
Why is data distribution necessary?
As systems that require data storage and processing evolve, they often reach a point where either the amount of data exceeds the storage capacity, or the workload surpasses the capabilities of a single server.
In such situations, there are two useful data distribution solutions: data sharding and migrating to a distributed database. Both solutions involve using a set of nodes, which I will refer to as the "topology" throughout this discussion.
The problem of data distribution among the nodes of the topology can be described based on the following requirements:
- Algorithm: The algorithm should allow both the topology nodes and the front-end applications to determine unambiguously which node (or nodes) contains a specific object or key.
- Distribution uniformity: The more evenly the data is distributed among the nodes, the more balanced the workloads will be. It is assumed that all nodes have roughly equal resources.
- Minimal disruption: If a node fails and the topology needs to be changed, the distribution should only be affected for the data stored on the failed node. Additionally, when a new node is added to the topology, there should be no data swapping among the existing nodes.
By addressing these requirements, an effective and efficient data distribution system can be established within a distributed database or through data sharding.
Legacy Approach
The first two requirements mentioned above can be easily achieved. The commonly used approach, known as modulo N division, involves load balancing among servers that have the same functionality. In this approach, we assign a unique identifier to each server based on its position in the topology. To determine the server responsible for an object, we convert the object's key into a numerical value using a hash function and then calculate the remainder when dividing this value by the total number of servers (N).
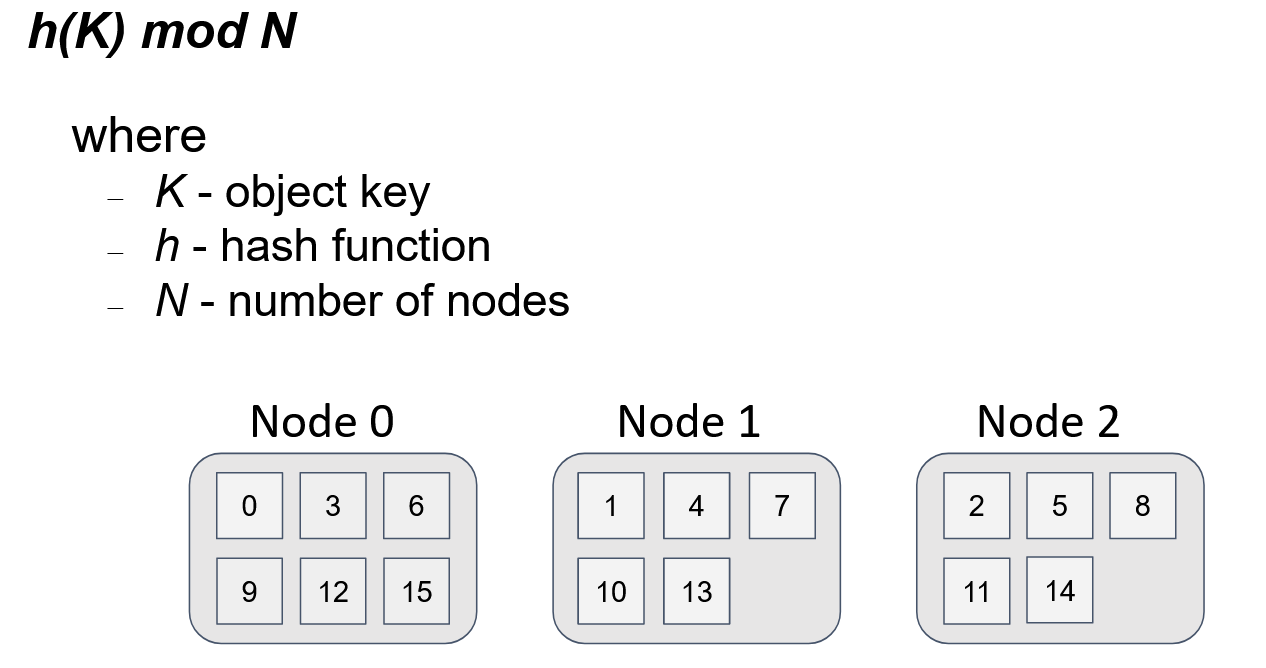
In the diagram below, we see the distribution of 16 keys among 3 servers. The distribution is uniform, and the algorithm for finding the server for an object is straightforward. If all servers in the topology use the same algorithm, every node will obtain the same result for a given key and the total number of servers (N).
However, what happens if we introduce a fourth server into the topology?
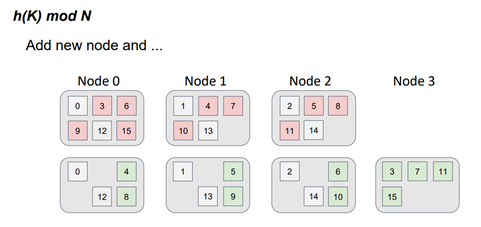
The function has now changed. Instead of dividing by 3, we divide by 4 and take the remainder. It's important to note that when the function changes, the distribution also changes.
The red dots represent the object positions in the three-server topology, while the green dots represent the object positions in the four-server topology. This color scheme is reminiscent of a file-diff operation, but in this case, we are dealing with servers instead of files. It is evident that not only did the data move to a new server, but there was also a data swap between the servers in the topology. In other words, there is parasitic traffic among the servers, and the requirement of minimal disruption is not met.
There are two ways to solve the data distribution problem while considering the requirements mentioned above: consistent hashing and the Highest Random Weight (HRW) algorithm, also known as rendezvous hashing. Let's explore these algorithms in more detail.
Consistent Hashing
The consistent hashing algorithm is based on the concept of mapping nodes and stored objects onto a shared identifier space. This allows us to compare seemingly different entities, such as objects and nodes.
To achieve this mapping, we use the same hash function for both the object keys and the node identifiers. We refer to the result of the hash function for a node as a "token". We represent the identifier space as a circle, where the minimum identifier value is adjacent to the maximum identifier value. To determine which node an object belongs to, we calculate the hash function value for the object's key and traverse the circle clockwise until we encounter a node's token. The direction of traversal is not important as long as it remains consistent.
The clockwise traversal is equivalent to performing a binary search over a sorted array of node tokens.
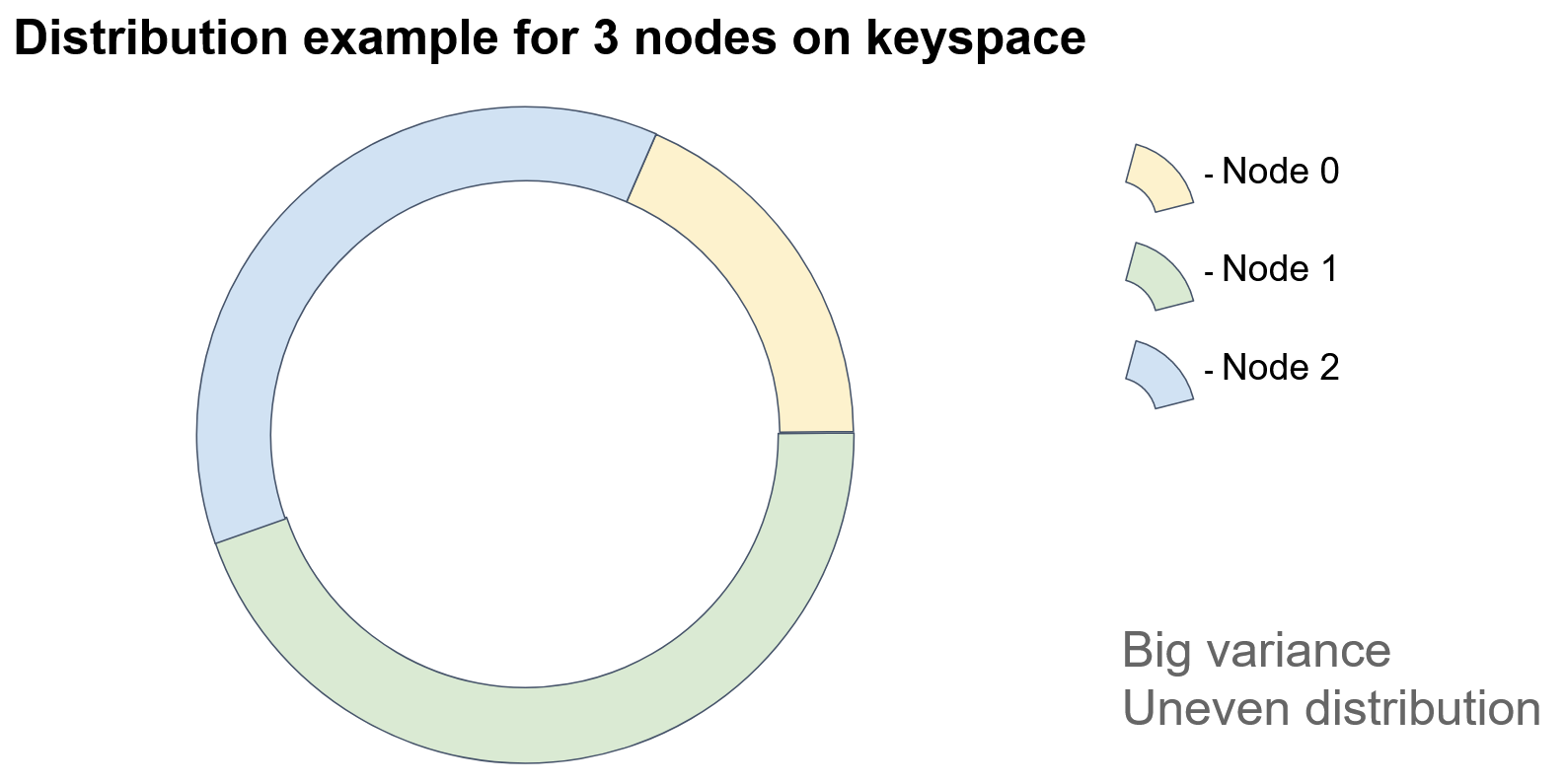
In the diagram, each colored sector represents an identifier space for which a particular node is responsible. If we add a node, then…
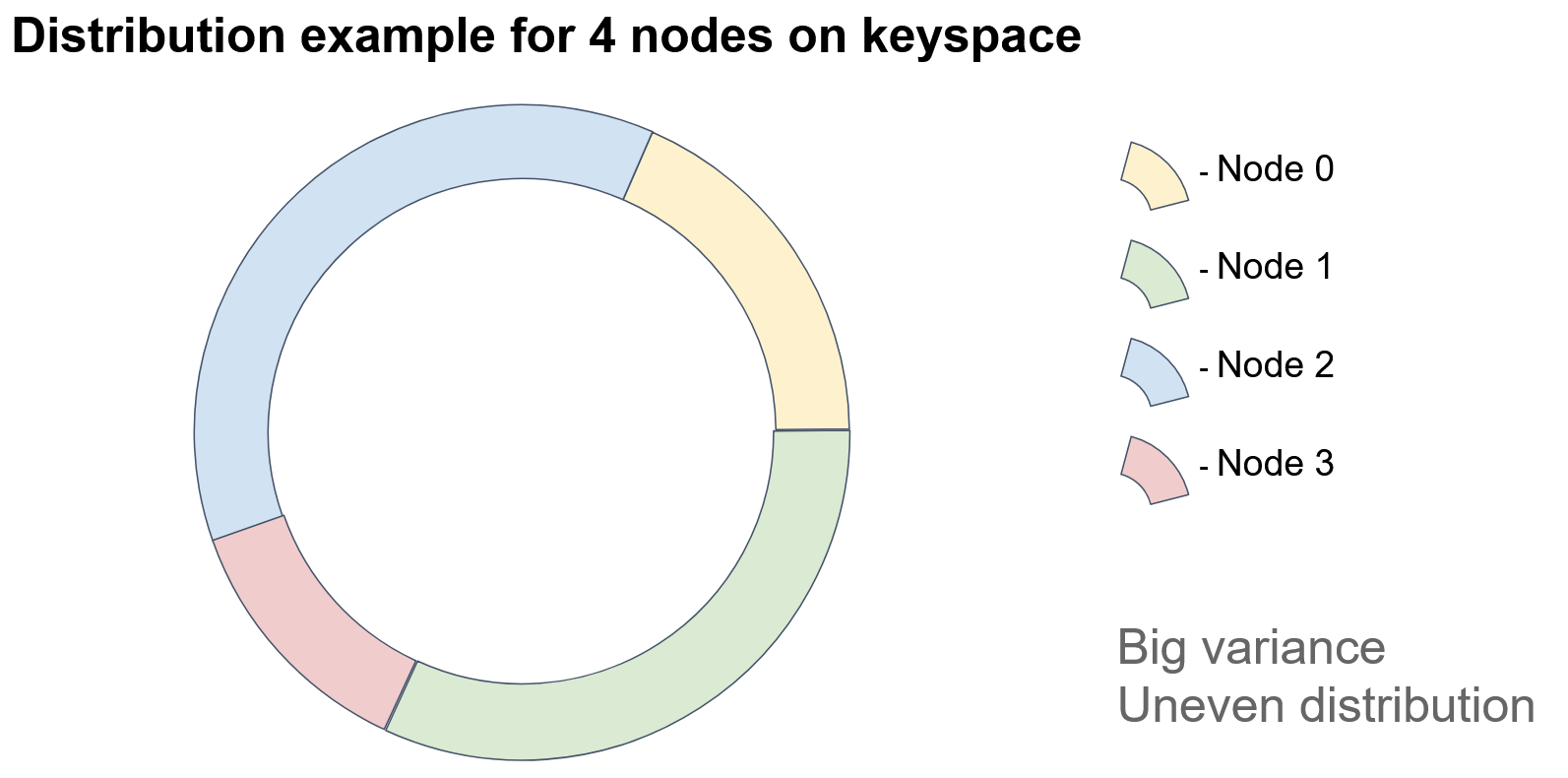
… one of the sectors is split into two parts, and the added node acquires the keys of one of the parts.
...one of the sectors is divided into two parts, and the new node takes over one of the parts.
In this example, Node 3 acquired some of the keys previously assigned to Node 1. As you can see, this approach can result in uneven distribution of objects among nodes due to its heavy reliance on node identifiers. How can we improve this?
One solution is to assign multiple tokens to each node, typically hundreds. For example, we can introduce a set of hash functions for each node, with one hash function per token. Alternatively, we can recursively apply a single hash function to a token and collect the results at each level of recursion. However, it is crucial to avoid collisions by ensuring that no two nodes have the same tokens.
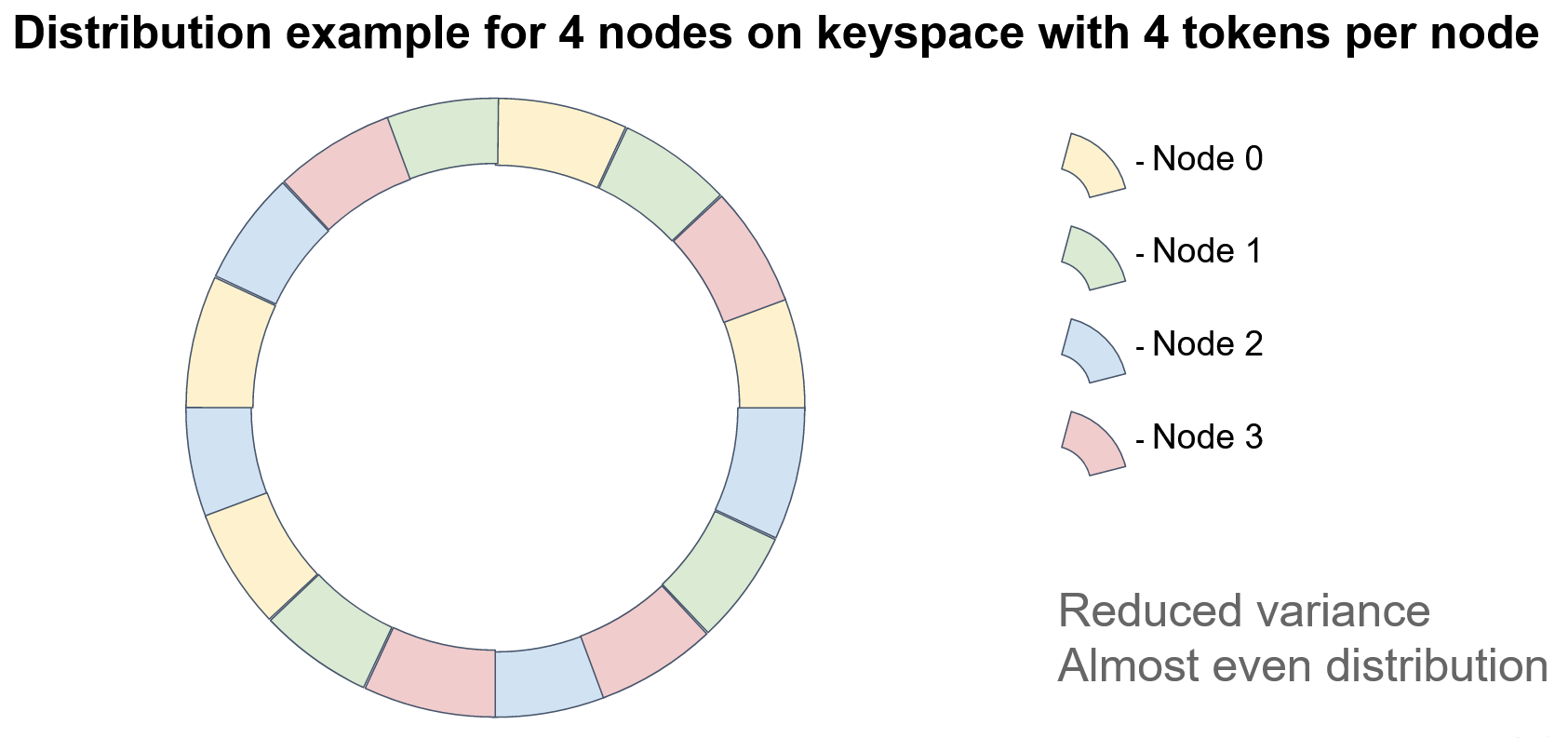
In this example, each node has four tokens. It is worth noting that if data integrity is a concern, we must store the keys on multiple nodes, creating replicas or backups. In consistent hashing, the next N-1 nodes on the circle serve as replicas, where N is the replication factor. The order of nodes should be defined relative to a specified token, such as the first token, as the positions of nodes may vary when multiple tokens are used on each node. As shown in the diagram, there is no clear pattern of node repetition.
The consistent hashing algorithm satisfies the minimal disruption requirement for topology modifications because the node ordering on the circle remains fixed. Therefore, the deletion of a node does not affect the order of the remaining nodes.
Rendezvous Hashing
The rendezvous hashing algorithm offers a simpler alternative to the consistent-hashing algorithm. It maintains the principle of ordering stability, but with a different approach. Instead of comparing nodes and objects to each other, rendezvous hashing focuses on the comparability of nodes for individual objects.
To achieve this, we utilize hashing once again. However, in rendezvous hashing, we mix the object identifier and the node identifier to create a hash that determines the weight of each node for a specific object. By performing this process for all nodes, we obtain a set of weights that allows us to sort the nodes. The node with the highest weight is responsible for storing the key. Since all nodes use the same input data, they will produce identical results, satisfying the requirement of consistency.

In the example with 4 nodes and 3 keys, an order is defined between three nodes for each of the four keys. The node with the highest weight, represented in yellow, is assigned as the responsible node for each respective key.
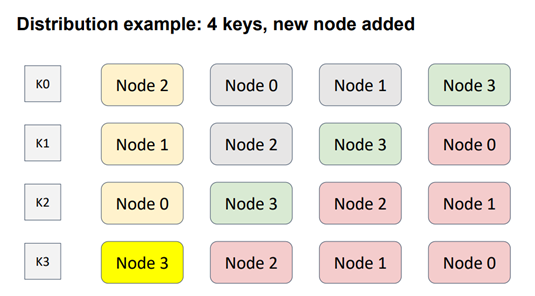
Now, let's consider adding a new node to the topology. In this case, Node 3 (shown in green) is added diagonally to cover all possible scenarios. As a result, the distribution of node weights for each key changes. The nodes shown in red have changed position, as their weights are lower than the weight of the newly added node. Consequently, this modification only affects one key, K3.

Next, let's explore the scenario of removing a node from the topology. Similar to consistent hashing, this modification only impacts one key, this time K1. The other key remains unaffected because the ordering relationships between node pairs remain unchanged. Therefore, the requirement of minimal disruption is met, ensuring that there is no unnecessary traffic between nodes.
Unlike consistent hashing, rendezvous hashing performs well without the need for additional steps such as tokens. If replication is supported, the subsequent nodes in the sorted list act as replicas for the object. The first replica node is followed by the second replica node, and so on.
In summary, rendezvous hashing offers a simpler approach with good performance and minimal disruption, making it an efficient choice for object-node mapping in distributed systems.
How Rendezvous Hashing Is Employed in Apache Ignite
Apache Ignite utilizes rendezvous hashing for data distribution. This is achieved through the affinity function, with rendezvous hashing being the default implementation.
It's important to note that Apache Ignite doesn't directly map stored objects to topology nodes. Instead, a concept called "partition" is introduced. A partition acts as both a container for objects and a replication unit. The number of partitions for a cache, which is equivalent to a traditional database table, is defined during configuration and remains constant throughout the cache's lifecycle.
By employing effective division by modulo, we can map objects onto partitions and then use rendezvous hashing to map the partitions onto nodes.
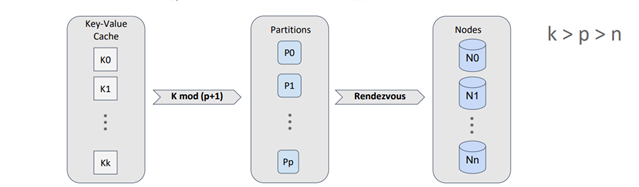
Since the number of partitions per cache is constant, we can calculate the distribution of partitions across the nodes once and cache the result. Each node independently calculates this distribution, but if the input data is the same, the distribution will also be the same. A partition can have multiple copies, referred to as "backups," with the primary partition being the master partition.
To achieve optimal key and partition distribution across nodes, it is important to ensure that the number of partitions is significantly greater than the number of nodes, and the number of keys is significantly greater than the number of partitions.
Caches in Ignite can be either partitioned or replicated. In a partitioned cache, the number of backups is specified during cache configuration. The primary and backup partitions are evenly distributed among the nodes. This type of cache is suitable for operational data processing as it ensures the best write performance, which is directly influenced by the number of backups.
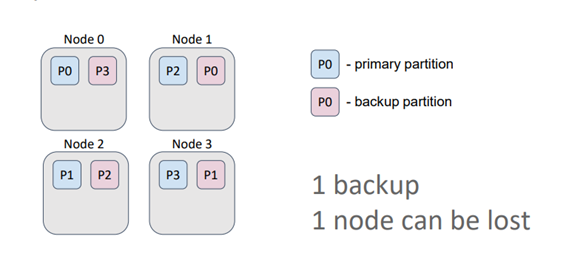
Generally, more backups result in more nodes confirming the key record. In this example, the cache has one backup. Therefore, even if a node is lost, all the data is retained since the primary partition and its backups are never stored on the same node.
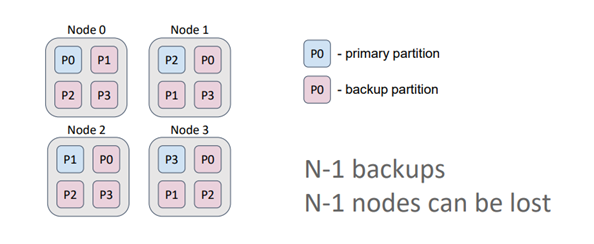
On the other hand, in a replicated cache, the number of backups is equal to the number of nodes minus one. As a result, each node contains copies of all partitions. This type of cache is ideal for data that is rarely modified, such as dictionaries, and guarantees high availability. Even if N-1 nodes (3 in this case) are lost, all the data is still retained. Additionally, by allowing data to be read from both primary partitions and backups, read performance is maximized in this configuration.
Data Colocation in Apache Ignite
Data colocation in Apache Ignite refers to the practice of storing multiple objects in the same location for improved performance. In this context, the objects are entities stored in the cache, and the location refers to a node. When objects with the same affinity key are distributed among partitions using the same affinity function, they are placed in the same partition and node. This approach is known as "affinity-based collocation" in Ignite. By default, the affinity key is the primary key of an object, but Ignite also allows the use of any object field as the affinity key.
Collocating data significantly reduces the amount of data transferred between nodes for computations or SQL queries, minimizing the number of network calls required to complete tasks. To illustrate this concept, let's consider the example of two entities in our data model: orders and order items. Multiple order items can correspond to one order. While the identifiers of orders and order items are independent, each order item has an external key that references the corresponding order. Suppose we need to perform a task that involves calculations on items belonging to a specific order.
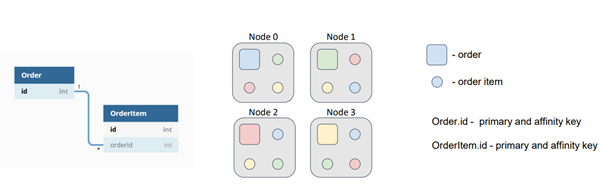
By default, orders and order items are distributed among nodes based on their primary keys, which are independent. In this scenario, the task is sent to the node where the target order resides, which then reads order items from other nodes or sends subtasks to retrieve the required data. This redundant network interaction can and should be avoided.
To address this issue, we can instruct Ignite to colocate the order items with the orders by using the external key as the affinity key and calculating the partition based on the chosen object's field. If both the Order and OrderItem caches use the same affinity function with the same parameters, the data will be collocated, eliminating the need for extensive network searches.
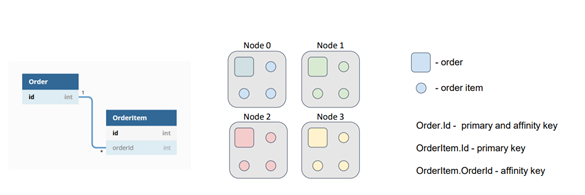
By implementing data colocation in Apache Ignite, we can optimize performance by minimizing network overhead and improving the efficiency of computations and SQL queries.
Affinity Function Configuration in Apache Ignite
In the current implementation, the affinity function is a parameter of the cache configuration. When instantiated, the affinity function takes the following arguments: number of partitions, number of backups (which is also a cache configuration parameter), backup filter, and the flag excludeNeighbors. These parameters cannot be modified. During execution, the affinity function uses the current cluster topology (i.e., the list of nodes in the cluster) to calculate the distribution of partitions among the nodes, as demonstrated in the previous examples using the rendezvous-hashing algorithm. The backup filter acts as a predicate that can prevent the affinity function from assigning a partition backup to a node if the predicate returns "false."
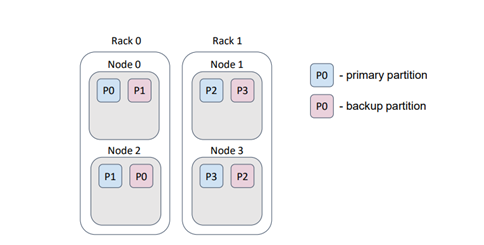
For instance, let's consider a scenario where our physical nodes (servers) are located in a data center on different racks. Typically, each rack has its own power supply. If a rack fails, we would lose the data stored on that rack.
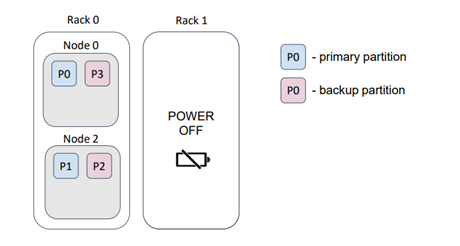
In this particular example, we lost half of the partitions. However, by providing an appropriate backup filter, the distribution changes to ensure that the loss of a rack does not result in data loss.
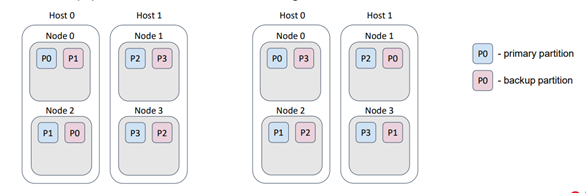
The flag excludeNeighbors serves a similar purpose as the backup filters, but it is specifically designed as a shortcut for a particular case. Often, multiple Ignite nodes are deployed on a single physical host. This situation is similar to the "racks in the data center" scenario, but now we want to prevent data loss caused by a host failure. This behavior can be achieved by implementing a backup filter. The excludeNeighbors flag is considered legacy and will be removed in the next major Ignite release.
Conclusion
To summarize, let's consider a scenario with 16 partitions distributed across 3 nodes. For simplicity, we assume that there are no backups for the partitions. A test was conducted to illustrate the data distribution.
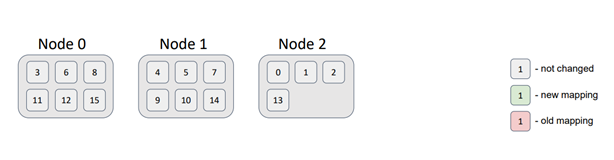
It is evident that the partition distribution is not uniform. However, as the number of nodes and partitions increases, the deviation decreases significantly. The crucial requirement is to ensure that the number of partitions exceeds the number of nodes. Currently, the default number of partitions in a partitioned Ignite cache is 1024.
Now, let's add a node to the topology.
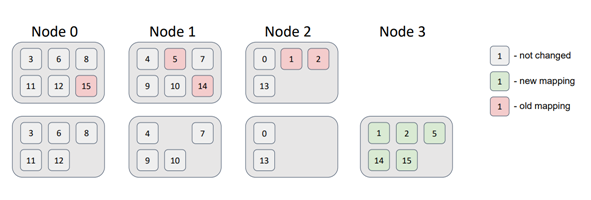
As a result, some partitions migrated to the new node. This satisfies the minimal disruption requirement, as the new node received partitions while the other nodes did not need to swap any.
Next, let's delete a node from the topology.
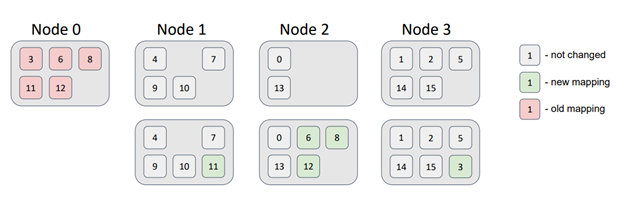
In this case, the partitions associated with Node 0 were distributed among the remaining nodes in the topology without violating the data distribution requirements.
As seen, simple methods can address complex problems. These solutions are commonly employed in most distributed databases and perform reasonably well. However, it's important to note that these solutions are randomized, leading to less than perfect distribution uniformity. The question of whether we can improve uniformity, maintain performance, and meet all data distribution requirements remains open.
This updated post was originally written by Andrey Gura.