GridGain for Spark
GridGain is a distributed database for high-performance computing with in-memory speed that is used by Apache Spark users to:
-
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
-
Boost DataFrame and SQL performance.
-
More easily share state and data among Spark jobs.
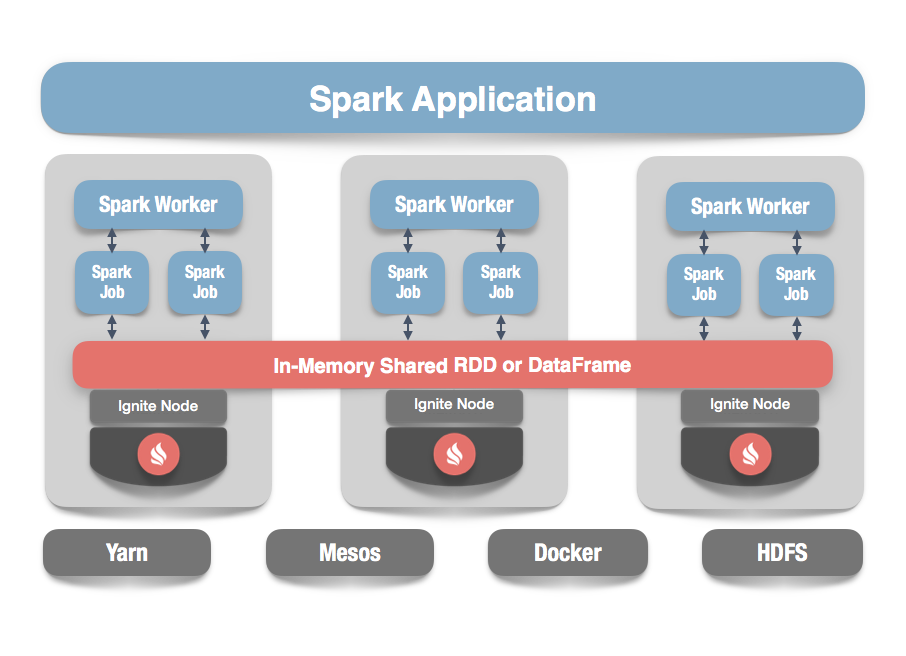
Ignite RDDs
GridGain provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications. Native Spark RDDs cannot be shared across Spark jobs or applications.
The way an IgniteRDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
While Apache SparkSQL supports a fairly rich SQL syntax, it doesn’t implement any indexing. As a result, Spark queries may take minutes even on moderately small data sets because they have to do full data scans. With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Ignite DataFrames
The Apache Spark DataFrame API introduced the concept of a schema to describe the data, allowing Spark to manage the schema and organize the data into a tabular format. To put it simply, a DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database and allows Spark to leverage the Catalyst query optimizer to produce much more efficient query execution plans in comparison to RDDs, which are just collections of elements partitioned across the nodes of the cluster.
Ignite expands DataFrame, simplifying development and improving data access times whenever Ignite is used as memory-centric storage for Spark. Benefits include:
-
Ability to share data and state across Spark jobs by writing and reading DataFrames to/from Ignite.
-
Faster SparkSQL queries by optimizing Spark query execution plans with Ignite SQL engine which include advanced indexing and avoid data movement across the network from Ignite to Spark.
Supported Spark Version
GridGain comes with three modules that support different versions of Apache Spark:
-
ignite-spark-ext 1.0.0 — integration with Spark 2.3
-
ignite-spark-ext 2.0.0 — integration with Spark 2.4
-
ignite-spark-ext 3.0.0 — integration with Spark 3.0
© 2026 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.