Getting Started with SQL
This guide walks you through using GridGain 9 SQL capabilities via the command-line interface. You’ll set up a distributed Apache GridGain cluster, create and manipulate the Chinook database (a sample database representing a digital media store), and learn to leverage GridGain’s powerful SQL features.
Prerequisites
-
Docker and Docker Compose installed on your system;
-
Basic familiarity with SQL;
-
Command-line terminal access;
-
8GB+ of available RAM for running the containers;
-
SQL directory with Chinook Database files downloaded.
Before Starting
This tutorial uses prepared files to streamline deployment. Make sure you have downloaded the required files:
Unpack the archive into a new folder, and place it and the docker compose file in the same directory where you will be running the Docker CLI commands. The tutorial expects these SQL files to be available and mounted to the container.
Setting Up a GridGain 9 Cluster
Before we can start using SQL, we need to set up a GridGain cluster. We will use Docker Compose to create a three-node cluster.
Starting the Cluster
Open a terminal in the directory containing the docker compose file docker-compose.yml file and start the cluster with Docker:
docker compose up -dThis command starts the cluster in detached mode. You should see startup messages from all three nodes. When they are ready, you will see messages indicating that the servers have started successfully.
docker compose up -d
[+] Running 4/4
✔ Network gridgain9_default Created
✔ Container gridgain9-node1-1 Started
✔ Container gridgain9-node2-1 Started
✔ Container gridgain9-node3-1 StartedYou can check that all containers are running with the following command:
docker compose psYou should see all three nodes with a "running" status.
Connecting to the Cluster Using GridGain CLI
Now we will connect to our running cluster using GridGain command-line interface (CLI).
Starting the CLI
In your terminal, run:
docker run --rm -it --network=gridgain9_default -v ./sql/:/opt/gridgain/downloads -v /opt/etc/license.json:/opt/gridgain/etc/license.json gridgain/gridgain9:9.1.25 cliThis starts an interactive CLI container connected to the same Docker network as our cluster and mounts a volume containing the sql files for the Chinook Database. When prompted, refuse the connection to the default node and connect to node1 by entering:
connect http://node1:10300You should see a message that you’re connected to http://node1:10300 and a note that the cluster is not initialized.
Initializing the Cluster
Before we can use the cluster, we need to initialize it:
cluster init --name=GridGain --license=/opt/gridgain/etc/license.json _________ _____ __________________ _____
__ ____/___________(_)______ /__ ____/______ ____(_)_______
_ / __ __ ___/__ / _ __ / _ / __ _ __ `/__ / __ __ \
/ /_/ / _ / _ / / /_/ / / /_/ / / /_/ / _ / _ / / /
\____/ /_/ /_/ \_,__/ \____/ \__,_/ /_/ /_/ /_/
GridGain CLI version 9.1.0
You appear to have not connected to any node yet. Do you want to connect to the default node http://localhost:10300? [Y/n] n
[disconnected]> connect http://node1:10300
Connected to http://node1:10300
The cluster is not initialized. Run cluster init command to initialize it.
[node1]> cluster init --name=GridGain --license=/opt/gridgain/etc/license.json
Cluster was initialized successfully
[node1]>Creating the Chinook Database Schema
Now that our cluster is running and initialized, we can start using SQL to create and work with data in GridGain. The Chinook database is a digital music store dataset, with tables for artists, albums, tracks, customers, and sales.
Entering SQL Mode
To start working with SQL, enter SQL mode in the CLI:
sqlYour prompt should change to sql-cli> indicating you’re now in SQL mode.
[node1]> sql
sql-cli>Creating Distribution Zones
Before we create tables, let’s set up distribution zones to control how our data is distributed and replicated across the cluster:
CREATE ZONE IF NOT EXISTS Chinook (REPLICAS 2) STORAGE PROFILES['default'];
CREATE ZONE IF NOT EXISTS ChinookReplicated (REPLICAS 3, PARTITIONS 25) STORAGE PROFILES['default'];These commands create two zones:
-
Chinook- Standard zone with 2 replicas for most tables; -
ChinookReplicated- Zone with 3 replicas for frequently accessed reference data.
Database Entity Relationship
Here’s the entity relationship diagram for our Chinook database:
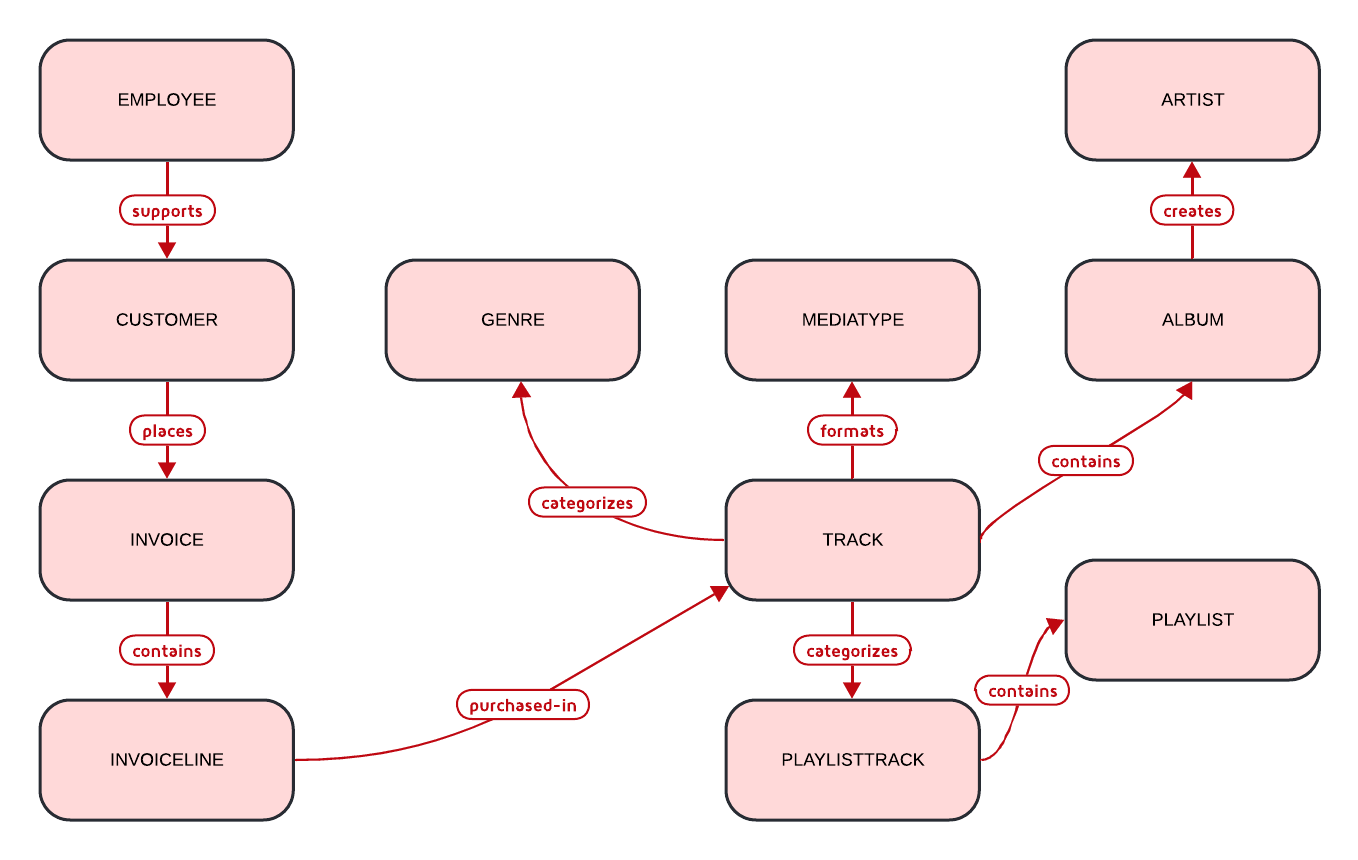
Creating Core Tables
Now let’s create the main tables for the Chinook database. We will start with the Artist and Album tables.
CREATE TABLE Artist (
ArtistId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (ArtistId)
) ZONE Chinook;
CREATE TABLE Album (
AlbumId INT NOT NULL,
Title VARCHAR(160) NOT NULL,
ArtistId INT NOT NULL,
ReleaseYear INT,
PRIMARY KEY (AlbumId, ArtistId)
) COLOCATE BY (ArtistId) ZONE Chinook;The COLOCATE BY clause in the Album table ensures that albums by the same artist are stored on the same nodes. This optimizes joins between Artist and Album tables by eliminating the need for network transfers during queries.
Next, let’s create the Genre and MediaType reference tables:
CREATE TABLE Genre (
GenreId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (GenreId)
) ZONE ChinookReplicated;
CREATE TABLE MediaType (
MediaTypeId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (MediaTypeId)
) ZONE ChinookReplicated;These reference tables are placed in the ChinookReplicated zone with 3 replicas because they contain static data that is frequently joined with other tables. Having a copy on each node improves read performance.
Now, let’s create the Track table, which references the Album, Genre, and MediaType tables:
CREATE TABLE Track (
TrackId INT NOT NULL,
Name VARCHAR(200) NOT NULL,
AlbumId INT,
MediaTypeId INT NOT NULL,
GenreId INT,
Composer VARCHAR(220),
Milliseconds INT NOT NULL,
Bytes INT,
UnitPrice NUMERIC(10,2) NOT NULL,
PRIMARY KEY (TrackId, AlbumId)
) COLOCATE BY (AlbumId) ZONE Chinook;Tracks are colocated by AlbumId, not by TrackId, because most queries join tracks with their albums. This colocation optimizes these common join patterns.
Let’s also create tables to manage customers, employees, and sales:
CREATE TABLE Employee (
EmployeeId INT NOT NULL,
LastName VARCHAR(20) NOT NULL,
FirstName VARCHAR(20) NOT NULL,
Title VARCHAR(30),
ReportsTo INT,
BirthDate DATE,
HireDate DATE,
Address VARCHAR(70),
City VARCHAR(40),
State VARCHAR(40),
Country VARCHAR(40),
PostalCode VARCHAR(10),
Phone VARCHAR(24),
Fax VARCHAR(24),
Email VARCHAR(60),
PRIMARY KEY (EmployeeId)
) ZONE Chinook;
CREATE TABLE Customer (
CustomerId INT NOT NULL,
FirstName VARCHAR(40) NOT NULL,
LastName VARCHAR(20) NOT NULL,
Company VARCHAR(80),
Address VARCHAR(70),
City VARCHAR(40),
State VARCHAR(40),
Country VARCHAR(40),
PostalCode VARCHAR(10),
Phone VARCHAR(24),
Fax VARCHAR(24),
Email VARCHAR(60) NOT NULL,
SupportRepId INT,
PRIMARY KEY (CustomerId)
) ZONE Chinook;
CREATE TABLE Invoice (
InvoiceId INT NOT NULL,
CustomerId INT NOT NULL,
InvoiceDate DATE NOT NULL,
BillingAddress VARCHAR(70),
BillingCity VARCHAR(40),
BillingState VARCHAR(40),
BillingCountry VARCHAR(40),
BillingPostalCode VARCHAR(10),
Total NUMERIC(10,2) NOT NULL,
PRIMARY KEY (InvoiceId, CustomerId)
) COLOCATE BY (CustomerId) ZONE Chinook;
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, TrackId)
) COLOCATE BY (TrackId) ZONE Chinook;Invoices are colocated by CustomerId and InvoiceLines are colocated by InvoiceId. This creates an efficient chain of locality: Customer → Invoice → InvoiceLine, optimizing queries that analyze customer purchase history.
Finally, let’s create the playlist-related tables:
CREATE TABLE Playlist (
PlaylistId INT NOT NULL,
Name VARCHAR(120),
PRIMARY KEY (PlaylistId)
) ZONE Chinook;
CREATE TABLE PlaylistTrack (
PlaylistId INT NOT NULL,
TrackId INT NOT NULL,
PRIMARY KEY (PlaylistId, TrackId)
) ZONE Chinook;Note that PlaylistTrack is not colocated with Track. This is a design decision that prioritizes playlist operations over joining with track details. In a real-world scenario, you might make a different colocation choice depending on your most common query patterns.
Verifying Table Creation
Let’s confirm that all our tables were created successfully:
SELECT * FROM system.tables WHERE schema = 'PUBLIC';This query checks the system tables to verify that our tables exist. You should see a list of all the tables we’ve created.
sql-cli> SELECT * FROM system.tables WHERE schema = 'PUBLIC';
╔═════════════╤═══════════════╤══════════╤═══════════════════╤═══════════════════╤═════════════════╤══════════════════════════╤═══════════╤═════════╤════════╤═══════════════╤════╤═════════════╤══════════════════════╤═══════════════════╗
║ SCHEMA_NAME │ TABLE_NAME │ TABLE_ID │ TABLE_PK_INDEX_ID │ ZONE_NAME │ STORAGE_PROFILE │ TABLE_COLOCATION_COLUMNS │ SCHEMA_ID │ ZONE_ID │ SCHEMA │ NAME │ ID │ PK_INDEX_ID │ COLOCATION_KEY_INDEX │ ZONE ║
╠═════════════╪═══════════════╪══════════╪═══════════════════╪═══════════════════╪═════════════════╪══════════════════════════╪═══════════╪═════════╪════════╪═══════════════╪════╪═════════════╪══════════════════════╪═══════════════════╣
║ PUBLIC │ ARTIST │ 22 │ 23 │ CHINOOK │ default │ ARTISTID │ 1 │ 20 │ PUBLIC │ ARTIST │ 22 │ 23 │ ARTISTID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ PLAYLIST │ 40 │ 41 │ CHINOOK │ default │ PLAYLISTID │ 1 │ 20 │ PUBLIC │ PLAYLIST │ 40 │ 41 │ PLAYLISTID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ PLAYLISTTRACK │ 42 │ 43 │ CHINOOK │ default │ PLAYLISTID, TRACKID │ 1 │ 20 │ PUBLIC │ PLAYLISTTRACK │ 42 │ 43 │ PLAYLISTID, TRACKID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ GENRE │ 26 │ 27 │ CHINOOKREPLICATED │ default │ GENREID │ 1 │ 21 │ PUBLIC │ GENRE │ 26 │ 27 │ GENREID │ CHINOOKREPLICATED ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ INVOICE │ 36 │ 37 │ CHINOOK │ default │ CUSTOMERID │ 1 │ 20 │ PUBLIC │ INVOICE │ 36 │ 37 │ CUSTOMERID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ INVOICELINE │ 38 │ 39 │ CHINOOK │ default │ TRACKID │ 1 │ 20 │ PUBLIC │ INVOICELINE │ 38 │ 39 │ TRACKID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ ALBUM │ 24 │ 25 │ CHINOOK │ default │ ARTISTID │ 1 │ 20 │ PUBLIC │ ALBUM │ 24 │ 25 │ ARTISTID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ CUSTOMER │ 34 │ 35 │ CHINOOK │ default │ CUSTOMERID │ 1 │ 20 │ PUBLIC │ CUSTOMER │ 34 │ 35 │ CUSTOMERID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ MEDIATYPE │ 28 │ 29 │ CHINOOKREPLICATED │ default │ MEDIATYPEID │ 1 │ 21 │ PUBLIC │ MEDIATYPE │ 28 │ 29 │ MEDIATYPEID │ CHINOOKREPLICATED ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ TRACK │ 30 │ 31 │ CHINOOK │ default │ ALBUMID │ 1 │ 20 │ PUBLIC │ TRACK │ 30 │ 31 │ ALBUMID │ CHINOOK ║
╟─────────────┼───────────────┼──────────┼───────────────────┼───────────────────┼─────────────────┼──────────────────────────┼───────────┼─────────┼────────┼───────────────┼────┼─────────────┼──────────────────────┼───────────────────╢
║ PUBLIC │ EMPLOYEE │ 32 │ 33 │ CHINOOK │ default │ EMPLOYEEID │ 1 │ 20 │ PUBLIC │ EMPLOYEE │ 32 │ 33 │ EMPLOYEEID │ CHINOOK ║
╚═════════════╧═══════════════╧══════════╧═══════════════════╧═══════════════════╧═════════════════╧══════════════════════════╧═══════════╧═════════╧════════╧═══════════════╧════╧═════════════╧══════════════════════╧═══════════════════╝Inserting Sample Data
Now that we have our tables set up, let’s populate them with sample data.
Adding Artists and Albums
Let’s start by adding some artists.
-
Exit the interactive sql mode by typing
exit;. -
Then, load the current store catalog from the sql data file.
sql --file=/opt/gridgain/downloads/current_catalog.sql;sql-cli> exit;
[node1]> sql --file=/opt/gridgain/downloads/current_catalog.sql
Updated 275 rows.
Updated 347 rows.Adding Genres and Media Types
Let’s populate our reference tables the same way:
sql --file=/opt/gridgain/downloads/media_and_genre.sql[node1]> sql --file=/opt/GridGain/downloads/media_and_genre.sql
Updated 25 rows.
Updated 5 rows.Adding Tracks
Now let’s add some tracks to our albums:
sql --file=/opt/gridgain/downloads/tracks.sql[node1]> sql --file=/opt/GridGain/downloads/tracks.sql
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 503 rows.Adding Employees and Customers
Let’s add some employee and customer data:
sql --file=/opt/gridgain/downloads/ee_and_cust.sql[node1]> sql --file=/opt/gridgain/downloads/ee_and_cust.sql
Updated 8 rows.
Updated 59 rows.Adding Invoices and Invoice Lines
Finally, let’s add some sales data:
sql --file=/opt/gridgain/downloads/invoices.sql[node1]> sql --file=/opt/gridgain/downloads/invoices.sql
Updated 412 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 240 rows.
Updated 18 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 1000 rows.
Updated 715 rows.Querying Data in GridGain SQL
Now that we have data in our tables, let’s run some SQL queries to explore the Chinook database.
Basic Queries
Let’s return to the sql-cli> and start with some simple SELECT queries:
sql-- Get all artists
SELECT * FROM Artist;
-- Get all albums for a specific artist
SELECT * FROM Album WHERE ArtistId = 3;
-- Get all tracks for a specific album
SELECT * FROM Track WHERE AlbumId = 133;Joins
Now let’s try some more complex queries with joins:
-- Get all tracks with artist and album information
SELECT
t.Name AS TrackName,
a.Title AS AlbumTitle,
ar.Name AS ArtistName
FROM
Track t
JOIN Album a ON t.AlbumId = a.AlbumId
JOIN Artist ar ON a.ArtistId = ar.ArtistId
LIMIT 10;This complex query uses multiple CTEs to achieve what would typically be done with the RANK() window function. We first count tracks per album, then determine the maximum track count per artist, and finally join these results to identify albums with the most tracks for each artist.
Data Manipulation in GridGain SQL
Let’s explore how to modify data using SQL in GridGain.
Understanding Distributed Updates
When you update data in a distributed database, the changes need to be coordinated across multiple nodes:
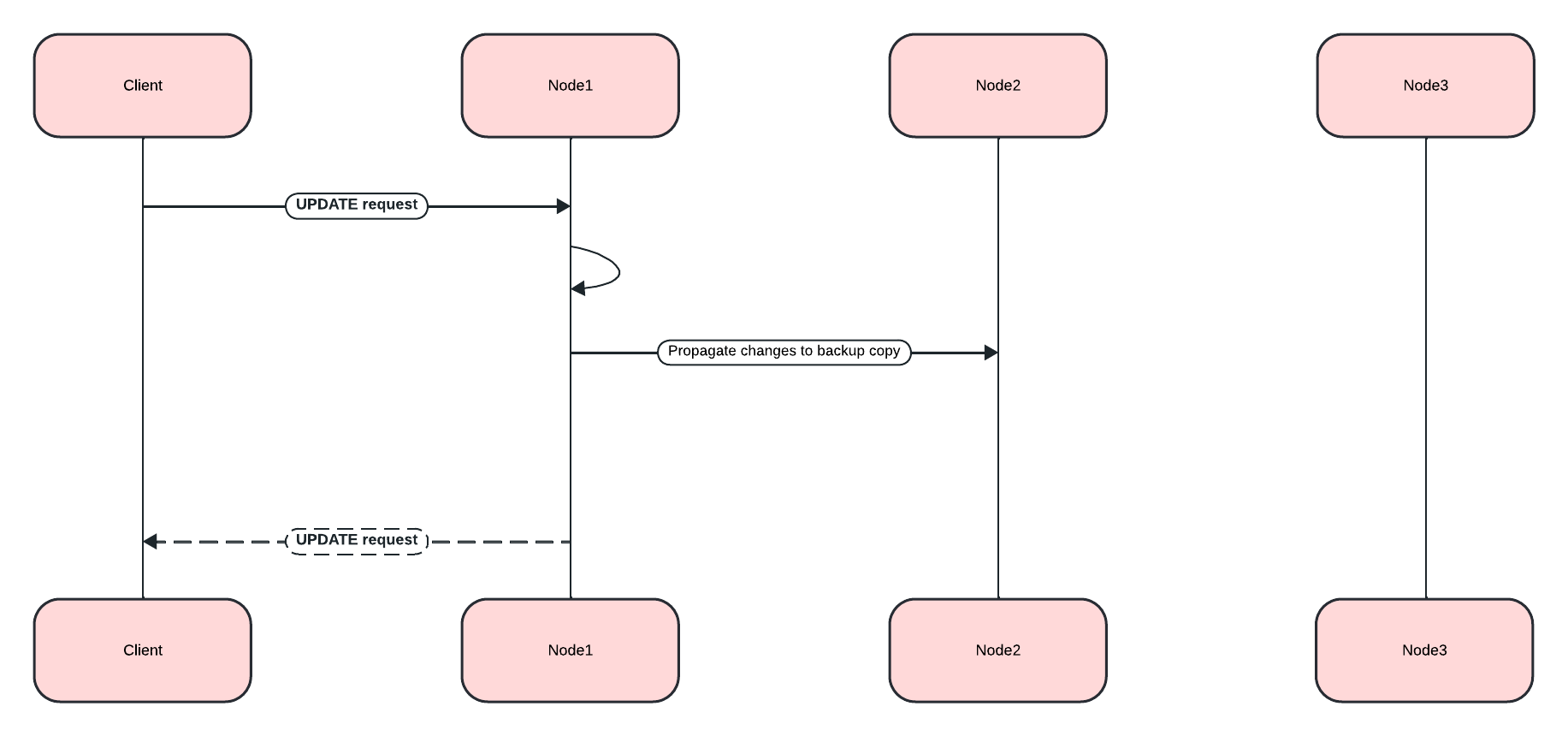
Inserting New Data
Let’s add a new artist and album:
-- Insert a new artist
INSERT INTO Artist (ArtistId, Name)
VALUES (276, 'New Discovery Band');
-- Insert a new album for this artist
INSERT INTO Album (AlbumId, Title, ArtistId, ReleaseYear)
VALUES (348, 'First Light', 276, 2023);
-- Verify the insertions
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;Updating Existing Data
Now let’s update some of our existing data:
-- Update the album release year
UPDATE Album
SET ReleaseYear = 2024
WHERE AlbumId = 348;
-- Update the artist name
UPDATE Artist
SET Name = 'New Discovery Ensemble'
WHERE ArtistId = 276;
-- Verify the updates
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;In a distributed database like GridGain, these updates are automatically propagated to all replicas. The primary copy is updated first, then the changes are sent to the backup copies on other nodes.
Deleting Data
Finally, let’s clean up by deleting the data we added:
-- Delete the album
DELETE FROM Album WHERE AlbumId = 348;
-- Delete the artist
DELETE FROM Artist WHERE ArtistId = 276;
-- Verify the deletions
SELECT * FROM Artist WHERE ArtistId = 276;
SELECT * FROM Album WHERE AlbumId = 348;Advanced SQL Features
Let’s explore some of GridGain’s more advanced SQL features.
Querying System Views
GridGain provides system views that let you inspect cluster metadata:
-- View all tables in the cluster
SELECT * FROM system.tables;
-- View all zones
SELECT * FROM system.zones;
-- View all columns for a specific table
SELECT * FROM system.table_columns WHERE TABLE_NAME = 'TRACK';System views provide important metadata about your cluster configuration. They are essential for monitoring and troubleshooting in production environments.
Creating Indexes for Better Performance
Let’s add some indexes to improve query performance:
-- Create an index on the Name column of the Track table
CREATE INDEX idx_track_name ON Track (Name);
-- Create a composite index on Artist and Album
CREATE INDEX idx_album_artist ON Album (ArtistId, Title);
-- Create a composite index on Track's AlbumId and Name columns to optimize joins with Album table
-- and to improve performance when filtering or sorting by track name within an album
CREATE INDEX idx_track_albumid_name ON Track(AlbumId, Name);
-- Create an index on Album Title to speed up searches and sorts by album title
CREATE INDEX idx_album_title ON Album(Title);
-- Create a composite index on InvoiceLine connecting TrackId and InvoiceId
-- This supports efficient queries that join InvoiceLine with Track while filtering by InvoiceId
CREATE INDEX idx_invoiceline_trackid_invoiceid ON InvoiceLine(TrackId, InvoiceId);
-- Create a hash index for lookups by email
CREATE INDEX idx_customer_email ON Customer USING HASH (Email);
-- Check index information
SELECT * FROM system.indexes;Indexes improve query performance, but come with maintenance costs. Each write operation must also update all indexes. Choose indexes that support your most common query patterns rather than indexing everything.
Creating a Dashboard Using SQL
Let’s create SQL queries that could be used for a music store dashboard. These queries could be saved and run periodically to generate reports.
Monthly Sales Summary
-- Monthly sales summary for the last 12 months
SELECT
CAST(EXTRACT(YEAR FROM i.InvoiceDate) AS VARCHAR) || '-' ||
CASE
WHEN EXTRACT(MONTH FROM i.InvoiceDate) < 10
THEN '0' || CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
ELSE CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
END AS YearMonth,
COUNT(DISTINCT i.InvoiceId) AS InvoiceCount,
COUNT(DISTINCT i.CustomerId) AS CustomerCount,
SUM(i.Total) AS MonthlyRevenue,
AVG(i.Total) AS AverageOrderValue
FROM
Invoice i
GROUP BY
EXTRACT(YEAR FROM i.InvoiceDate), EXTRACT(MONTH FROM i.InvoiceDate)
ORDER BY
YearMonth DESC;This query formats the year and month into a sortable string (YYYY-MM) while calculating several key business metrics.
Top Selling Genres
-- Top selling genres by revenue
SELECT
g.Name AS Genre,
SUM(il.UnitPrice * il.Quantity) AS Revenue
FROM
InvoiceLine il
JOIN Track t ON il.TrackId = t.TrackId
JOIN Genre g ON t.GenreId = g.GenreId
GROUP BY
g.Name
ORDER BY
Revenue DESC;Sales Performance by Employee
-- Sales performance by employee
SELECT
e.EmployeeId,
e.FirstName || ' ' || e.LastName AS EmployeeName,
COUNT(DISTINCT i.InvoiceId) AS TotalInvoices,
COUNT(DISTINCT i.CustomerId) AS UniqueCustomers,
SUM(i.Total) AS TotalSales
FROM
Employee e
JOIN Customer c ON e.EmployeeId = c.SupportRepId
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY
e.EmployeeId, e.FirstName, e.LastName
ORDER BY
TotalSales DESC;Top 20 Longest Tracks with Genres
-- Top 20 longest tracks with genre information
SELECT
t.trackid,
t.name AS track_name,
g.name AS genre_name,
ROUND(t.milliseconds / (1000 * 60), 2) AS duration_minutes
FROM
track t
JOIN genre g ON t.genreId = g.genreId
WHERE
t.genreId < 17
ORDER BY
duration_minutes DESC
LIMIT
20;Customer Purchase Patterns by Month
-- Customer purchase patterns by month
SELECT
c.CustomerId,
c.FirstName || ' ' || c.LastName AS CustomerName,
CAST(EXTRACT(YEAR FROM i.InvoiceDate) AS VARCHAR) || '-' ||
CASE
WHEN EXTRACT(MONTH FROM i.InvoiceDate) < 10
THEN '0' || CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
ELSE CAST(EXTRACT(MONTH FROM i.InvoiceDate) AS VARCHAR)
END AS YearMonth,
COUNT(DISTINCT i.InvoiceId) AS NumberOfPurchases,
SUM(i.Total) AS TotalSpent,
SUM(i.Total) / COUNT(DISTINCT i.InvoiceId) AS AveragePurchaseValue
FROM
Customer c
JOIN Invoice i ON c.CustomerId = i.CustomerId
GROUP BY
c.CustomerId, c.FirstName, c.LastName,
EXTRACT(YEAR FROM i.InvoiceDate), EXTRACT(MONTH FROM i.InvoiceDate)
ORDER BY
c.CustomerId, YearMonth;Performance Tuning with Colocated Tables
One of the key advantages of GridGain is its ability to optimize joins through data colocation. Let’s explore this with our existing colocated tables.
Colocated Queries
Let’s start by looking at a query where there is a mismatch in the colocation strategy.
--This is an example of poorly created table.
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, InvoiceId)
) COLOCATE BY (InvoiceId) ZONE Chinook;If we create the InvoiceLine table to be colocated by InvoiceId, we end up with a mismatch for our query.
-
Album is colocated by ArtistId
-
Track is colocated by AlbumId
-
InvoiceLine is colocated by InvoiceId
This means that when you run a query joining InvoiceLine, Track, and Album, the data might be spread across different nodes because they’re colocated on different keys. Our query is looking for invoice ID 1, then joining with Track and Album, but these tables are colocated on different keys.
EXPLAIN PLAN FOR
SELECT
il.InvoiceId,
COUNT(il.InvoiceLineId) AS LineItemCount,
SUM(il.UnitPrice * il.Quantity) AS InvoiceTotal,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
InvoiceLine il
JOIN Track t ON il.TrackId = t.TrackId
JOIN Album a ON t.AlbumId = a.AlbumId
WHERE
il.InvoiceId = 1
GROUP BY
il.InvoiceId, t.Name, a.Title;╔═════════════════════════════════════════════════════════════════════════════╗
║ PLAN ║
╠═════════════════════════════════════════════════════════════════════════════╣
║ Project ║
║ fields: [INVOICEID, LINEITEMCOUNT, INVOICETOTAL, TRACKNAME, ALBUMTITLE] ║
║ exprs: [INVOICEID, LINEITEMCOUNT, INVOICETOTAL, TRACKNAME, ALBUMTITLE] ║
║ est. row count: 9955526 ║
║ ColocatedHashAggregate ║
║ group: [INVOICEID, TRACKNAME, ALBUMTITLE] ║
║ aggs: [COUNT(), SUM($f4)] ║
║ est. row count: 9955526 ║
║ Project ║
║ fields: [INVOICEID, TRACKNAME, ALBUMTITLE, $f4] ║
║ exprs: [INVOICEID, NAME, TITLE, *(UNITPRICE, QUANTITY)] ║
║ est. row count: 20400668 ║
║ MergeJoin ║
║ condition: =(TRACKID0, TRACKID) ║
║ joinType: inner ║
║ leftCollation: [TRACKID ASC] ║
║ rightCollation: [NAME ASC] ║
║ est. row count: 20400668 ║
║ HashJoin ║
║ condition: =(ALBUMID, ALBUMID0) ║
║ joinType: inner ║
║ est. row count: 182331 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 3503 ║
║ Sort ║
║ collation: [TRACKID ASC] ║
║ est. row count: 3503 ║
║ TableScan ║
║ table: [PUBLIC, TRACK] ║
║ fields: [TRACKID, NAME, ALBUMID] ║
║ est. row count: 3503 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 347 ║
║ TableScan ║
║ table: [PUBLIC, ALBUM] ║
║ fields: [ALBUMID, TITLE] ║
║ est. row count: 347 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 746 ║
║ Sort ║
║ collation: [TRACKID ASC] ║
║ est. row count: 746 ║
║ IndexScan ║
║ table: [PUBLIC, INVOICELINE] ║
║ index: IDX_INVOICELINE_INVOICE_TRACK ║
║ type: SORTED ║
║ searchBounds: [ExactBounds [bound=1], null] ║
║ filters: =(INVOICEID, 1) ║
║ fields: [INVOICEID, TRACKID, UNITPRICE, QUANTITY] ║
║ collation: [INVOICEID ASC, TRACKID ASC] ║
║ est. row count: 746 ║
╚═════════════════════════════════════════════════════════════════════════════╝Key Observations in the Execution Plan
ColocatedHashAggregate Operation: The plan uses a ColocatedHashAggregate operation, which indicates GridGain recognizes that portions of the aggregation can happen on colocated data before results are combined. This reduces network transfer during the GROUP BY operation.
Exchange Operations: Several Exchange(distribution=[single]) operations appear in the plan, indicating data movement between nodes is still necessary. These operations are applied to the Album table, Track table, and InvoiceLine filtered results.
Join Implementation: The plan shows a combination of HashJoin and MergeJoin operations rather than nested loop joins. The optimizer has determined these join types are more efficient for the data volumes involved:
-
HashJoin for joining Track with Album
-
MergeJoin for joining the above result with InvoiceLine
Efficient Data Access: The query uses an IndexScan with the IDX_INVOICELINE_INVOICE_TRACK index rather than a full table scan on InvoiceLine. This provides:
-
Efficient filtering with
searchBounds: [ExactBounds [bound=1], null]for InvoiceId = 1 -
Pre-sorted results with
collation: [INVOICEID ASC, TRACKID ASC]
Row Count Estimation: There appears to be a significant increase in estimated row counts after joins:
-
Initial InvoiceLine filtered rows: 746
-
After HashJoin with Album: 182,331
-
After MergeJoin with Track: 20,400,668
Improved Cololocation Strategy
However, if we create the InvoiceLine table to be colocated by TrackId, we dramaticly optimize our query.
--This table was already created on an earlier step.
CREATE TABLE InvoiceLine (
InvoiceLineId INT NOT NULL,
InvoiceId INT NOT NULL,
TrackId INT NOT NULL,
UnitPrice NUMERIC(10,2) NOT NULL,
Quantity INT NOT NULL,
PRIMARY KEY (InvoiceLineId, TrackId)
) COLOCATE BY (TrackId) ZONE Chinook;And run EXPLAIN PLAN FOR again…
EXPLAIN PLAN FOR
SELECT
il.InvoiceId,
COUNT(il.InvoiceLineId) AS LineItemCount,
SUM(il.UnitPrice * il.Quantity) AS InvoiceTotal,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
Track t
JOIN Album a ON t.AlbumId = a.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
WHERE
il.InvoiceId = 1
GROUP BY
il.InvoiceId, t.Name, a.Title;╔═════════════════════════════════════════════════════════════════════════════╗
║ PLAN ║
╠═════════════════════════════════════════════════════════════════════════════╣
║ Project ║
║ fields: [INVOICEID, LINEITEMCOUNT, INVOICETOTAL, TRACKNAME, ALBUMTITLE] ║
║ exprs: [INVOICEID, LINEITEMCOUNT, INVOICETOTAL, TRACKNAME, ALBUMTITLE] ║
║ est. row count: 1 ║
║ ColocatedHashAggregate ║
║ group: [INVOICEID, TRACKNAME, ALBUMTITLE] ║
║ aggs: [COUNT(), SUM($f4)] ║
║ est. row count: 1 ║
║ Project ║
║ fields: [INVOICEID, TRACKNAME, ALBUMTITLE, $f4] ║
║ exprs: [INVOICEID, NAME, TITLE, *(UNITPRICE, QUANTITY)] ║
║ est. row count: 1 ║
║ MergeJoin ║
║ condition: =(ALBUMID0, ALBUMID) ║
║ joinType: inner ║
║ leftCollation: [ALBUMID ASC] ║
║ rightCollation: [TRACKID ASC] ║
║ est. row count: 1 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 1 ║
║ Sort ║
║ collation: [ALBUMID ASC] ║
║ est. row count: 1 ║
║ TableScan ║
║ table: [PUBLIC, ALBUM] ║
║ fields: [ALBUMID, TITLE] ║
║ est. row count: 1 ║
║ HashJoin ║
║ condition: =(TRACKID, TRACKID0) ║
║ joinType: inner ║
║ est. row count: 1 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 1 ║
║ IndexScan ║
║ table: [PUBLIC, TRACK] ║
║ index: IDX_TRACK_ALBUMID_NAME ║
║ type: SORTED ║
║ fields: [TRACKID, NAME, ALBUMID] ║
║ collation: [ALBUMID ASC, NAME ASC] ║
║ est. row count: 1 ║
║ Exchange ║
║ distribution: single ║
║ est. row count: 1 ║
║ TableScan ║
║ table: [PUBLIC, INVOICELINE] ║
║ filters: =(INVOICEID, 1) ║
║ fields: [INVOICEID, TRACKID, UNITPRICE, QUANTITY] ║
║ est. row count: 1 ║
╚═════════════════════════════════════════════════════════════════════════════╝Key Observations in the Execution Plan
ColocatedHashAggregate Operation: The plan uses a ColocatedHashAggregate operation, which indicates GridGain recognizes that portions of the aggregation can happen on colocated data before results are combined. This reduces network transfer during the GROUP BY operation.
Improved Row Count Estimates: Notice the dramatic improvement in row count estimates, which now show just 1 row at each step. This indicates the optimizer has much better statistics and understanding of the actual data distribution compared to the original plan that estimated millions of rows.
Join Implementation: The plan shows a combination of HashJoin and MergeJoin operations:
-
HashJoin for joining Track with InvoiceLine
-
MergeJoin for joining the above result with Album
Efficient Index Usage: The query now uses the composite index IDX_TRACK_ALBUMID_NAME on the Track table, providing:
-
Efficient sorted access by AlbumId and Name
-
Direct access to the fields needed for the join and select operations
Exchange Operations: While Exchange operations still appear in the plan, the estimated row counts are now minimal (just 1 row per exchange). This suggests much less data movement between nodes compared to the original plan where millions of rows were estimated to be transferred.
Colocation Impact
The substantial improvement in this execution plan demonstrates the power of proper data colocation in GridGain. By:
-
Structuring the query to join the tables in the optimal order (Track → Album → InvoiceLine)
-
Creating appropriate supporting indexes
-
Ensuring proper colocation between related tables
We’ve achieved a dramatic reduction in estimated row counts and data movement. The execution plan now shows streamlined operations with minimal row estimates at each step, indicating an efficient execution path that takes advantage of data locality.
This optimization approach highlights three key principles for optimal performance in distributed SQL databases:
-
Proper colocation of related data
-
Supporting indexes aligned with join patterns
-
Query structure that follows the colocation model
Cleaning Up
When you are finished with the GridGain SQL CLI, you can exit by typing:
exit;This will return you to the GridGain CLI. To exit the GridGain CLI, type:
exitTo stop the GridGain cluster, run the following command in your terminal:
docker compose downThis will stop and remove the Docker containers for your GridGain cluster.
Best Practices for GridGain SQL
To get the most out of GridGain SQL, follow these best practices:
Schema Design
-
Use appropriate colocation for tables that are frequently joined;
-
Choose primary keys that distribute data evenly across the cluster;
-
Design with query patterns in mind, especially for large-scale deployments.
Query Optimization
-
Create indexes for columns used in
WHERE,JOIN, andORDER BYclauses; -
Use the
EXPLAINstatement to analyze and optimize your queries; -
Avoid cartesian products and inefficient join conditions.
Transaction Management
-
Keep transactions as short as possible;
-
Do not hold transactions open during user think time;
-
Group related operations into a single transaction for atomicity.
Resource Management
-
Monitor query performance in production;
-
Consider partitioning strategies for very large tables;
-
Use appropriate data types to minimize storage requirements.
What’s Next
GridGain’s SQL capabilities make it a powerful platform for building distributed applications that require high throughput, low latency, and strong consistency. By following the patterns and practices in this guide, you can leverage GridGain SQL to build scalable, resilient systems.
Remember that GridGain is not just a SQL database—it’s a comprehensive distributed computing platform with capabilities beyond what we’ve covered here. As you become more comfortable with GridGain SQL, you may want to explore other features such as compute grid, machine learning, and stream processing.
Happy querying!
© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.