Load Sync Hive
Loading and Synchronizing With Hive Store
This document explains how to set up GridGain Hive Store and use it for:
-
Schema importing
-
Initial data loading
-
Synchronization between GridGain and Hadoop
Prerequisites
-
Install GridGain following this Getting Started guide.
-
Create an account in GridGain Nebula.
-
Ensure that the following versions are used: Apache Hadoop version 2.x and Apache Hive 2.x with configured transactions.
-
Run hiveserver2 in order to enable JDBC connections to the Hive cluster.
Refer to the official Apache Hive documentation about transaction manager and related properties.
You must also have the transactional property enabled at the table level, for example:
CREATE TABLE test_pk1 (
id Integer,
value String,
PRIMARY KEY (id) DISABLE NOVALIDATE
) STORED AS ORC TBLPROPERTIES ('transactional'='true');Schema Importing
-
Go to GridGain Nebula, sign up or sign in if you already have an account.
-
Download Web Agent from GridGain Nebula:
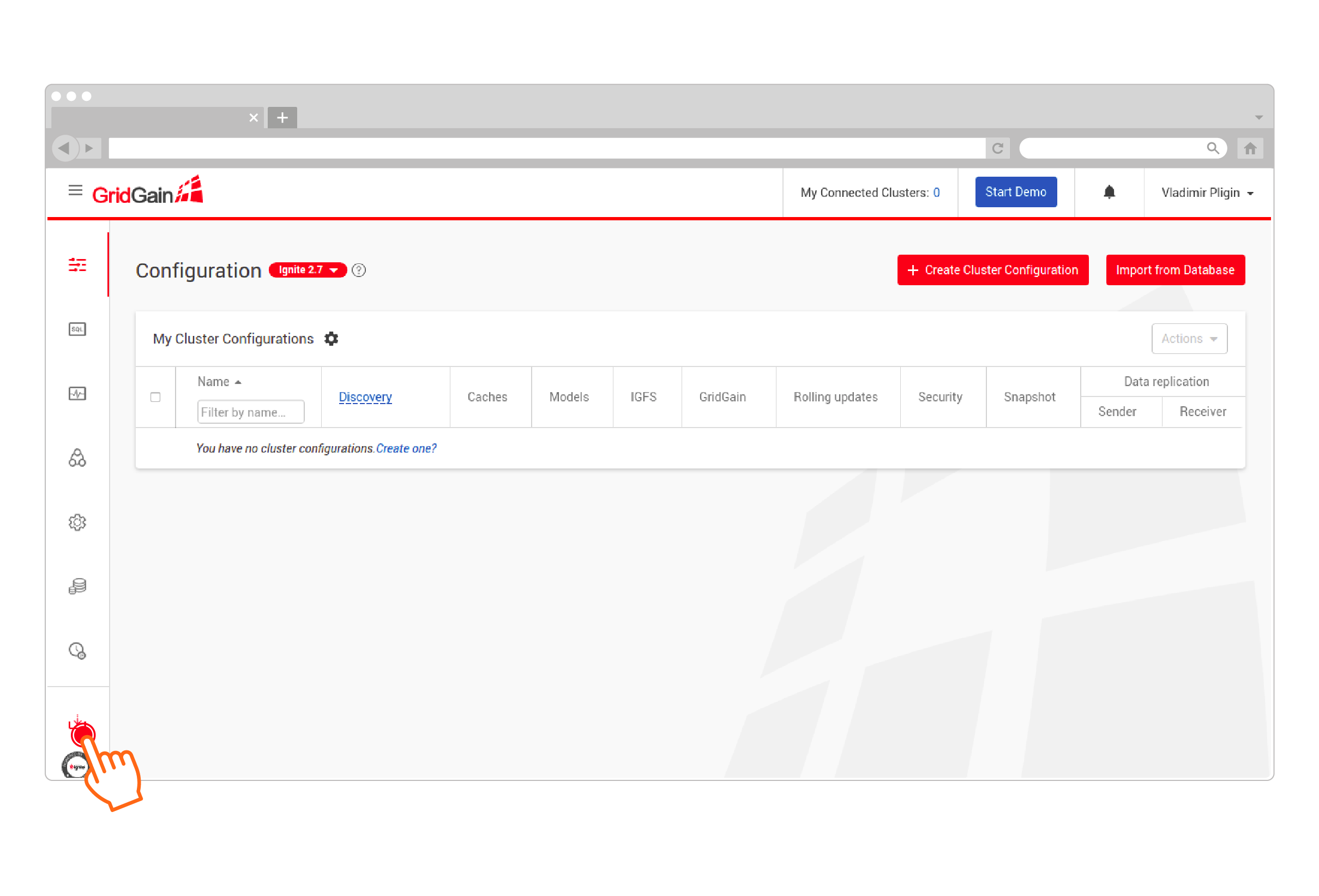
-
Configure Web Agent. The extracted package should contain the corresponding Hive JDBC driver in the jdbc-drivers directory. The driver’s dependencies should be included in the java class path of the Web Agent. One possible solution is to place required jars in the Web Agent root directory.
-
Click Import from Database:
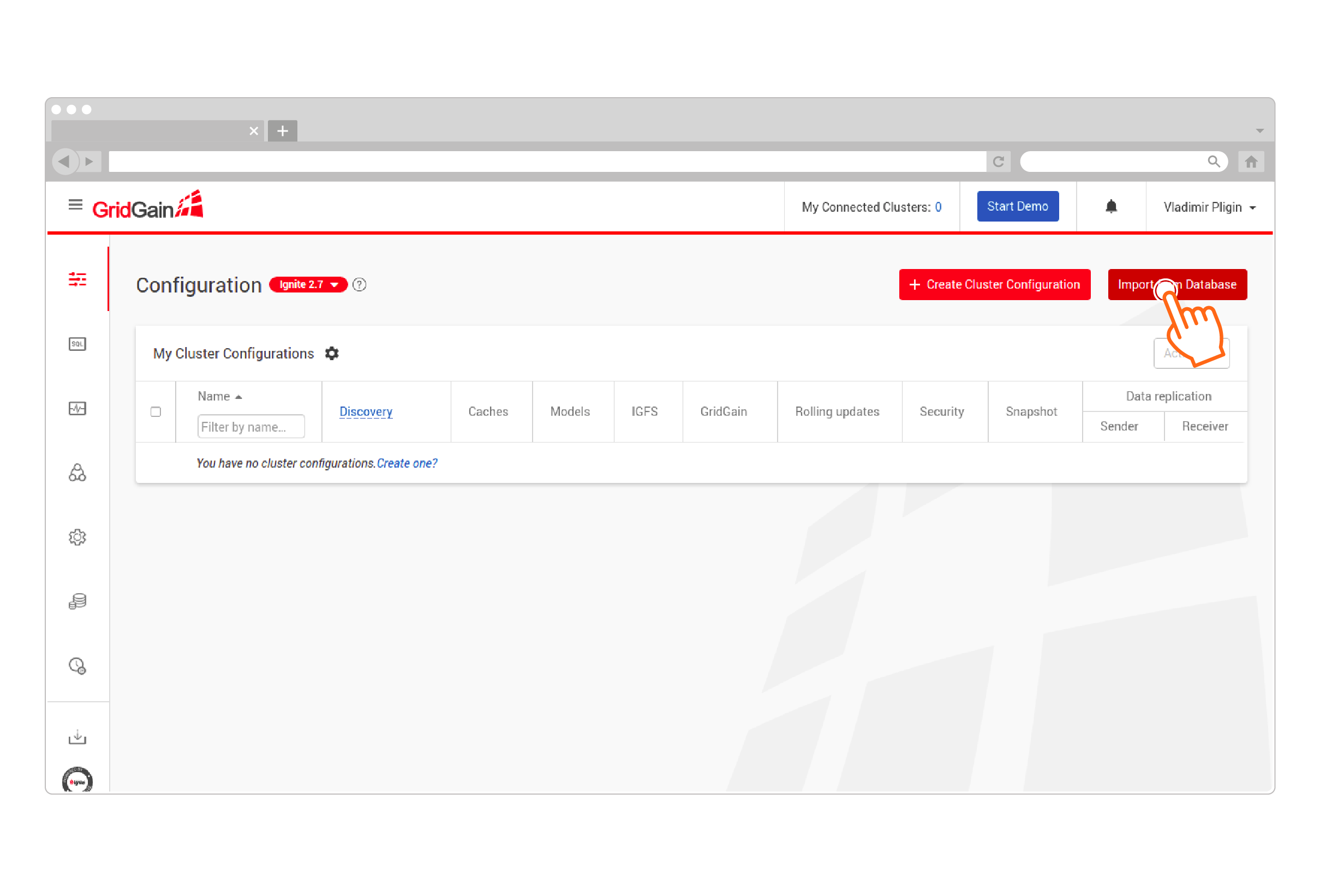
-
Configure your Hive JDBC connection to allow Web Agent to collect metadata from the target Hive installation:
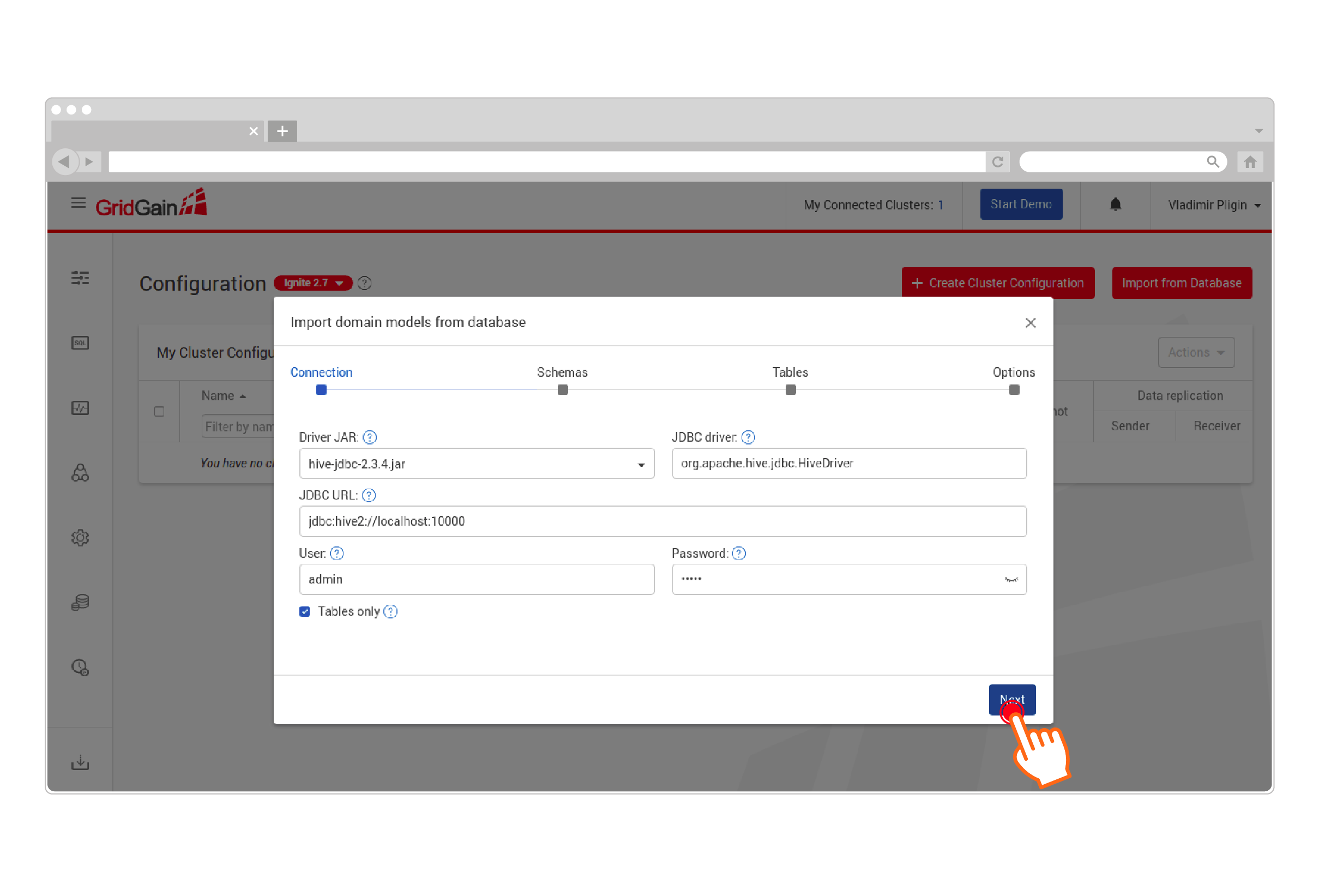
-
Select schema(s) to import:
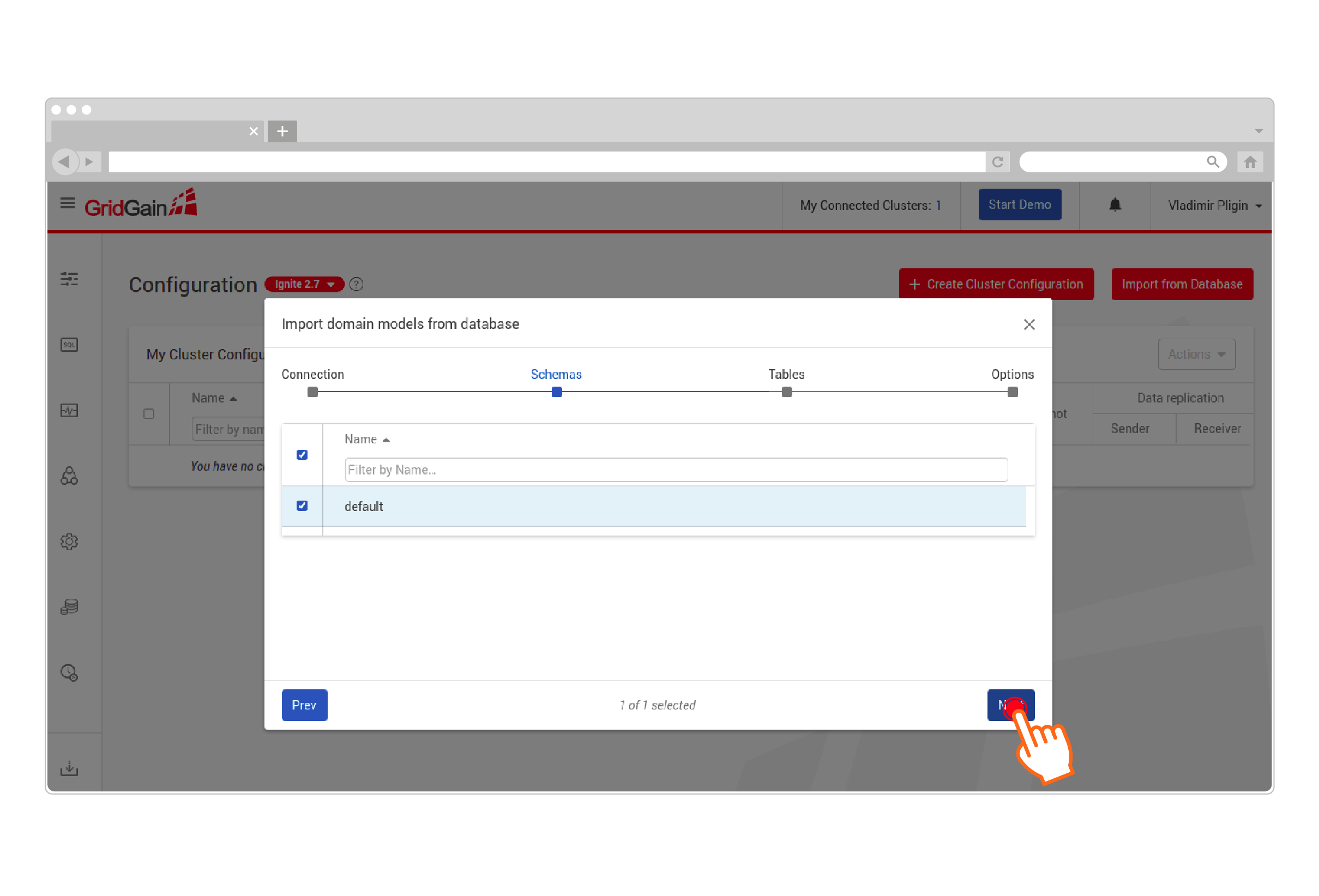
-
Select the desired tables and configure the cache template:
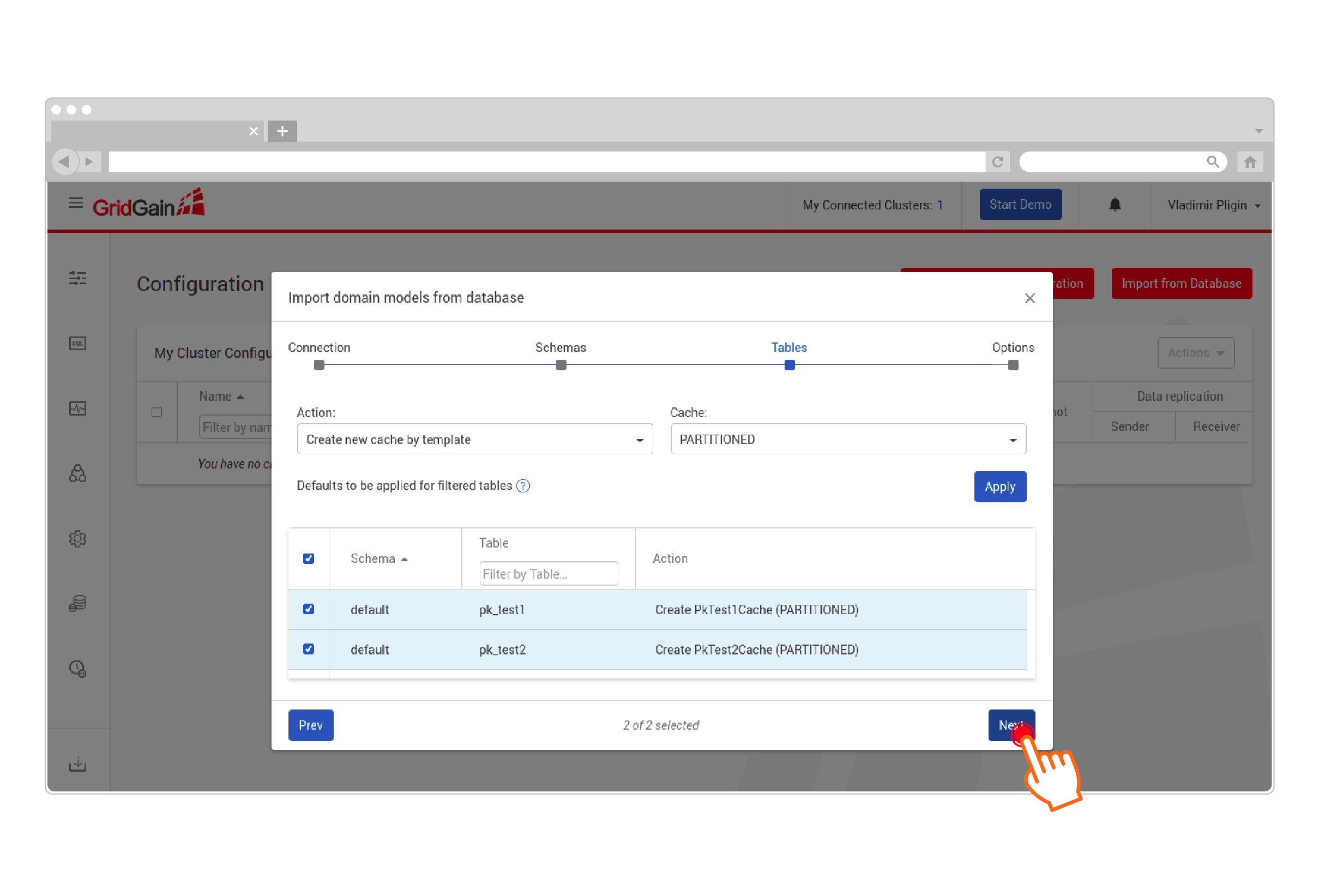
-
Configure the results of project generation:
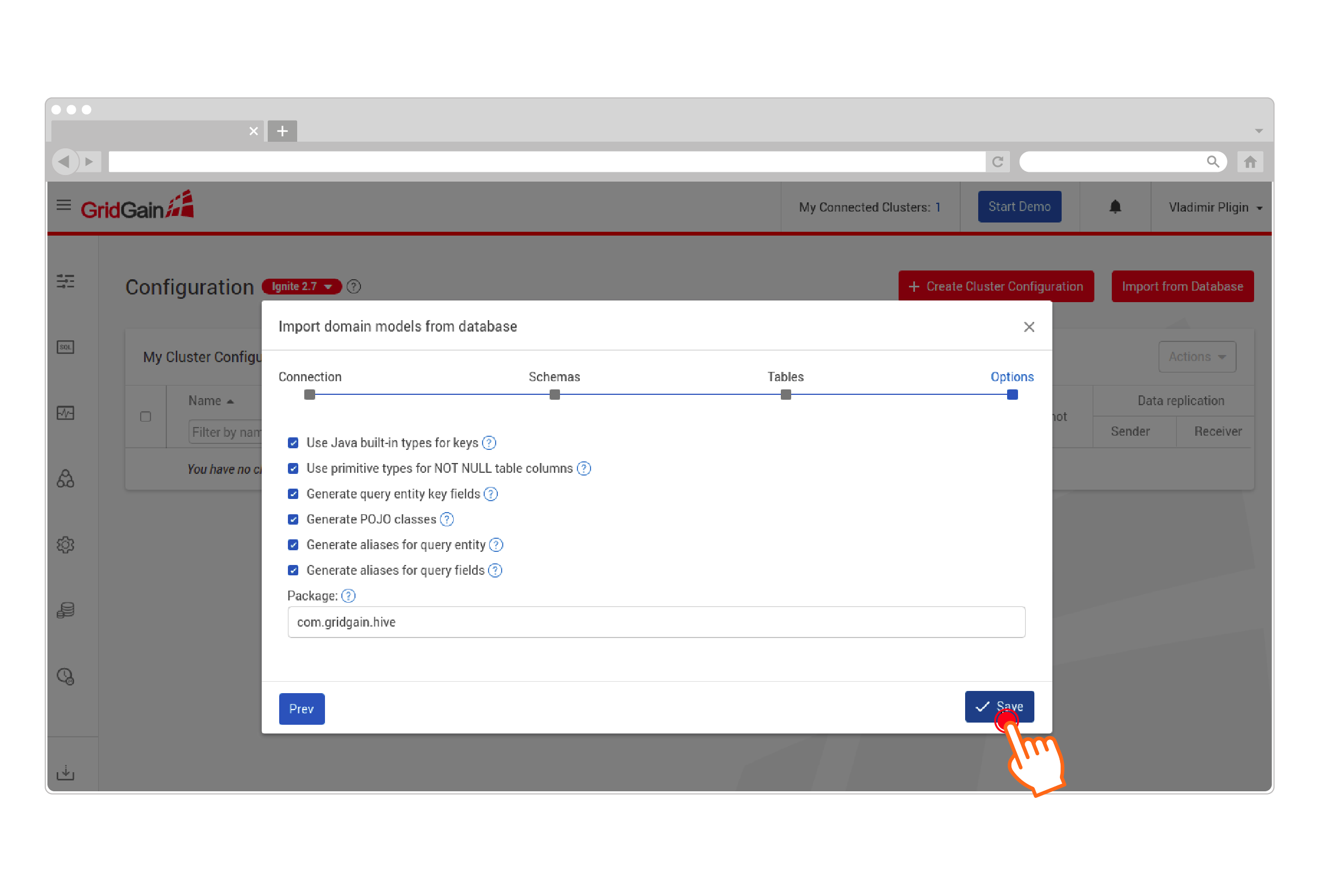
-
Go to the generated configuration page:
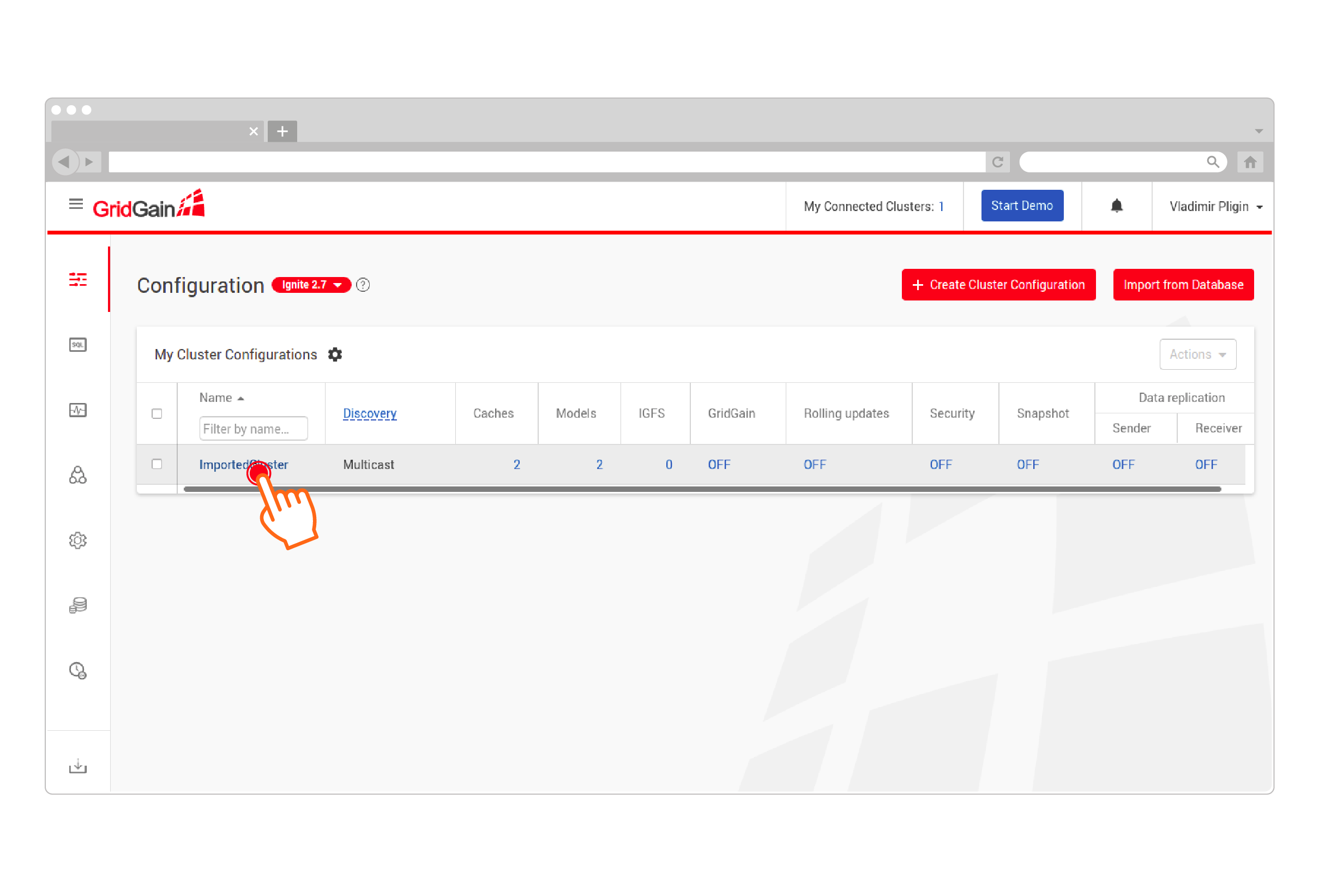
-
Fill in the configuration fields and click Save and Download. GridGain Nebula will generate a maven project and implement the Hive CacheStore and cluster configurations:
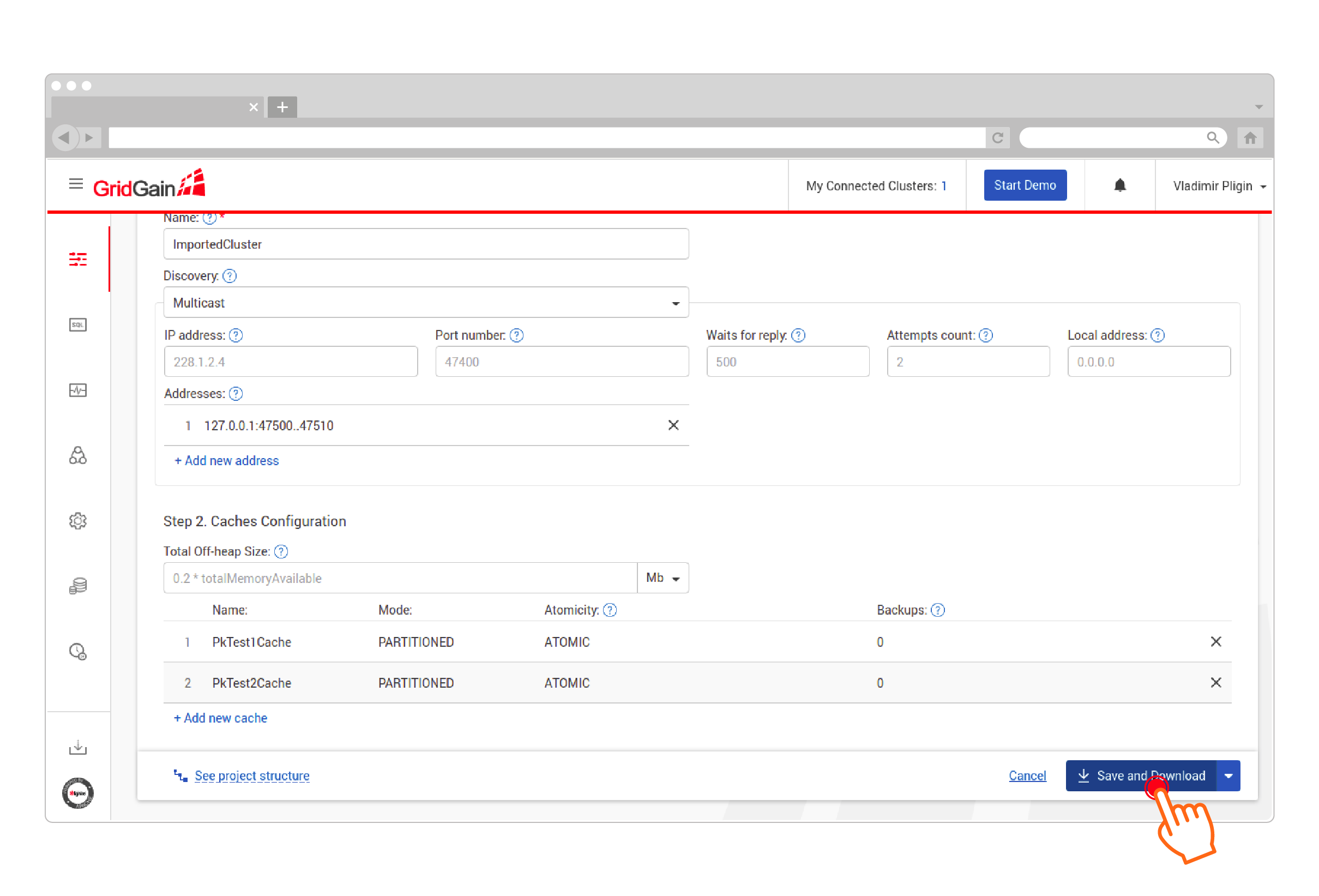
-
Place the Hive JDBC driver in the application java classpath. Here’s an example maven dependency:
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.3.4</version> <exclusions> <exclusion> <groupId>org.eclipse.jetty.aggregate</groupId> <artifactId>jetty-all</artifactId> </exclusion> </exclusions> </dependency>The JDBC driver should be loaded before GridGain caches start:
try { Class.forName("org.apache.hive.jdbc.HiveDriver"); } catch (ClassNotFoundException e) { throw new IllegalStateException("No org.apache.hive.jdbc.HiveDriver", e); } -
Edit the generated
secret.propertiesfile located insrc/main/resources/secret.propertiesand add the Hive connection details. -
Run
ServerNodeSpringStartuporServerNodeCodeStartup(the two classes use different types of configuration).
Data Loading and Synchronization
This section shows how to use HiveCacheJdbcPojoStore for data loading and synchronization:
-
Add the corresponding GridGain Hadoop Connector dependency to the generated project pom:
<dependency> <groupId>org.gridgain.plugins</groupId> <artifactId>gridgain-hive-store</artifactId> <version>{version}</version> </dependency> -
Replace instances of
org.apache.ignite.cache.store.jdbc.CacheJdbcPojoStoreFactorywithorg.gridgain.cachestore.HiveCacheJdbcPojoStoreFactory:HiveCacheJdbcPojoStoreFactory cacheStoreFactory = new HiveCacheJdbcPojoStoreFactory(); -
Set
streamerEnabledto true to enable more efficient data loading:cacheStoreFactory.setStreamerEnabled(true);
Write-through and read-through
Both org.apache.ignite.cache.store.jdbc.CacheJdbcPojoStore and org.gridgain.cachestore.HiveCacheJdbcPojoStore are based on the read-through and write-through cache capabilities.
Read more about these concepts in Database Caching and Read-Through and Write-Through.
The generated project will already contain the code that enables this functionality.
CacheConfiguration ccfg = new CacheConfiguration();
ccfg.setReadThrough(true);
ccfg.setWriteThrough(true);© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.