
On Wednesday December 7, 2016, I hosted a webinar with Peter Zaitsev, CEO and cofounder of Percona, in which we discussed how you can supplement MySQL with Apache® Ignite™.
MySQL® is an extremely popular and widely used RDBMS. Apache Ignite is the leading open source in-memory computing platform which can provide speed and scale to RDBMS-based applications. Apache Ignite is inserted between existing application and data layers and works with all common RDBMS, NoSQL and Hadoop® databases.
We discussed:
- How to overcome the limitations of the MySQL architecture for big data analytics by leveraging the parallel distributed computing and ANSI SQL-99 capabilities of Apache Ignite
- How to use Apache Ignite as an advanced high performance cache platform for hot data
- The strategic benefits of using Apache Ignite instead of memcache, Redis®, Elastic®, or Apache® Spark™
- At the end of this webinar, you will understand how incorporating Apache Ignite into your architecture can empower dramatically faster analytics and transactions when augmenting your current MySQL infrastructure.
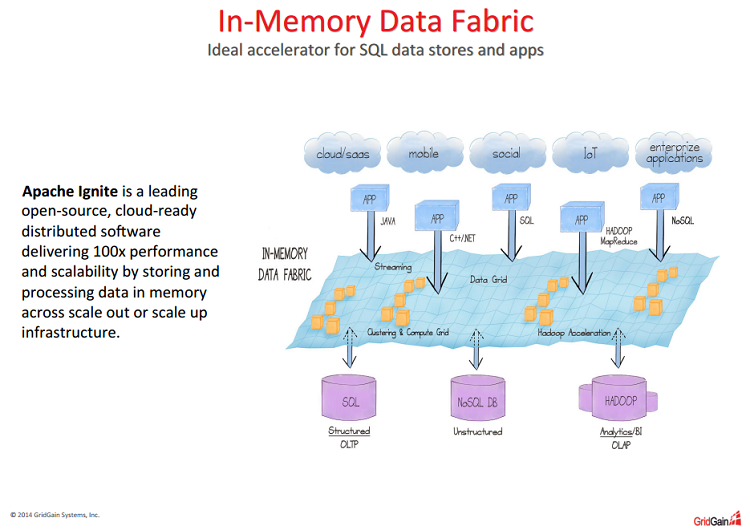
Questions and Answers from Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite
After Peter and I ran through our presentations we received a few fascinating questions from the audience.
"You made a comment about sliding Apache Ignite into existing deployments. How much rewrite is required of the application code?"
Nikita Ivanov: There's always some rewrite. It's never like a complete slide in. Let's be clear here. It depends on what interface you use to interact with database or your data access layer, if you will. So if you use just SQL and nothing else, then your "rewrite" will be very limited. So you do have to basically understand what portion of the data will go to the memory. I always say, don't put everything – unless you have very small data set, like three terabytes. If you have hundreds of terabytes of data, don't do all in-memory. You don't have to. Just look at your working set and put a working set in there in RAM.
This becomes more DevOps question. You can fill all this cache, or keep this cache warm, or do the warm-up on demand. But then, fundamentally, your apps just have to issue a different SQL query. So that's a fairly limited rewrite, and we're talking about maybe a few weeks for a large application. And we've done this many times, so we – if it's a SQL only app, in a few weeks we can actually convert some of the banking applications.
If you guys use something more sophisticated and non-SQL, that rewrite will be a little bit more significant because we support key-value access; we'll support transactions; we'll support SQL. But if it's not one of those – it's something you guys developed in house – you have to find a way to integrate us. Typically in these use cases we're looking at two or three months of work for one or two engineers. And, obviously, for applications which you're developing from scratch, that's not an issue.
"What preparation do you recommend to my MySQL infrastructure for optimal Apache Ignite benefits? And is that something Percona can help us with?"
Nikita Ivanov: Absolutely, Percona can help. And Percona is the leader in this space. There's no question. Surprisingly, there's not much preparation needs to be done. You still do your typical database tuning and optimization, like you would do without Apache Ignite, because the faster your SQL code works on MySQL, the better and faster Ignite will work as a layer on top of it.
You run your tests and you basically have to figure out if certain tables get hit many, many times; you optimize that. But fundamentally, we're seeing dozens and dozens of projects where MySQL was the back end, and then applications where Ignite was used. I cannot recall a single time where we had a major issue of incompatibility between Ignite and MySQL. In many ways, it just works.
Peter Zaitsev: Yeah, I agree with Nikita. I think it's – even with MySQL, you still want to follow their best practices. Especially if you're trying to run Apache Ignite alongside of MySQL, for example, as a cache and still keep MySQL as your primary data store.
"What security options, such as user authentication, authorization, data encryption at rest, does GridGain implement versus what is in native Apache Ignite?"
Nikita Ivanov: That's a good question. So in Apache Ignite – let's do it this way. There are interfaces in Apache Ignite that you can implement yourself. And I think there's quite a few things actually available now in Apache Ignite, like encryption. But one of the options in the GridGain Enterprise Edition is much more robust security and encryption implementation. So not only we have a full audit for the data in GridGain, there's quite a few implemented components for going integration with Airbrush, for example, key management, and for encryption and authentication.
But there is definitely authentication, for example, between clients and servers that's available in Ignite. Sure. But I think the biggest addition that GridGain brings, which is essentially enterprise edition of Apache Ignite, is the parallel capability. If you guys are in financial service industry, you know how important to have an audit on the data. And remember that you can download a 30-day trial of GridGain Professional or Enterprise Edition.
"How does this support the relational objects in memory cache? If yes, then how will it manage the invalidation of the in-memory data objects?"
Nikita Ivanov: So, if I'm guessing the question correctly, we essentially keep the data in RAM always as a key-value store. But then the beauty of a key-value store is that it's very malleable. You can really view it as, let's say, a file system, where every cache is a file and essentially you have a file of key-value pairs. In the same time, you can keep this key-value store. You can view it as a SQL store, as a relational database. And that's exactly what we do. So it's one of the really unique capabilities of Apache Ignite is that you can store data as a key-value, and then immediately exit as a file or as a SQL database.
There are some use case where it's actually fairly interesting, especially for legacy applications, where you can store data as a file – for example, you literally open the file, write something, close the file – and then the very next line of your code, you query this "file" with SQL. It's the same data, just a different view.
As far as the second part of the question, validation, if I'm guessing you right, you're talking about how do we invalidate data in RAM when it gets updated in database externally. So that's a hard question, first of all. And it's a hard – it's not the question, but it's a hard feature. Because we typically recommend that all updates to the database go through Ignite, because this way we know what's been updated in the database. We can smartly, obviously, invalidate data in RAM, so we keep it in sync.
If it doesn't – if it's not possible, then we have solutions like an Oracle GoldenGate product, which we have integration in the enterprise edition. And that basically allows us to have a centrally – think about it as a callback from a database. When something gets updated in database, we get a logical callback to our application and we can invalidate the same entry in cache. But, again, that requires enterprise edition. That requires the GoldenGate product from Oracle to have in place.
"How are the query optimization options present in Ignite?"
Nikita Ivanov: Well, as I mentioned when I was talking, we use – we actually made a very interesting decision. We decided not to implement our own SQL optimizer and query engine. It would have taken years to do it right. Just look at MySQL and all the rest and everybody else. It took years and years. So what we did, we use on each node in a cluster, we use a localized H2 database engine that, in my opinion, does a very good job for a local – an execution plan of optimization. What we added on top, we added on top the whole distribution of SQL processing.
So on each node, we use a proven H2 database instance. This manages all the actual local MySQL execution and Ignite provides all the distribution logic for how do we distribute the SQL processing, how do we collect results back and whatnot. So is that, I guess, why we're literally predominant SQL engine when it comes to in-memory systems, because we smartly decided not to reinvent the wheel and use something that is available and proven, and really add only where we can add benefits like distribution and parallelization.
The full recording of the webinar is available for you to dig deeper into this scintillating material.