
Note: This is the third and final post in the blog series: Continuous Machine Learning at Scale With Apache Ignite. For post 1 click here and for post 2 click here.
In my first post, I introduced Apache® Ignite™ machine learning and explained how it delivers large-scale, distributed, machine-learning (ML) workloads. In my second post, I discussed the Apache Ignite model-building stages. The stages consist of (a) extracting the training dataset from the operational online data, (b) preprocessing the dataset into training-dataset “vectorized” format, and (c) training and evaluating the trained predictive model before it is moved into production. The output from the model-building steps are trained models that are packaged as Java objects. The Java objects are then called directly during operational data transactions: the data transactions provide input values to the Model objects, and the Models return predicted output values to the transactions either in real time or in batch mode.
This predictive process, and how it works with online OLTP processes, can be viewed as a combination of any of the following examples. Of course, the examples are my own, and arbitrary on my part, but, hopefully, they compare with how you want to do runtime predictions:
- Real time: Each new OLTP transaction makes a call to the Ignite model and, before completion, waits for an output value.
- Near real time: Each new OLTP transaction is placed into a small “fast cache” and is processed as part of a group, with output values expected before completion of the transaction.
- Fast batch: The OLTP transactions are completed without direct feedback from the Ignite model. However, the transactions are read from Ignite data and then compared to the Ignite model as part of a running process such as workflow management. The predicted value can be used for workflow prioritization.
- Batch: Transactions can be part of a very large dataset. The dataset is run periodically and is considered to be a long-running, back-end process that does not expect a sub-second latency response. However, even the “batch” transactions can enjoy reduced times, as they run from Ignite’s fast, parallel processing.
Now, let’s talk first about some application examples and then about some ways you can leverage Apache Ignite.
Leveraging Ignite for ML Pipeline Operations: Prediction, Measuring, Online Retraining
So far, when referencing the term “continuous learning at scale,” I’ve stressed the “scale” aspect. I haven’t yet elaborated on the “continuous” aspect. So, the word “continuous” refers to the potential that you have with Ignite to look at continuous transactions—before and after, with the time duration and batch size that make sense for your application, without having to do ETL batch jobs.
The following are examples for “fast-batch,” back-office predictions. Again, the transactions may not require sub-second response, but they do require fast processing to deliver fast workflows:
- In a claims adjudication process, you don’t need to perform the predictive transaction in real time. However, if you can perform the claims-processing workflow quickly on small batches of still-active case data, then you can speed up intelligent prioritization and, thus, improve value capture from the claims.
- In some fraud-detection cases, the fraud activity is well-understood in terms of business rules and can be pushed “out to the edge” for real time. However, in other cases, because the threat profile changes over time, you need to look backward at least hourly , to update the prediction model for new cases.
On the other hand, the following are examples of real-time, per-transaction predictive responses:
- If you need to guess the likelihood of a patient’s readmission, before the patient is discharged, (near) real-time predictions on a frequent basis make a lot of sense.
- In a retail environment, whether in-store or e-commerce, a quick turnaround time per transaction or per small transaction set is needed.
Leveraging Apache Ignite for Prediction
So, the use of Apache Ignite clusters—with the high performance of co-located transactions, training, and predictions—makes it much easier to set up processes that look at transactions before and after the prediction and perform the processes together in a horizontally scalable fashion:
- Quick, predictive responses can make offerings, recommendations, and other predictions in time to influence customer behavior at the time of contact.
- With frequent and timely predictive performance tracking of the model, you do not have to wait for a lengthy extract of transactions with actuals and then move to another system to use slow ETL in order to see to what degree predictions match actuals.
- The ML processor can very quickly ascertain when the predictions are moving out of acceptable range. Consider that the model gets out of date not because it has lost predictive quality. Rather, consider that the behavior patterns of the operational data are changing (perhaps due to seasonal changes, product changes, marketing events, social media campaigns, many more).
The following diagram shows one example (of many possible) of how you can position side-by-side operational OLTP workloads and an ML workload “handler” that does predictions and tracks predictive performance(no need for ETL to and back again from a dedicated ML system):
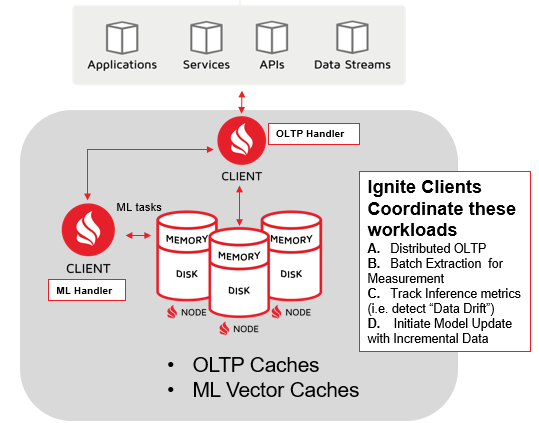
For the online-processing OLTP processes (I labeled this Ignite node as “OLTP handler” to indicate that it focuses on high-speed data management via queries, updates, deletes, and so on), the following statements apply:
- Ignite clients perform on-going transaction processing (using any combination of SQL, key/value, streaming, and other OLTP workloads, based on application requirements).
- The transactions are guided individually or in small groups, with predictive values that are provided from the side-by-side ML “handler” processor, which focuses on receiving inputs from the OLTP process and then responding with a predicted output.
For the ML “handlers” (Ignite nodes that contain the online Models; these nodes can join the cluster whenever needed, send co-located processing tasks to the cluster, and access the co-located online OLTP caches) the following statements apply:
- ML Ignite nodes are responsible for the “continuous” aspect of predictive analytic, consisting of predicting OLTP transaction values, tracking how often the predictions are correct, and then model updating when predictions become less accurate
- At times in the business cycle, for example new product launches, the full training cycle may need to be performed: data extraction into vectorized form, doing preprocessing, and performing a retraining cycle on newer business data. As mentioned in previous articles, the ML nodes leverage the Apache Ignite parallel processing architecture to perform these steps at scale where the OLTP data already resides, and eliminating costly ETL/ELT processing and time delays.
- The specific workflows needed to ascertain model applicability and performance over time often require best of breed analytical tools such as Python and other workbenches. Apache Ignite ML nodes easily support these external data science and tools in real time fashion with standard APIs.
How you go about co-deploying your predictive model to work effectively with your incoming transactions depends on your specific use-case. Apache Ignite ML models use some variant of the MyModel.predict() method for transactions, in a format similar to the following:
PredictedValue=YourMLModel.predict(yourIncomingDataRow)
If you want to view a Java code example, here is a github link with a sample prediction call. The “your incoming data row” parameters use the same format that was used to train the model in the first place. During training the “predicted value” field is the already known “ground truth” value, whereas for this API call here it is being calculated in real time by the model and returned to the transaction process. For example when you are trying to make an offer to a customer during a real time transaction at your web site, you would want the predicted value before final purchase is made, and hence before you commit the transaction to Ignite cache. In other cases, for example when you want the prediction to calculate the expected value of a claims item after it has been submitted in batches, then this predicted monetary value can be performed by partitioned remote caches in parallel to process large batches quickly, at any time interval that makes sense for your application, in order to drive fast claims processing workflows at large scale and speed.
How to Leverage Apache Ignite: Measuring How Well Your Predictions “Guess” the Right Answer
Unlike using the model evaluation methods that are performed before you deploy the model (see my second blog post), judging the effectiveness of the prediction phase involves comparing actual transaction results with predicted transaction results. When to do the before-and-after comparison (predictions to actuals) depends on how “real time” versus “fast batch almost in real time” works for your application. The PredictedValue needs to be compared to the actual value that was entered for the transaction in order to measure the performance metrics of the post-prediction. The difference between PredictedValue and ActualValue (or “ground truth” value) might be measured as an average statistical error or as a rate of wrong guesses. Let’s use this example: if the predictions for customers of a given market profile indicated that the customers would each purchase “ProductGold”, and in fact these customers actually bought “gold” 90% of the time, and 10% of the time they bought “silver” or “bronze”, then this might be considered good performance of the predictive model. On the other hand, over time let’s say that the correct rate of “Gold” purchases falls to under 60%. In this case the model is no longer considered to be of value and so perhaps model retraining, or even model replacement, might be in order. This situation where models lose their predictive accuracy over time is called “concept drift” or “model drift” and should be expected as a natural consequence of changes in the broader business environment.
How to Leverage Apache Ignite: When Operational Data Drift Occurs, Get Your Predictions to Match New Data Patterns
All of the Ignite algorithm models that are output from training provide a model update retraining method, similar in format to the following:
updatedModel = currentModel.update(currentModel, newCacheInfo, currentPreprocessingInfo);
The input parameters, including the size of the training dataset, depend on the algorithm of the model. Also, depending on the algorithm that is used to train the model, you may have to make a tradeoff between retraining with a large dataset and updating the model with a small, incremental dataset. It is best to consult the Apache Ignite ML documentation. As discussed previously, when the temporary workloads are complete, you can add capacity for additional retraining workloads as needed by adding new nodes to the cluster, rebalancing upward to more nodes, and rebalancing downward to fewer nodes.
Conclusion: Continuous Machine Learning at Scale with Apache Ignite
I hope that, from my “Continuous Machine Learning at Scale” blogs, you have gleaned some ideas about how to add the Apache Ignite ML library and runtimes to improve the predictive performance of your Ignite applications, while you maintain the high performance that you already get from data-transaction processing. To summarize the “continuous” aspect of ML at scale, largely applicable to the real-time prediction management discussed in this blog post, Apache Ignite provides the means to do the following:
- Perform predictions on live operational data, with the already co-located model, with no need for redeployment
- Provide ongoing performance tracking of the predictions, to quickly detect occurrences such as data drift, which occur due to external business conditions or other external factors
- As needed, update (retrain) the predictive model in-place, using batches of local operational data to get the predictions back on track
And, in summary of my three blog posts, the following reviews what your architecture can enjoy in terms of new capabilities as you employ Apache Ignite ML:
- A unified platform, horizontally scalable, to grow to any arbitrary size both the OLTP processing and the add-in ML pipeline processing. The MPP architecture delivers massive data size, massive transaction throughput, and high availability to both operational and ML workloads.
- Maximization of the agility of your ML processes: in-place ML operations with your operational transactions and faster ML pipelines; improved value capture, because predictive processes work closely with transactions; and improved integration of the “Ops” disciplines (DevOps, DataOps, ML Ops).