Certified Kafka Connector
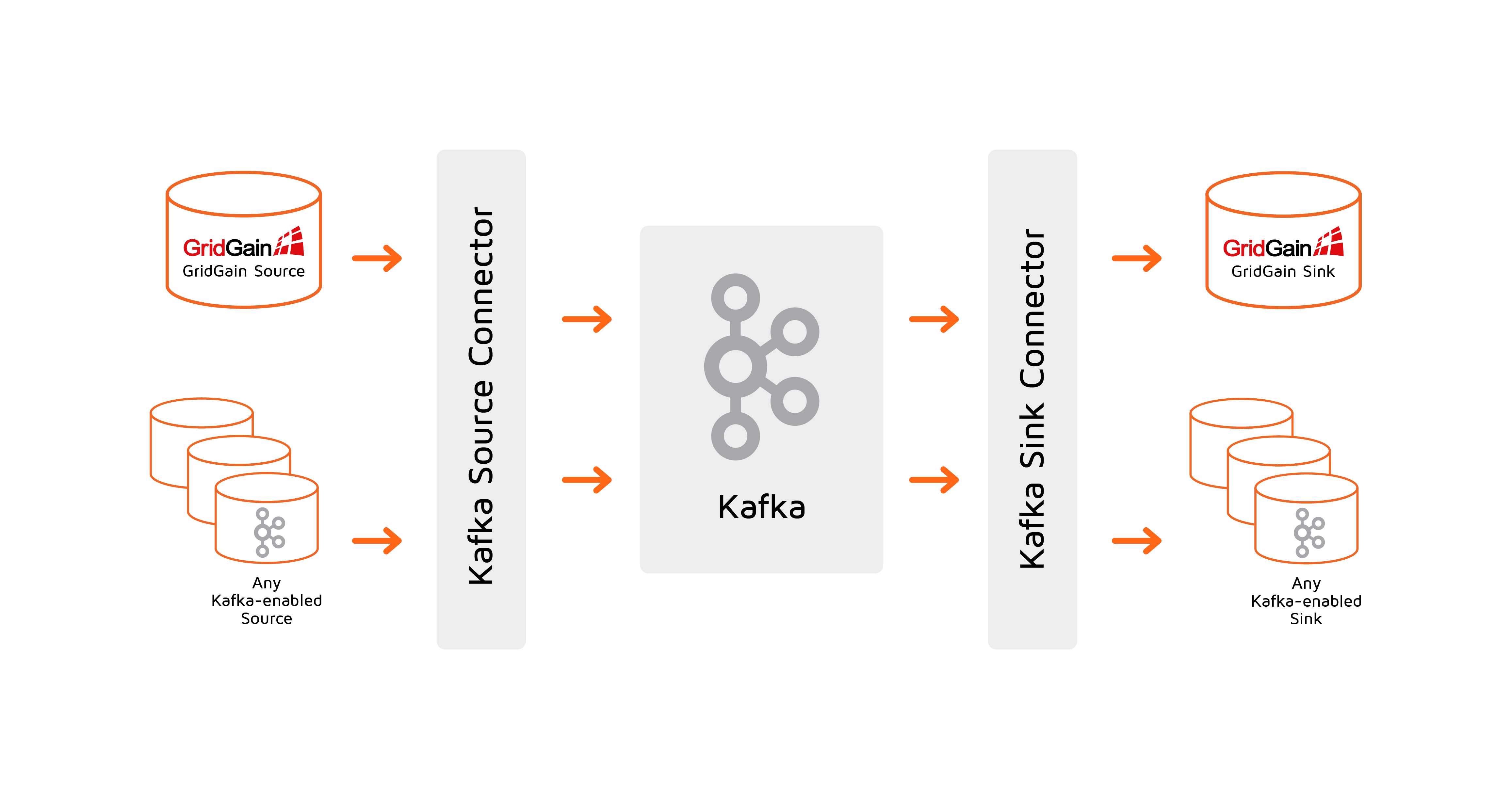
Kafka Connector integrates Kafka with Apache Ignite making it easy to add Apache Ignite to a Kafka pipeline-based system.
Kafka Connector is scalable and resilient and takes care of many integration challenges that otherwise would have to be manually addressed if you used Kafka Producer and Consumer APIs directly.
Kafka Connector Features
-
Configuration-driven: no coding, see Kafka Connector Configuration to learn about available configuration settings.
-
Scalable and resilient architecture: review Kafka Connector Architecture to learn how Kafka Connector addresses performance, scalability, and fault tolerance requirements and get deeper understanding of the Kafka Connector internals.
-
Supports Ignite data schema: review the Kafka Connector Data Schema to see how Kafka Connector recognizes, preserves, and updates Ignite Data Schema to enable automated streaming of data from Ignite to numerous systems having Kafka Connectors like Cassandra, HDFS, relational databases, and much more.
-
DevOps-friendly: review Kafka Connector Monitoring to learn how to monitor Kafka Connector in production.
-
GridGain vs. Community Connector: see GridGain vs. Apache Ignite Kafka Connector to learn how GridGain Kafka Connector is different from the open source Apache Ignite Kafka Connector.
Quick Start and Examples
Use Kafka Connector Quick Start to learn how to install, configure, and run Kafka Connector and then review real examples:
© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.