
Note: This is post 2 in the blog series: Continuous Machine Learning at Scale with Apache Ignite. For post 1 click here and for post 3 click here.
In my first post, I introduced the topic “continuous machine learning at scale with Apache Ignite,” which is how we members of the Apache® Ignite™ community describe machine learning (ML) architectures that offer the following advantages:
- Support for massive data sizes and throughputs (terabytes, petabytes, and more) and automation of cluster-capacity growth by the addition of new nodes as needed. This massive data capacity facilitates faster transactions and faster agile ML processing.
- Redundancy for all ML pipeline steps. Like core Apache Ignite data availability, ML processing is redundant in that, if the primary copy becomes unavailable, the activity continues with a backup copy of the task. Therefore, you do not have to restart the training process from scratch.
- Timely, “closed-loop” coordination between (a) transaction processing and (b) ML training and predictions on the transactions. Coordination is possible with Ignite through massively parallel data and workload distribution and collocated data and compute tasks that eliminate many time consuming ETL operations.
Now, in this post, let’s discuss in more detail the capabilities that Apache Ignite ML offers you. First, we’ll cover the initial steps in the ML pipeline that you can take—obtaining the transaction data and then preprocessing the data into a format that can be input into the training phase.
Starting the ML Pipeline Process with Apache Ignite: Preprocessing and Training
The typical ML pipeline includes several steps that involve a mix of manual analysis and automated processing. Ignite excels at automated, distributed processing. As a best practice, you create an orchestration layer that runs on top of the Ignite ML libraries. The libraries are called from and orchestrated by the Ignite client (also known as “Ignite Thick Client”). The following diagram shows an example of the Ignite client as the orchestration layer that invokes the ML pipeline execution steps that result in state changes to the data in the server nodes. Optionally, you can consider use of an external tool (such as a Python Notebook) to send the ML steps via the Ignite client to be controlled and executed in parallel fashion on the cluster nodes.
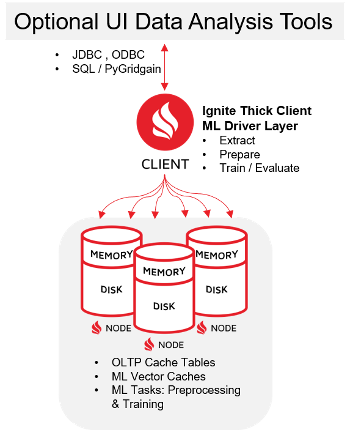
As a best practice, each of the following use-case steps should be modular and reusable so that you can combine the steps into various workflows and datasets. Each step can be considered as part of a pipeline or workflow that can be run in the way most suitable for your ML team. For example, some of the steps can be run in parallel to try different algorithms, and then the different outputs can be compared to see what produces the best results. Likewise, each step can be wrapped in a service wrapper so that third-party tools can trigger Ignite ML steps to run them collaboratively in different workflows.
First, let’s talk about some approaches to preprocess relevant subsets of operational data (the OLTP data) into a different format so that the data can be used as the Ignite ML training dataset. Think of preprocessing as similar to ETL/ELT. But, with Apache Ignite, preprocessing can be done locally, where the operational data lives.
First Step: Extracting and Deploying Training Data from Your Online Operational Data
As you know, data transformation often requires a lot of RAM and processor horsepower. Apache Ignite provides “room to grow” for the transformation, because you can add new nodes (each with more RAM and disk) whenever you want to increase the capacity for a data partition or ML compute task. Additionally, Ignite offers multiple ways to access and process the data in the caches in terms of languages for coding (standards like SQL, Java key/value, and more).
To implement data transformation, several architectural decisions must be made, but one key consideration is the tradeoff between memory capacity and overall performance. As you decide how much time you want the system to take to extract the training subset of data from your operational transaction set, you may want to add memory to the overall cluster in order to reduce the time that is required to use the same cluster to process the transaction and to extract a dataset for training purposes.
Example
Goal: You want to add capacity to the cluster in a cost-effective fashion to ensure that you can add extraction processing and memory capacity and yet maintain current transaction throughputs. Let’s say that you already have some metrics about the memory capacity that remains on each node, the capacity that is currently not allocated to the Ignite data.
Solution: One good way to ensure good performance for the added extraction process is to add some nodes. The addition of nodes automatically rebalances the data into more partitions on more nodes. Therefore, you have more CPU (with more parallelism) and more memory (added with the nodes) to support the preprocessing workload.
Many current approaches to getting the training dataset involve having a batch file (CSV format or other) dumped from the operational OLTP system and then having the CSV read separately by the ML pipeline for the preprocessing and training. Sometimes you have no choice but to use batch files, and so Apache Ignite has file loaders that use streaming technology to process the files at high speed. in my opinion, this approach is an artifact from a slower, batch-oriented ETL process, and I encourage you to look at ways to modernize the pipeline by using in-memory extraction from operational into co-located training datasets. The benefits are not only that you can deploy an ML pipeline with more throughput but also that you can deploy a more incremental, continuous learning pipeline with incremental training-set batches that are closer to real time.
Second Step: Building the Preprocessed Datasets
The preprocessing stage will probably require some trial-and-error, manual “think time.” Preprocessing is dependent not only on the state of the upstream OLTP data from the source but also on the specifics of the downstream ML training algorithms that you want to try. Apache Ignite focuses on MPP processing and so doesn’t aim to provide a user Interface with charts and other displays that enable inspection of the data. I recommend connecting a third-party data visualizer (such as a Python Jupyter, which uses JDBC or ODBC to connect to the Apache Ignite cluster) and then doing SQL queries on the Ignite data, getting the data profile into charts and graphs, and determining the best approach to handle data column attributes. Here are some typical decisions to be made about how to handle the data:
- Which columns have predictive value and should be included in the ML feature vectors? This task requires some detailed statistical analysis and visualization. You may require more sophisticated Python data-science, data-analysis tools (using the tools to make queries into the Ignite dataset and viewing the resulting metrics).
- How are missing values best handled? For example, should you use Ignite Imputer encoder (see the Ignite Preprocessor libraries for details), substituting averages or mean values, or omit this row’s values from your training data?
- Identify maximum, minimum values (maybe screening out the outliers) and then select one or more Ignite scaling algorithms to be performed on the data.
- Do unique counts of output class labels, ascertaining labeled data imbalances. Ignite standard SQL queries should be adequate for this task.
- For categorical (enumerated) variables, which encoders should you use? If there are few unique values, with no overlap, Ignite one-hot encoders are best. If there are category values with lots of unique values, Ignite string encoders are best, so that you do not create many additional category dimensions in the training vector.
After you decide which Apache Ignite ML preprocessing libraries are preferred, you can generate the new “vectorized” datasets on the Ignite clusters, to prepare the data to be fed downstream to Ignite trainer and evaluator stages. The Ignite nodes, with the source OLTP data and the new vector caches side-by-side, are run in parallel on your partitioned data, with minimal shared state. Once each node partition finishes with its calculation, the client then collects the data from all the nodes in order to complete the “reduce” phase.
Third Step: Training on the Data and Evaluating the Output Model
After successful completion of stage two, you can enter the training stage. The preprocessed, vectorized data is in your Ignite data nodes, and the data is co-located with the operational data. The training stage will probably involve some trial and error: trying different algorithmic approaches with various ML training algorithms, producing the ML model for each algorithm, and then comparing the models in terms of accuracy, recall, precision, and other metrics. In many cases, the process will be iterative. You might want to run training algorithms in parallel, compare the results, tweak the preprocessing step, change the trainer hyperparameters (example, decision-tree depth), and so on.
Apache Ignite provides a comprehensive set of training algorithms to support your ML needs:
Unsupervised training, unlabeled training data: Clustering of large, unlabeled datasets into likely classes (Ignite KMeans or Gaussian mix algorithms). For example, you may want to do some customer segmentation to see whether customers fall easily into groups like big spenders, small spenders, and medium spenders.
Supervised training, with labeled datasets: Regression (linear, log) to estimate output numerical values. For example, you may want to predict the price of real estate per foot; the adjudication for insurance claims; or classifications (multiple algorithms, like decision trees) such as Fraud and NotFraud or Patient ReAdmit and NoReAdmit. You may want to use ensemble methods such as RandomForest and XGBoost to run algorithms in parallel and “vote” to identify the best outputs.
The trained models provide APIs that enable you to perform Ignite evaluator processing, in order to ascertain the future performance of the trained models on future production data. For example, Ignite evaluation processes help you ensure that the model hasn’t overfit on the training data (“overfitting means that the model has memorized the training data so specifically that it will be unable to predict well on new OLTP data that is different by even a small amount). The evaluation processes Ignite routines to split the data into “train” and “test” datasets; this allows Ignite to treat the “test” data as temporarily unseen data where the results aren’t known, do the prediction, the see if the prediction matches the answer that is now presented with the test data. Overall the evaluation process allows you to refine the model in development before you put it into production in order to get the most business benefit: the predictions and the “actuals” match up with high accuracy so you can be assured that transactions are being guided with the best real time information possible.
Conclusion: ML Preprocessing and Training at Scale with Apache Ignite
In this post, we discussed the ML pipeline steps that are used to generate your trained predictive model, starting with the OLTP operations data from the source and ending with the model that is produced by the training step. In the next post, we’ll discuss use of the training model in a production environment to a) perform predictions on live data, b) provide ongoing performance tracking of the predictions, and c) update the model to get predictions back on track as the input data changes over time.
All ML pipeline steps that you execute on the data with Apache Ignite are performed in co-located fashion for both operational data and ML pipeline data, thus fulfilling the architectural requirement for a massively scalable, unified data-integration-hub solution that supports both operational and analytical workloads.
Here is a quick summary of the benefits that Apache Ignite provides for ML pipeline processing:
- You can easily grow your system to preprocess and train potentially massive datasets (terabytes, petabytes). This support for very large data volumes results in better predictive models and faster operationalization of the predictive models.
- You obtain better ML agility overall. Faster preprocessing and training gets you to production faster and is a key part of ML operational agility.
- Training workloads for ML models are resilient with respect to uptime (as is the case with all Ignite workloads). Ignite ML tasks run in parallel on duplicated data partitions. Hence, if the primary data copy becomes unavailable, an ML task can be resumed by a second ML task.