
In the previous article, we reviewed and summarized pitfalls of the query-driven data modeling methodology (a.k.a. denormalized data modeling) utilized in Apache Cassandra. Turns out that the methodology prevents us from developing efficient applications without insight into what our queries will be like. In reality, an application architecture under this scenario will get more complicated, less maintainable and prone to notable data duplication.
Furthermore, it was discovered that the pitfalls are usually shielded with statements like "if you really want to be scalable, fast and highly-available then be ready to store duplicated data and sacrifice SQL along with strong consistency." That might have been true a decade ago but it's a total fable nowadays!
Not going too far, we picked another Apache Software Foundation citizen -- Apache Ignite -- and in this article will figure out how our Ignite based application's architecture would look like and what would be its maintenance costs.
The application of our choice tracks all the cars produced by a vendor and gives insights on production power for every single vendor. If you recall, it has the following relational model:
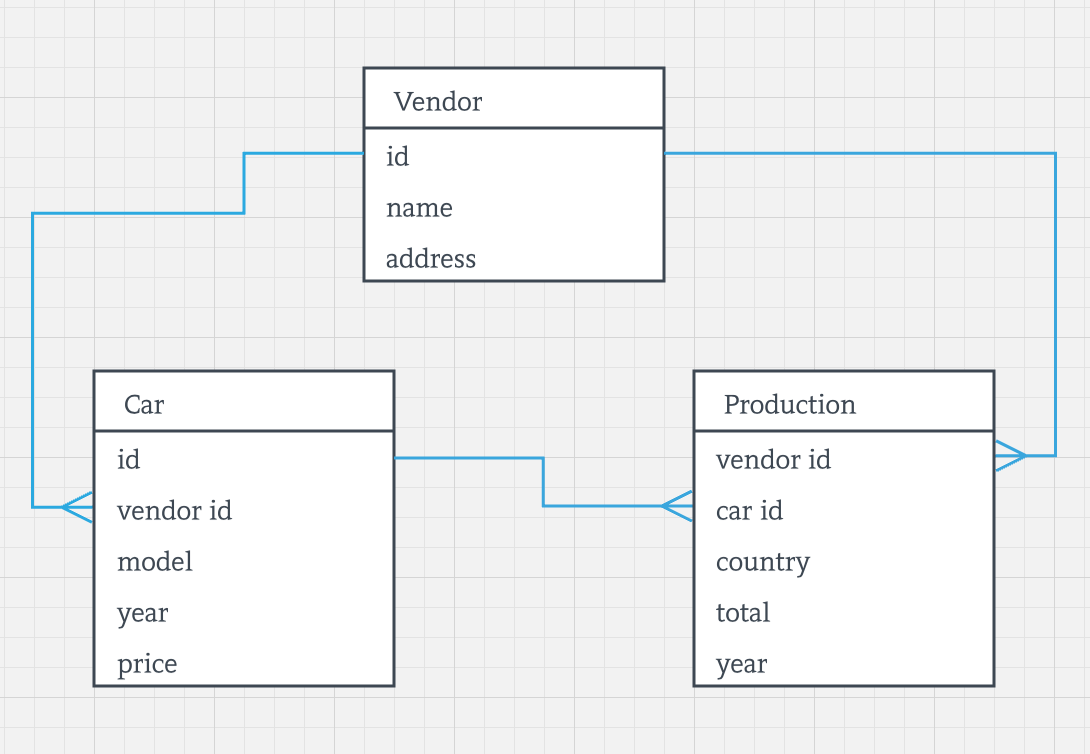
Can we just go ahead and create those 3 tables in Ignite with the CREATE TABLE command and run our SQL-driven application immediately? Depends... If we were not supposed to join the data stored in different tables then it would be enough. But in the previous article, we put a requirement that the application has to support 2 queries that require JOINs:
- Q1: get car models produced by a vendor within a particular time frame (newest first).
- Q2: get a number of cars of a specific model produced by a vendor.
In the Cassandra case, we got away with JOINs by creating 2 tables for each of the queries. Do we go through the same experience with Ignite? Totally not. In fact, Ignite's non-collocated JOINs are already at our service and doesn't require anything else from us once the 3 tables are created. However, they are not as efficient and fast as their collocated counter-part. Therefore, let's learn more about affinity collocation first and see how this concept is used in modern databases such as Apache Ignite.
Affinity Collocation Based Data Modeling
Affinity collocation is a powerful concept of Ignite (and other distributed databases such as Google Spanner or MemSQL) that allows storing related data on the same cluster nodes. How do we know which data is related? It's simple, especially with the background of relational databases -- just identify a parent-child relationship between your business objects, specify affinity keys in CREATE TABLE statements and your job is done because Ignite will take care of the rest!
Taking the Cars and Vendors application as an example, it's reasonable to use Vendor as a parent entity and Car with Production as its children. For instance, once this happens and the affinity keys are set, all the Cars produced by specific Vendor will be stored on the same node like it's shown in the picture below:
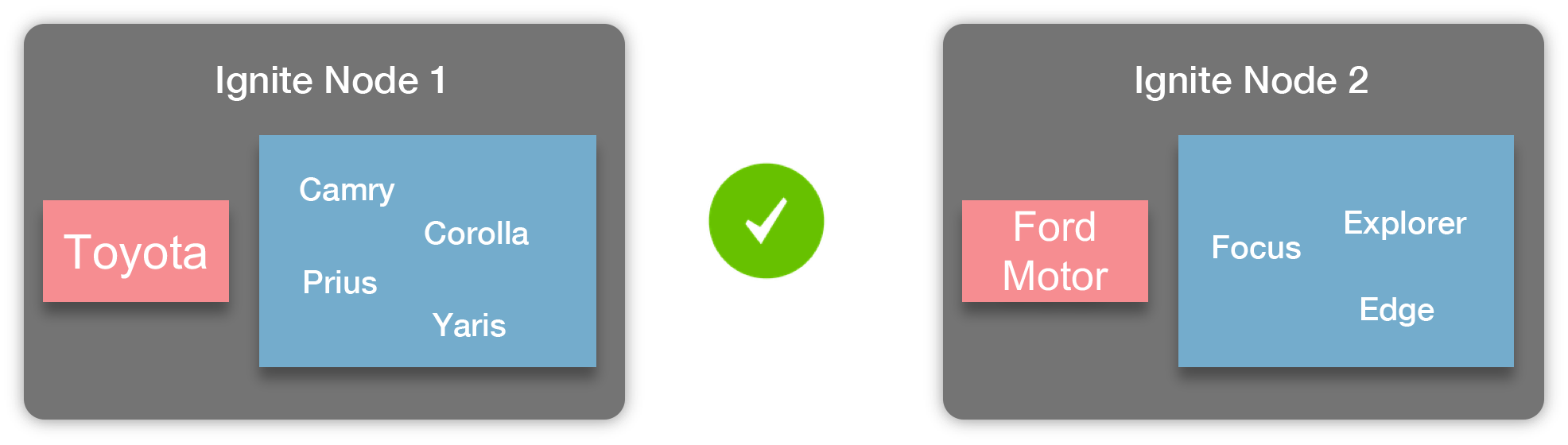
Specifically, the picture shows that all the Cars produced by Toyota are stored on Ignite node 1 while the Cars produced by Ford Motors are stored on Ignite node 2. This is the affinity collocation in action -- Cars are stored on a node where an entry of a respective Vendor is.
It's time to define SQL tables to achieve such data distribution. Let's start with Vendor table:
CREATE TABLE Vendor (
id INT PRIMARY KEY,
name VARCHAR,
address VARCHAR
);
The Vendors will be distributed randomly across the cluster nodes. Ignite uses the primary key column to calculate a node that will own a Vendor's entry (refer to the recording of Ignite essentials Part 1 webinar for more details).
The Car table goes next:
CREATE TABLE Car (
id INT,
vendor_id INT,
model VARCHAR,
year INT,
price float,
PRIMARY KEY(id, vendor_id)
) WITH "affinityKey=vendor_id";
The table for Cars has affinityKey parameter set to vendor_id column. This key instructs Ignite to store a Car on the cluster node of its vendor_id (refer to the recording of Ignite essentials Part 2 webinar for more info).
Repeating the same procedure for Production table which entries will be stored on the cluster nodes identified by vendor_id as well:
CREATE TABLE Production (
id INT,
car_id INT,
vendor_id INT,
country VARCHAR,
total INT,
year INT,
PRIMARY KEY(id, car_id, vendor_id)
) WITH "affinityKey=vendor_id";
That's it with the data modeling done right in Apache Ignite. The next step is to get down to our application code and make out all the required queries.
SQL Queries With JOINs
Ignite cluster can be queried with our old-good-friend SQL that supports distributed JOINs and secondary indexes.
There are two types of JOINs in Ignite -- collocated and non-collocated. The collocated JOINs omit data (that is needed to complete a JOIN) movement between cluster nodes expecting that the tables, that are being joined, are already collocated and all the data is available locally. That's the most efficient and performant JOINs you can get in distributed databases such as Ignite. The non-collocated JOINs as the name suggests is our a backup plan if there was no way to achieve affinity collocation for some tables but they still need to be joined. This type of JOINs is slower because they might involve data movement between cluster nodes at a JOIN time.
Previously we could collocate Vendor, Car and Production tables and now can benefit from the collocated JOINs preparing an SQL query for Q1 (get car models produced by a vendor within a particular time frame (newest first)):
SELECT c.model, p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = 'Ford Motor' and p.year >= 2017
ORDER BY p.year;
Is there any way to make it even faster? Sure, let's define secondary indexes for Vendor.name and Production.year columns:
CREATE INDEX vendor_name_id ON Vendor (name);
CREATE INDEX prod_year_id ON Production (year);
The SQL query for required Q2 (get a number of cars of a specific model produced by a vendor) does not require extra efforts from us:
SELECT p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = 'Ford Motor' and c.model = 'Explorer';
Now, whenever a boss stops by our cubicle requesting to add a new feature we can quickly come up with a set of new SQL queries needed for it, configure secondary indexes and go to the kitchen to chat with teammates. Job done! In comparison, recall what it took us to support new query Q2 for the Cassandra based architecture.
Simplified Architecture - Mission Completed!
Affinity collocation based on data modeling in Ignite has the following advantages over the query-driven denormalized modeling in Cassandra:
- Applications data layer is modeled in a familiar relational way and easy to maintain.
- Data is accessed using standard SQL syntax.
- Affinity collocation provides more benefits from modern distributed databases:
- Efficient and highly performant distributed JOINs
- Collocated computations
- Watch a recording of this webinar to reveal more benefits of this technique.
The simplified software architecture we get with Ignite is not the only benefit if we consider it instead of Cassandra. Give me a couple of weeks to put together my thoughts on strong consistency and in-memory performance.