
 Apache Cassandra has become an incredibly popular database for software architects and engineers. Many of us trust it for our applications’ data and, presently, there are thousands of deployments running this reputable NoSQL database. No doubt, Cassandra totally deserves its glory and reputation. The database simply does what it is expected from it -- unlimited scalability and high-availability with fast write operations.
Apache Cassandra has become an incredibly popular database for software architects and engineers. Many of us trust it for our applications’ data and, presently, there are thousands of deployments running this reputable NoSQL database. No doubt, Cassandra totally deserves its glory and reputation. The database simply does what it is expected from it -- unlimited scalability and high-availability with fast write operations.
These two essential capabilities helped Cassandra rapidly rise in popularity by solving problems and use cases that relational databases could not tackle. The problems and use cases required horizontal scalability, high-availability, fault-tolerance and 24x7 operability without downtime. The classical relational databases could not fulfill all of the requirements then -- and cannot now (except perhaps for distributed relational databases such as Google Spanner or CockroachDB).
However, the famous scalability and high availability was not given to us for free. Those of us who were spoiled by simple design principles and the features of relational databases were forced to learn how to use Cassandra in the right way, how to do a data modeling properly, and how to live without advanced SQL capabilities.
In this article, I will lay out a dark side of Cassandra’s data modeling concept. This is a pillar of the overall Cassandra architecture and I will suggest how to make the architecture simpler by leaning on modern databases that can equip us with everything Cassandra has -- and even more.
Data Modelling Done Right
Sure, it takes time to grasp the data modeling concepts in Cassandra -- which is not a big deal considering there are plenty of resources on the subject. The concept is based on a denormalization strategy that requires us to guess all the queries that will be run against the database … in advance. Frankly, it’s feasible, too. Just come up with a list of queries, make up Cassandra tables optimized for the queries and kick an application out into production.
This design is called a query-driven methodology, meaning our application development is driven by our queries. We can no longer develop an application without insight into what our queries will be like. Ad hoc becomes a bit more tricky with this data dogma, but we trade that off for fast and cheap writes in a Cassandra deployment.
For instance, let’s assume our application tracks all the cars produced by a vendor and gives insights on production power for every single vendor. In the relational world we might come up with a data model like this:
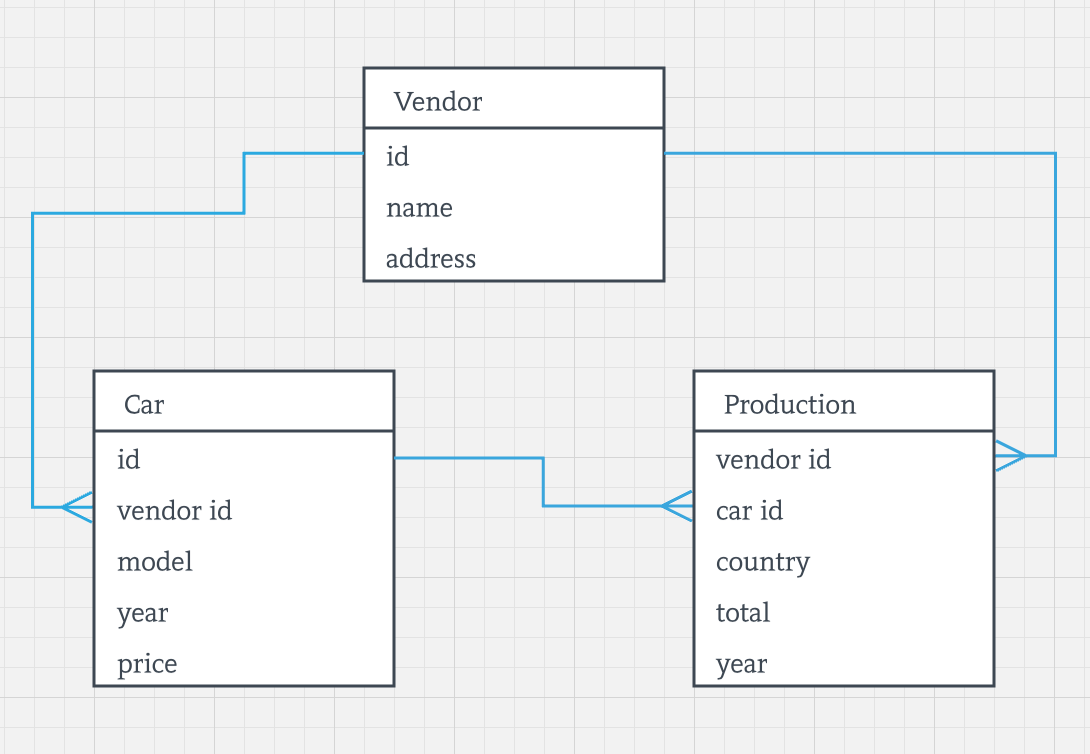
Technically, nothing thwarts us from using the same model in Cassandra. But the model is not viable from an architectural standpoint because Cassandra cannot join data stored in different tables -- and we definitely want to intermix data of Cars, Vendors and Production in a single result set. If we want to achieve this, it’s time to dismiss the relational model and leverage from the denormalization strategy.
That strategy guides us to come up with a list of queries (operations) needed for the application and then design the model around them. In practice, nothing can be simpler. Let me illustrate the denormalization strategy for those who are not familiar with it or Cassandra.
Imagine that the application has to support this query:
Q1: get car models produced by a vendor within a particular time frame (newest first).
To run the query efficiently in Cassandra we will create the table below that partitions data by vendor_name and arranges it leaning on production_year and car_model as on clustering keys:
CREATE TABLE cars_by_vendor_year_model (
vendor_name text,
production_year int,
car_model text,
total int,
PRIMARY KEY ((vendor_name), production_year, car_model)
) WITH CLUSTERING ORDER BY (production_year DESC, car_model ASC);
Once the table is populated, we are good to run a Cassandra query below that corresponds to initially defined Q1:
select car_model, production_year, total from cars_by_vendor_year_model where vendor_name = 'Ford Motors' and production_year >= 2017
On top of this the table is suitable for these operations:
- Get Car models produced by a Vendor:
select * from cars_by_vendor_year_model where vendor_name = 'Ford Motors' - Get a number of Cars of a specific model produced in a specific year:
select * from cars_by_vendor_year_model where vendor_name = 'Ford Motors' and production_year = 2016 and car_model = 'Explorer'
Next, we’re doing this exercise for every single query, planned to be supported by the application, making sure all the tables are in place and roll our application into production. Job done and we’re expecting to get a bonus at the end of a business quarter!
Drawbacks
Okay, so maybe there is a chance that the bonus will not end up in our pocket.
One drawback of the Cassandra-based architecture usually surfaces when the application is actually in production. This normally happens when someone stops by our cubicle and demands to enhance the application by quickly adding a new operation. This is where Cassandra falls short.
If the data model was a relational one then we would prepare an SQL query, create an index if needed and push a patch into production. Cassandra is not that simple. If the query cannot be executed in general or efficiently due to the settled architecture then we will be required to create a brand-new Cassandra table, set up primary and clustering keys to fulfill the query specificities and copy needed data from the existing tables.
Let’s go back to our Cars and Vendors application that is already used by millions of users and try to fulfill the following operation (query) in it:
Q2: get a number of cars of a specific model produced by a vendor.
After contemplating for a minute we might conclude that it’s possible to make out a Cassandra query basing on cars_by_vendor_year_model table created earlier. Well, the query is ready and we try to run it:
select production_year, total from cars_by_vendor_year_model where vendor_name = 'Ford Motors' and car_model = 'Edge'
However, the query fails with an exception as follows:
InvalidRequest: code=2200 [Invalid query] message="PRIMARY KEY column "car_model" cannot be restricted (preceding column "production_year" is not restricted)"
The exception simply reminds us that before filtering data by a car_model we have to specify a production year! But the year is unknown and we have to create a different table just for the sake of Q2:
CREATE TABLE cars_by_vendor_model (
vendor_name text,
car_model text,
production_year int,
total int,
PRIMARY KEY ((vendor_name), car_model, production_year)
);
And finally we can successfully execute the query below that corresponds to Q2:
select production_year, total from cars_by_vendor_model where vendor_name = 'Ford Motors' and car_model = 'Edge'
Now, step back, look at the structure of both cars_by_vendor_year_model and cars_by_vendor_model, and tell me how many differences you will be able to spot. Well, just a couple and the main one is in the arrangement of the clustering keys! So, just for the sake of Q2 we had to:
- Create a new table that duplicates data of the previously existed
cars_by_vendor_year_model - Take care of atomic updates of both tables embedding batch-updates in our application.
- Complicate application architecture.
This story tends to happen again and again unless the application stops evolving and we dump it. It’s unlikely in practice, at least during the first years, which means it’s time for us to put on our helmets and get ready to bang our heads on an unlimited architecture complication. Is there a way to avoid this? Absolutely. With some magic Cassandra capability? Definitely not.
Apache Ignite to the rescue?
SQL queries using JOINs are not cheap -- especially if a relational database is running on a single machine and starts “choking” due to growing workloads. This is why many of us switched to Cassandra and put up with the drawbacks of its data modeling technique that usually leads to a complicated architecture.
The market for distributed stores, databases and platforms are experiencing tremendous growth. It’s doable to find a database that scales as well and is as highly available as Cassandra but that will also allow us to build an application based on a relational model.
Looking into some other Apache Software Foundation (ASF) projects, we come across Apache Ignite. This is a memory-centric data store used as a distributed cache or database with built-in SQL, key-value and computational APIs.
Ignite is still under a shadow of its older ASF-mate (Cassandra). However, I constantly run into the people who find these databases pretty similar from scalability, high-availability and persistence standpoints. Plus, many confirm that Ignite is unbeatable when it comes to SQL, distributed transactions and memory store. Furthermore, folks who trusted Cassandra production environments, try to speed it up by using Ignite as a caching layer -- normally as an intermediate step on the phase of Cassandra’s replacement with Ignite’s own persistence.
Are you as interested as I was when joined the Ignite community? Then fasten your seat belts and wait for the next articles that will break down how to build a simpler relational-model based architecture with Ignite. I will build on this example for the Cars and Vendors application by utilizing affinity collocation and partitioning concepts, efficient collocated SQL JOINs and more. For those who are impatient and want to solve this task on their own, I’ll recommend getting to know Ignite's main capabilities by first watching part 1 and part 2 of Ignite essentials.