
In this article, we look at how transactions work in Apache Ignite. We begin with an overview of Ignite’s transaction architecture and then illustrate how tracing can be used to inspect transaction logic. Finally, we review a few simple examples that show how transactions work (and why they might not work).
Note that we assume you are familiar with the concept of key-value storage. If not, please refer to this page for a brief overview.
Necessary Digression: Apache Ignite Cluster
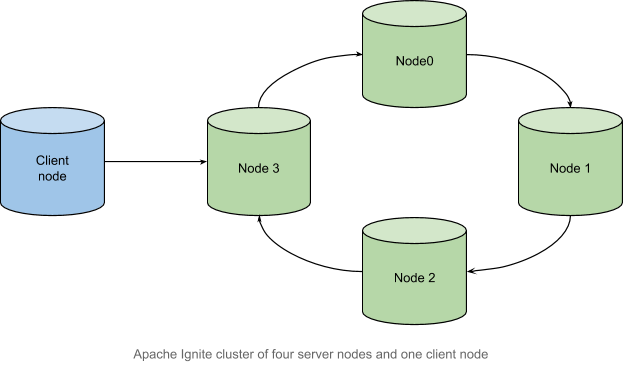
In Ignite, a cluster is a set of server and client nodes which are optional. The server nodes are combined into a ring-shaped logical structure, and the client node is connected to its corresponding server node, also known as the router node, according to Apache Ignite documentation. The primary difference between client and server nodes is that client nodes do not store data.
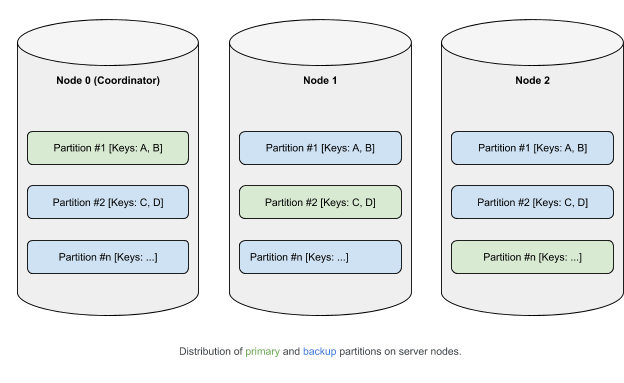
From a logical point of view, data belongs to the partitions, which, in accordance with an affinity function, are distributed among nodes (more details about data distribution in Ignite). Main (primary) partitions can have copies (backups).
How Transactions Work in Apache Ignite
The cluster architecture in Apache Ignite imposes a special requirement on the transaction mechanism: data consistency in a distributed environment.Therefore, data that resides in different nodes must change holistically in terms of ACID principles. A range of protocols enable you to satisfy such requirements . In Apache Ignite, an algorithm that is based on two-phase commit is used. The algorithm consists of two phases:
- Prepare
- Commit
Note that the details in the phases can differ, depending on the level of transaction isolation, the mechanism for taking locks, and a number of other parameters.
Let’s see how the commit phases take place. We’ll use the following transaction as an example:
Transaction tx = client.transactions().txStart(PESSIMISTIC, READ_COMMITTED);
client.cache(DEFAULT_CACHE_NAME).put(1, 1);
tx.commit();
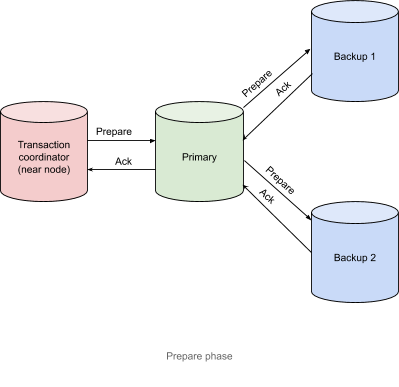
Prepare Phase
- Node (coordinator of transactions—near node in terms of Apache Ignite) sends a Prepare message to the nodes that contain the primary partitions for the keys that participate in the current transaction.
- Nodes with primary partitions send a Prepare message to the nodes that contain their respective backup partitions, if any, and take the necessary locks. In our example, there are two backup partitions.
- Nodes with backup partitions send Acknowledge messages to the nodes with primary partitions. Then, the primary partitions sent similar messages to the node that coordinates the transaction (near node).
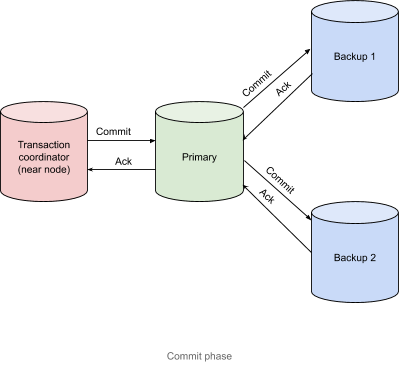
Commit Phase
After it receives Acknowledgement messages from the nodes that contain primary partitions, the transaction coordinator node sends a Commit message, as shown in the following diagram.
The transaction is considered complete the moment that the transaction coordinator has received all of the Acknowledgement messages.
From Theory to Practice
To examine the logic of a transaction, let’s turn to tracing, a way for you to monitor the execution of your application while it is running across the Ignite cluster. To enable tracing in Apache Ignite, perform these steps:
1. Enable the ignite-opencensus module and define OpenCensusTracingSpi as tracingSpi by using the cluster configuration:
XML
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="tracingSpi">
<bean class="org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi">
</property>
</bean>
Java
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setTracingSpi(new org.apache.ignite.spi.tracing.opencensus.OpenCensusTracingSpi());
2. Define a non-zero rate of transaction sampling:
Control.sh
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --sampling-rate 1
Java
ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().
withSamplingRate(SAMPLING_RATE_ALWAYS).build());
A few details about tracing configuration:
- Tracing configuration belongs to the class of experimental API and therefore requires enablement of the flag
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true". - Because we set the sampling-rate to 1, all transactions will be sampled. This setting is used to illustrate the material in question. It is not recommended for production.
- Tracing-parameter changes (except for setting SPI) are dynamic and do not require a restart of the cluster nodes. Later, the available setup parameters will be discussed in detail.
Once tracing is enabled, start a PESSIMISTIC, SERIALIZABLE transaction from a client node on a three-node cluster.
Transaction tx = client.transactions().txStart(PESSIMISTIC, SERIALIZABLE);
client.cache(DEFAULT_CACHE_NAME).put(1, 1);
tx.commit();
To view the tracing output, we will use GridGain Control Center. For a detailed overview of Control Center, please click here. From Control Center, we can look at the resulting tree of spans:
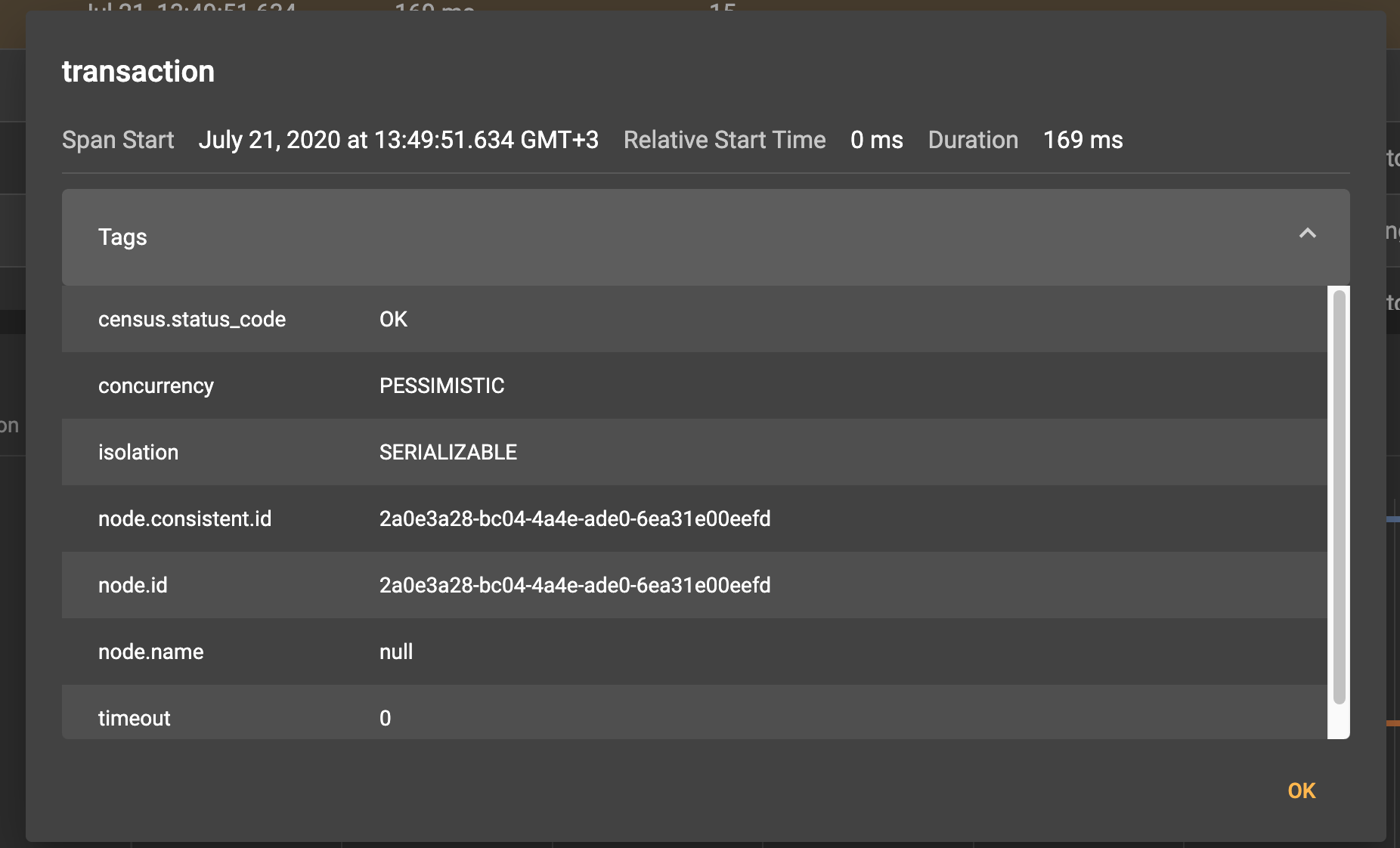
In the screenshot, we see that the root span transaction that was created at the beginning of the transactions().txStart call generated two general span groups:
- The lock taking machinery was initiated by the put() operation:
transactions.near.enlist.writetransactions.colocated.lock.map with substeps
transactions.commitis created at the moment whentx.commit()is called. As previously mentioned, in terms of Apache Ignite,transactions.commithas two phases—prepare and finish. The finish phase is identical to the commit phase, in classic terminology of a two-phase commit.
Now, let’s take a closer look at the prepare phase of the transaction. The prepare phase starts on the transaction coordinator node (near node, in terms of Apache Ignite) and produces the transactions.near.prepare span.
Once on the primary partition, the prepare request triggers the creation of the transactions.dht.prepare span. From within the span, prepare requests (tx.process.prepare.req) are sent to the backups. Then, the requests are processed by tx.dht.process.prepare.response and returned to the primary partition. The primary partition sends an Acknowledge ment message to the transaction coordinator and, thereby, a tx.near.process.prepare.response span is created.
The finish phase of this example is similar to the prepare phase.
When we select a span, we see the meta information that corresponds to the span:
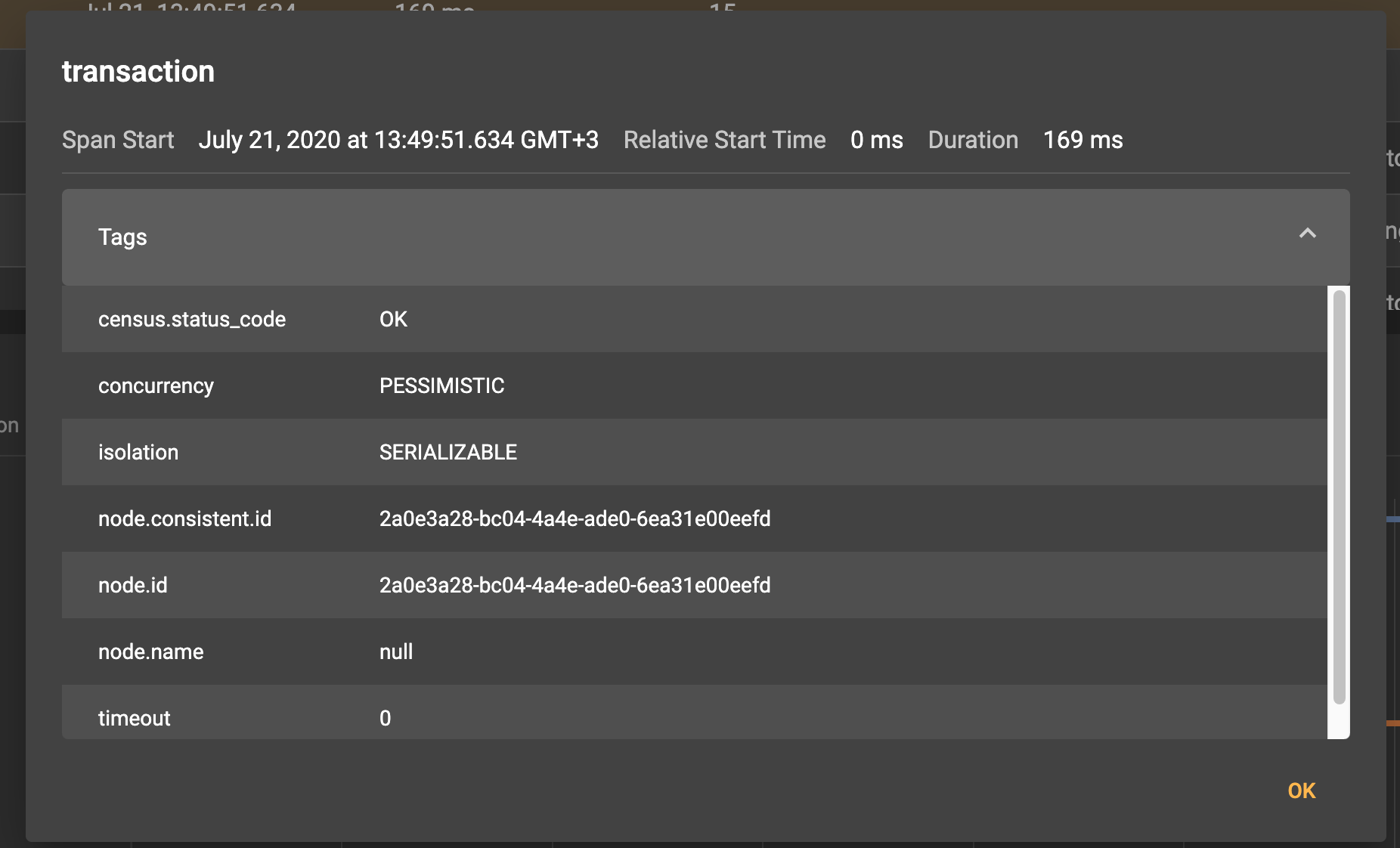
So, for example, we see that the root span transaction was created in the client node 00eefd.
We can also increase the granularity of the transaction tracing by allowing the communication protocol to be traced.
Control.sh
JVM_OPTS="-DIGNITE_ENABLE_EXPERIMENTAL_COMMAND=true" ./control.sh --tracing-configuration set --scope TX --included-scopes Communication --sampling-rate 1 --included-scopes COMMUNICATION
Java
ignite.tracingConfiguration().set(
new TracingConfigurationCoordinates.Builder(Scope.TX).build(),
new TracingConfigurationParameters.Builder().
withIncludedScopes(Collections.singleton(Scope.COMMUNICATION)).
withSamplingRate(SAMPLING_RATE_ALWAYS).build());
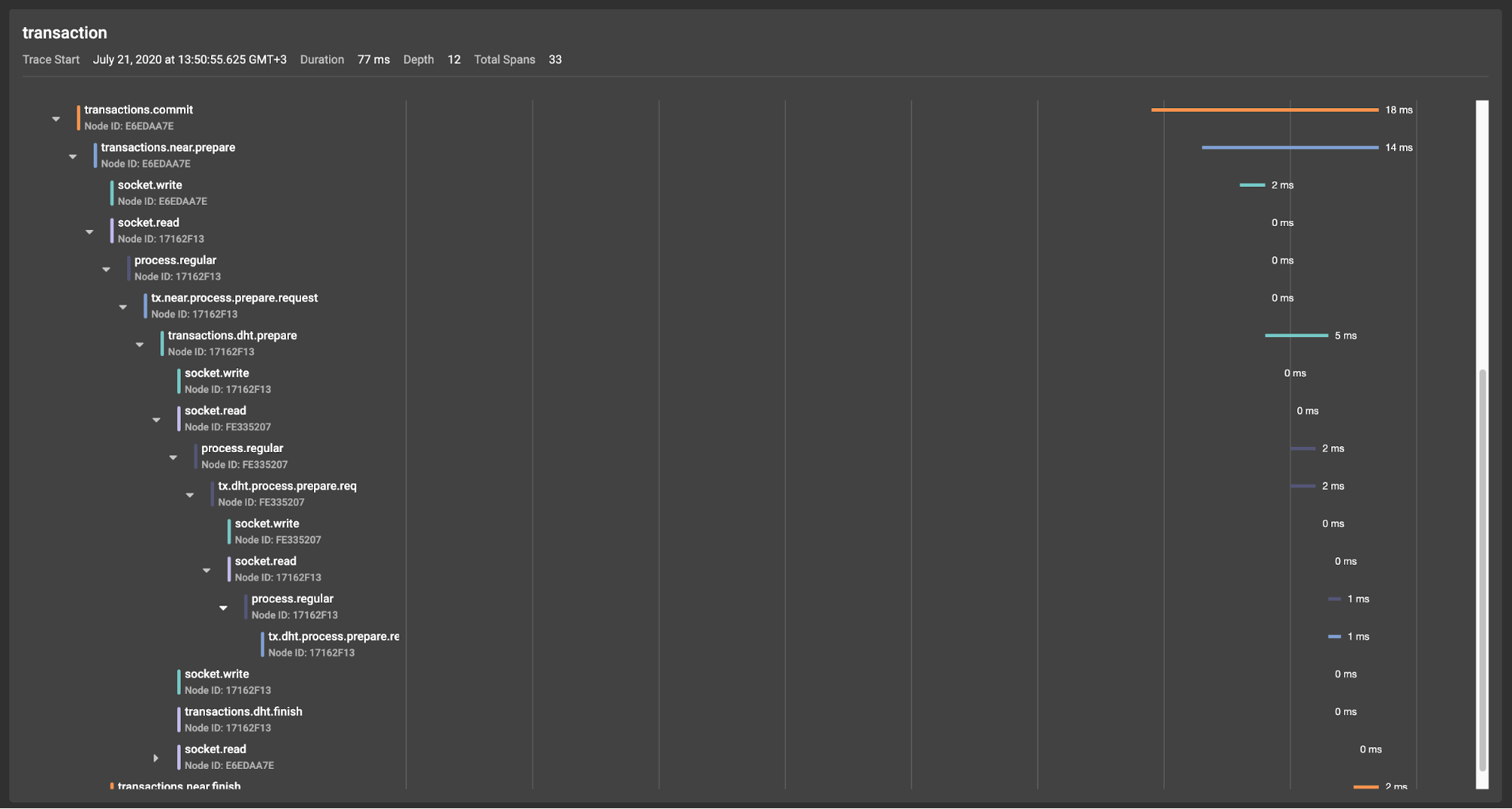
Now we can access information about the transmission of messages between the cluster nodes in the network. For example, such detailed tracing can help to answer the question of whether a problem is caused by variations of network communication. We will not dwell on the details. We will note only that all socket.write spans and socket.read spans relate to network communication between nodes.
Exception Handling and Crush Recovery
The implementation of the distributed transaction protocol in Apache Ignite is close to canonical and enables you to obtain the appropriate degree of data consistency, depending on the transaction isolation level that is selected. Obviously, the devil is in the details, and a large layer of logic remains beyond the scope of the material that we analyzed. For example, we have not considered the mechanisms of how transactions operate and recover (if the nodes that are participating in the transaction fail). We will fix this omission now.
We said previously that, in the context of transactions in Apache Ignite, there are three types of nodes:
- Transaction coordinator (near node)
- Node with the primary partition for the corresponding key (primary node)
- Nodes with backup partitions of keys (backup nodes)
Also, two phases of the transaction can be distinguished:
- Prepare
- Finish
Some simple calculations indicated that six variants of node failure need to be processed—from backup failure on the prepare phase to transaction coordinator failure on the finish phase. Let’s examine the variants in detail.
Backup Failure on Both Prepare and Finish Phases
This case does not require additional action. The data will be transferred to the new backup nodes separately as part of rebalancing from the primary node.
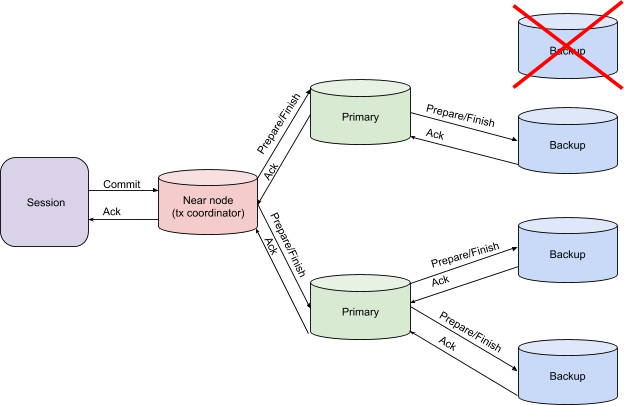
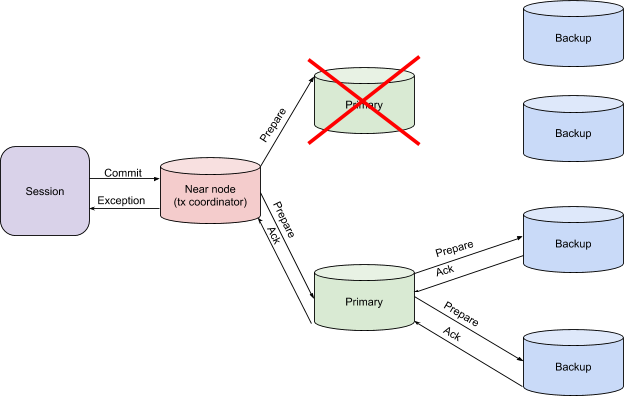
Primary Node Failure on the Prepare Phase
If there is a risk of receiving inconsistent data, the transaction coordinator throws an exception. The exception is a signal to transfer decision-making control, whether to restart a transaction or solve the problem in another way.
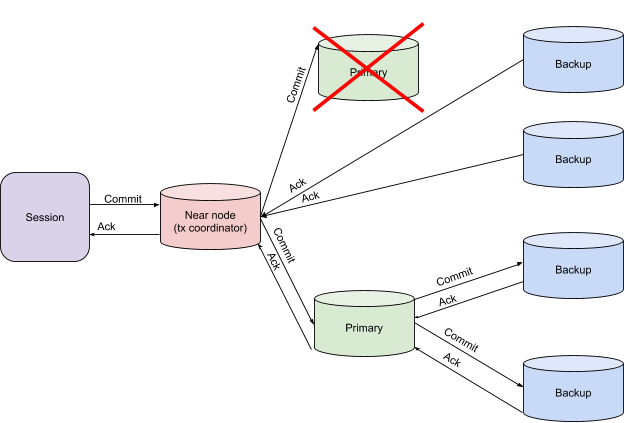
Primary Node Failure on the Finish Phase
In this case, the transaction coordinator waits for additional NodeFailureDetection messages. After the messages are received, if the data was written to the backup partitions, the coordinator can complete the transaction.
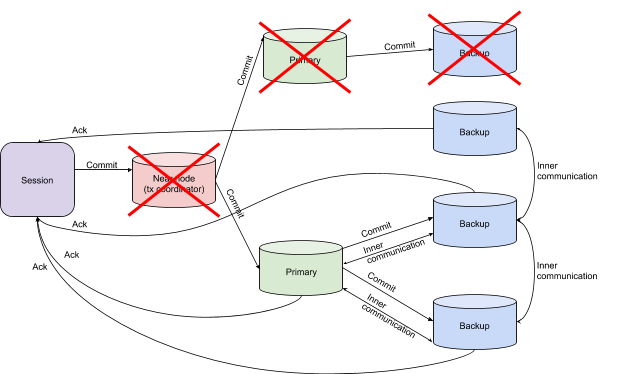
Transaction Coordinator Failure
The most intriguing case is the loss of transaction context. In this case, the primary and backup nodes exchange local transaction context, thereby restoring the global context. This action allows a decision to be made about the commit verification. If, for example, a node reports that it did not receive a Finish message, the transaction is rolled back.
Summary
In this blog post, we examined the transaction flow. We illustrated flow by using tracing, which shows the internal logic in detail. As you see, the implementation of transactions in Apache Ignite is similar to the classic concept of two-phase commit, with some transaction-performance tweaks that are related to the mechanism of taking locks and to the specifics of crush recovery and transaction timeout logic.