
Note: This is post 1 in the blog series: Continuous Machine Learning at Scale with Apache Ignite. For post 2 click here and for post 3 click here.
This is my first blog post in a series that discusses continuous machine learning at scale with the Apache® Ignite™ machine learning (ML) library. In this article, I’ll introduce the notion of continuous machine learning at scale. Then, I’ll discuss how to use Apache Ignite to create the ML runtime services. Finally, I’ll discuss “operationalizing” the services to leverage Apache Ignite for runtime ML inferencing.
I assume that you, as an Apache Ignite developer or architect, have knowledge of Apache Ignite as a massively parallel, in-memory, compute platform. In these articles, I hope to show why you should build on your foundation by using the rich, open-source ML libraries that are available in the Apache Ignite distribution.
Technical Limitations Associated with Machine Learning Systems
As you know, ML technology offers much value to businesses that need to learn the underlying patterns of behavior in their large databases and then, when ML is properly deployed, actively use ML to perform real-time predictions on new data that comes in from transaction systems.
Getting through the steps needed to get an ML model into production is greatly hampered by the well-known constraints around the shear volumes of data that need to parsed, transformed, and moved over the network between systems that are optimized to do one, but not both, of two workloads: (a) operational transaction processing or (b) analytics workloads, including ML operations.
Continuous Machine Learning at Scale
In this article, I use the term “continuous machine learning.” Other practitioners might use a different term, such as “online learning” or “incremental learning.”. The meanings are similar. At the platform level, I view the notion of continuous machine learning at scale to be an example application of what Gartner calls a “digital integration hub (DIH).” What this means is that Apache Ignite provides a unified platform that can grow horizontally to accommodate any arbitrarily large data and throughput capacity, and, as a DIH platform, supports both key roles: (a) transaction-processing workloads and (b) analytics workloads.
Specifically, for ML, DIH platforms like Apache Ignite can deploy and manage, in the same cluster nodes, both online transaction workloads and simultaneously ML pipeline workloads from development to runtime. Performing this dual role provides several advantages, including minimizing or eliminating ETL/ELT movements between OLTP and analytics systems, more efficient task-to-data partition mapping, and an integrated monitoring and management framework.
Refer to the following diagram to see how Apache Ignite enables continuous learning at massive scale. Here, the application accesses an Apache Ignite cluster to perform both (a) the transaction processing needed by the application and (b) the predictive analytic workloads that are involved in extracting the recently captured data for preprocessing and training on the data and then inferencing for the live “new” arriving transactions.
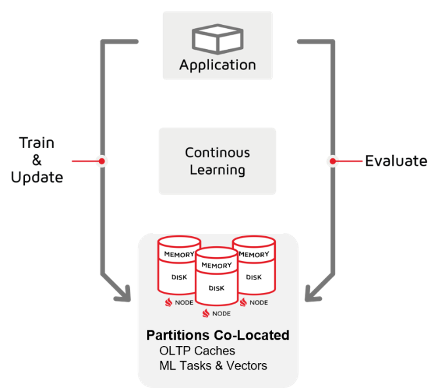
The Apache Ignite cluster can range from a few nodes to hundreds of nodes, and each node automatically adds memory and disk to the cluster. Every additional node brings additional capacity for additional operational online data and for the Java code objects that are sent and run at data caches for ML preprocessing and training. Cluster reconfiguration is not required.
So, to elaborate on how Apache Ignite brings both “continuous ML” and “scale” to your inferencing needs, let’s review in the following sections how Ignite improves ML operations.
Horizontal Scalability That Supports Massive Data Sizes and Throughput Rates
Most of today’s ML stacks, however complete, are constrained by single-server environments and so are limited in their ability to process and train on datasets that are far larger than single-server memory environments. Those of you who work with Apache Ignite data grids know how we break the central DBMS logjam with distributed data grids. We do similar things when it comes to ML processing.
These centralized data servers, usually based on DBMS systems, can be scaled up, of course, but scaling up is done vertically and expensively. So, when I refer to massive data sizes, I mean sizes up to and exceeding the terabyte, petabyte, and even larger sizes that are not feasible with centralized servers.
The only way that is economically feasible to provide this scale for data size growth is to incrementally scale out RAM and disk as needed, using readily available commodity hardware. This horizontal scalability is key when it comes to jointly housing transaction workloads and ML workloads: When workloads are housed together by using a cluster of small hardware nodes, you don’t have to load more data and analytics on small nodes. Rather, you split data and analytics into more nodes instead of performing expensive vertical scaling.
Dynamic, Agile Co-Located Processing: Bring Online, Perform Task, Take Offline Without Reconfiguration
Apache Ignite co-located processing is a key feature when it comes to continuous ML. Apache Ignite co-located processing is a “lambda” approach to MPP processing. With this approach, Java classes are (a) declared at a client and (b) shipped out in parallel (the “map” phase) to however many nodes contain the operational (OLTP) data caches. Then, the Java classes (c) perform the compute task on the local partitions of the data cache, (d) return the results to the caller (the “reduce” phase), and then (e) “wrap up” the task by removing the no-longer needed compute resources from the cluster. Review the following diagram to see how Apache Ignite provides parallel co-located processing on an arbitrarily large cluster of data.
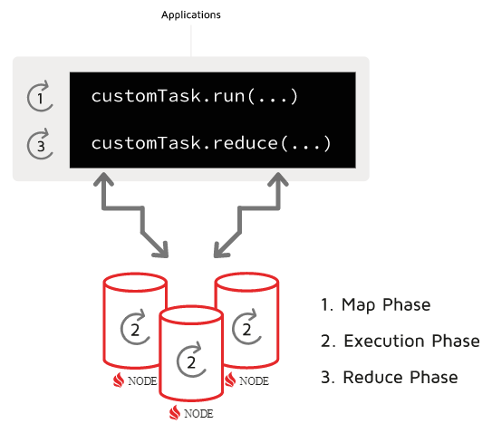
This process is dynamic in that data clusters do not require preconfiguration for each task. Different ML drivers can join the cluster, perform their stage of the pipeline, and then conclude without pausing or restarting the cluster. The cluster transforms data after each step, but the configuration of the cluster is unchanged, so there is no need to do any configuration other than attaching the client with the job and then removing the client. The primary advantage of co-located processing is the reduction and even elimination of data shuffling between caches and the client, as well as between caches.
This core technology is how all Ignite ML pipeline steps are implemented by the Apache Ignite libraries. All phases of the ML pipeline are needed, including extraction of OLTP data into training vectorized data, preprocessing of the data into vectorized form, training of itself, and evaluation of model quality prior to deployment. All of these phases are performed on potentially hundreds of nodes in parallel.
Specifically referring to Apache Ignite: All phases of the ML pipeline—such as accessing online data, preprocessing, vectorizing (that is, converting into numerical vectors format), training, evaluating, doing runtime inferencing, tracking inferencing performance, and, when necessary, retraining—should be executed on the same cluster nodes. Ignite client nodes with ML tasks join the cluster when needed, perform the actions on the cluster data cache nodes, and can be organized into customizable and flexible orchestration pipelines, all using online data as the source and as the deployment location.
Conclusion, Until My Next Blog Post
To summarize: “Continuous machine learning at scale” refers to the process of running, in the same nodes, the online transactions and the compute code that performs the process of converting the transaction data (going backward in time but in the same in-memory database) into training datasets. The datasets are then used to create predictive models that, in turn, can be used to predict new transaction values in real time or near real time. All these tasks occur in the same cluster—no need to move data between OLTP and ML systems. Apache Ignite makes this possible with several key features:
- Massive scalability, so you can run operational data and ML processes in the same cluster nodes, side by side, and, thus, simply add nodes to grow capacity
- A complete ML library for all of the tasks in the ML pipeline (to be covered subsequently in additional blog posts)
- Co-located processing for the ML pipeline tasks at the cluster nodes where the data operational lives, to minimize and often eliminate data shuffling
In subsequent posts, I will drill down into more of the capabilities offered by Apache Ignite continuous machine learning at scale to discuss (a) massive distributed data preparation and the machine learning stages of the pipeline and (b) how the trained model is used in a “closed loop” fashion at inference time to continuously track performance of the mode at the transactional level and to update the model to handle the data drift that occurs over time.