
count = rs.next().longValue(0);
}
}
return completedFuture(count);
}
}© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.