
Hadoop Data Lakes are an excellent choice for analytics and reporting at scale. Hadoop scales horizontally and cost-effectively and performs long-running operations spanning big data sets. GridGain, in its turn, enables real-time analytics across operational and historical data silos by offloading Hadoop for those operations that need to be completed in a matter of seconds or milliseconds.
In this guide, you will learn how to set up an architectural solution that integrates Big Data Hadoop with GridGain using GridGain’s Data Lake Accelerator. With this architecture you will continue using Apache Hadoop for high-latency operations (dozens of seconds, minutes, hours) and batch processing leaving it to GridGain to handle those operations that require low-latency response times (milliseconds, seconds) or real-time processing.
What You Will Build
The goal of this blog is to provide a Setup Guide:
- With GridGain Data Lake Accelerator (SparkLoader) running on a local Windows10 laptop.
- Connect to a HortonWorks HDP 2.5 Hadoop platform on an Oracle VM VirtualBox.
- Load the CSV/JSON data into the GridGain Server cache also running on the Windows10 laptop.
- Run an SQL query on the data imported into GridGain Cache via GridGain Web Console SQL tab and a third-party client such as DBeaver.
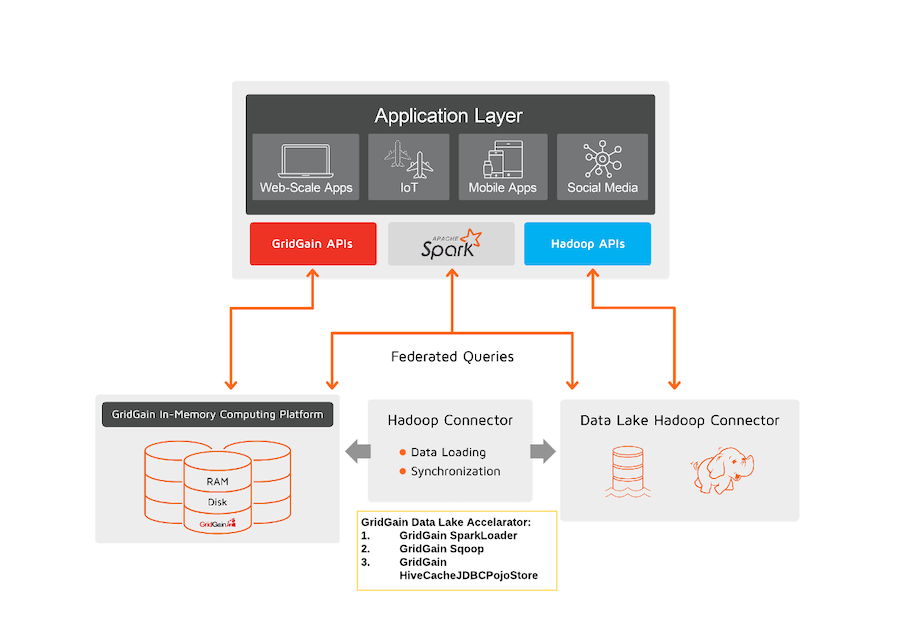
The above diagram shows where Data Lake Accelerator logically fits into your Data Integration Hub architecture
Installing Hadoop HortonWorks
Follow the steps below to set up the development environment:
- Download and install VirtualBox v6.1.x: https://www.virtualbox.org/wiki/Downloads. It is a large download and so be patient, though installing it is straightforward; just follow the onscreen wizard.
- Install Hadoop:
- This project was tested on HortonWorks HDP 2.5 on a windows machine with Oracle VM. Hadoop runs as a docker inside the HortonWorks VM: https://www.cloudera.com/downloads/hortonworks-sandbox/hdp.html
- Be sure to import the Hadoop virtual machine (HDP_2.5_virtualbox) into VirtualBox – don’t just double-click on the image file – and remember to select the 64-bit OS when you do import it.
- Virtualization needs to be enabled, and I’ve seen reports of “Hyper-V” virtualization causing problems if it’s on.
- For the best performance you should have at least 8 GB of RAM to run HDP (HortonWorks Data Platform) on your PC, though more is better. If you have trouble, check your BIOS settings.
- This project was tested on HortonWorks HDP 2.5 on a windows machine with Oracle VM. Hadoop runs as a docker inside the HortonWorks VM: https://www.cloudera.com/downloads/hortonworks-sandbox/hdp.html
On Windows there are some known errors faced when calling from a Spark client to Hadoop:
20/02/04 17:37:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/02/04 17:37:43 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:378)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:393)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:386)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116)
at org.apache.hadoop.security.Groups.<init>(Groups.java:93)
at org.apache.hadoop.security.Groups.<init>(Groups.java:73)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647)
To fix this issue, find on the Internet and install winutils.exe. Set HADOOP_HOME to point to winutils. Download JDK and Spark. Set the following paths and environment variables on your workstation:
C:\Users\rdharampal>echo %HADOOP_HOME%
C:\winutils
C:\Users\rdharampal>echo %JAVA_HOME%
C:\Java\jdk1.8.0_221
C:\Users\rdharampal>echo %SPARK_HOME%
c:\spark
C:\Users\rdharampal>cd c:\winutils
c:\winutils\bin>.\winutils.exe chmod 777 \tmp\hive
c:\winutils\bin>echo %PATH%
C:\Oracle\Database\product\18.0.0\dbhomeXE\bin;C:\Program Files (x86)\Common Files\Oracle\Java\javapath;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;C:\Windows\System32\OpenSSH\;C:\Program Files\Intel\WiFi\bin\;C:\Program Files\Common Files\Intel\WirelessCommon\;C:\Program Files\Git\cmd;C:\Program Files\NVIDIA Corporation\NVIDIA NvDLISR;C:\mingw-w64\i686-8.1.0-posix-dwarf-rt_v6-rev0\mingw32\bin;C:\Program Files\dotnet\;;C:\Program Files\PuTTY\;C:\Program Files\Docker\Docker\resources\bin;C:\ProgramData\DockerDesktop\version-bin;C:\Users\rdharampal\AppData\Local\Microsoft\WindowsApps;C:\apache-maven-3.6.2\bin;C:\Java\jdk1.8.0_221\bin;C:\Users\rdharampal\AppData\Local\atom\bin;C:\Users\rdharampal\AppData\Local\GitHubDesktop\bin;c:\spark\bin;C:\kafka_2.12-2.5.0\bin\windows;C:\Users\rdharampal\AppData\Local\Programs\Microsoft VS Code\bin;C:\apache-hive-3.1.2\bin;
Launching Hadoop Cluster
In this section you will start a Hadoop cluster and load it with sample data.To start the Hadoop cluster do the following:
- Ensure that you have correctly set up HDP as explained in the prior section.
- Power on the HortonWorks Docker Sandbox.
- Once the HDP VM has been imported and started, launch:
- Ambari: http://127.0.0.1:8888/
- Login as user maria_dev/maria_dev
- Launch Dashboard
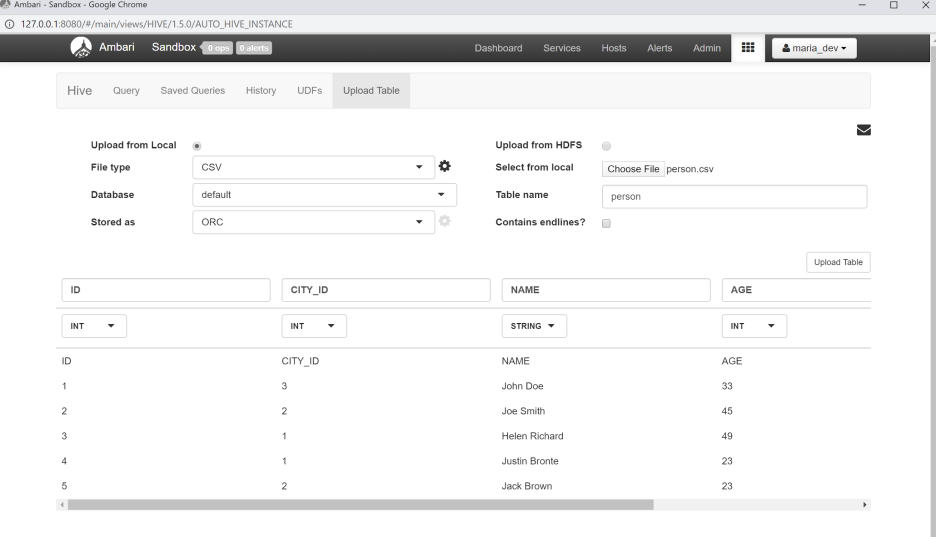
Perform the following steps to upload CSV/JSON files into Hadoop:
Navigate under File View in the upper right-hand corner to the user maria_dev and upload the csv and json files (person.csv and person.json). These two files are provided in my demo code.
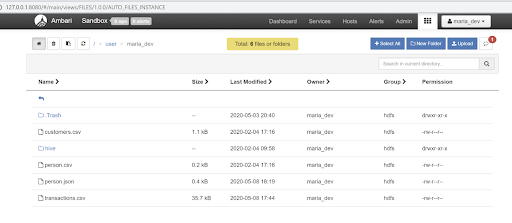
-
Set up PuTTY access to the HDP VM.
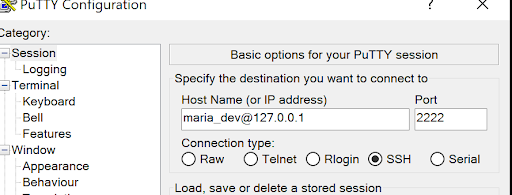
You can also upload the CSV and JSON files via the command prompt as shown below. Scp’ing the file from Windows to the Sandbox container:
c:\Work\Demos\gridgain-hadoop-acceleration-demo\config>scp -P 2222 person.csv maria_dev@localhost:/home/maria_dev
c:\Work\Demos\gridgain-hadoop-acceleration-demo\config>scp -P 2222 person.json maria_dev@localhost:/home/maria_dev
Once the files are in the Sandbox container, put them into the Hadoop File System:
hadoop fs -put person.csv
hadoop fs -put person.json
hadoop fs -ls hdfs://sandbox.hortonworks.com:8020/user/maria_dev

If you use the standard ssh -p 2222 root@localhost, you will actually log into the sandbox Docker container, not the sandbox VM. You can set the password of this Docker root user.
You can log into the sandbox VM using ssh -p 2122 root@localhost. The username is “root” and the password is “hadoop” and this password cannot be changed.
Starting GridGain Cluster
Next, you need to start a GridGain cluster and connect it with GridGain Web Console Management & Monitoring tool. Proceed with the software installation first:
- Download the latest GridGain Enterprise or Ultimate Edition from Download GridGain Software. Please note, GridGain Data Lake Accelerator does not work with the Community Edition. Unpack the Zip file and follow the GridGain Installation steps Installing Using ZIP Archive. We will refer to this directory as IGNITE_HOME.
- Download the GridGain Web Console. Install and configure the GridGain Web Console and Web Agent by referring to the documentation. We will refer to this directory as WEB_CONSOLE_HOME
- Checkout my demo code and import the POM file into your favorite IDE (e.g. Eclipse), build the maven project with ‘clean install’ goals. This imports the necessary scripts, configs and JAR files for this project that are part of the GridGain Data Lake Accelerator or Hadoop Connector. We will refer to this folder as GG_DLA_DEMO.
- Use the startup scripts from the demo source that you have extracted in the folder named GG_DLA_DEMO. Ensure that you have set JAVA_HOME, IGNITE_HOME and WEB_CONSOLE_HOME in the setenv.bat file in the script folder.
- Start up the GridGain Web Console:
C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>.\start-webui.bat C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>[2020-06-05T06:26:56,481][INFO ][main][Application] Starting GridGain Web Console on ROHIT-X1 with PID 45072 [2020-06-05T06:27:06,151][INFO ][main][MigrationFromMongo] MongoDB URL was not specified in configuration [2020-06-05T06:27:06,151][INFO ][main][MigrationFromMongo] Migration from old Web Console will not be executed [2020-06-05T06:27:06,152][INFO ][main][MigrationFromMongo] Migration instructions: https://www.gridgain.com/docs/web-console/latest/migration [2020-06-05T06:27:06,920][INFO ][ThreadPoolTaskExecutor-1][Application] Full log is available in C:\Users\rdharampal\apache-ignite-developer-training\GGDevTrainee\runtime\gridgain-web-console-2020.02.00\work\log [2020-06-05T06:27:06,921][INFO ][ThreadPoolTaskExecutor-1][Application] GridGain Web Console started on TCP port 3000 in 10.9255695 seconds [2020-06-05T06:27:07,204][INFO ][qtp862062296-117][BrowsersService] Browser session opened [socket=JettyWebSocketSession[id=431b7476-ea3a-f59e-cf7d-3ad7696c7d5e, uri=ws://localhost:3000/browsers?demoMode=false]] [2020-06-05T06:27:07,204][INFO ][qtp862062296-20][BrowsersService] Browser session opened [socket=JettyWebSocketSession[id=a849beba-9909-dd1c-5c6c-3bf29e20ef37, uri=ws://localhost:3000/browsers?demoMode=false]]Check the status by logging in at: http://localhost:3000. At this point there are no clusters reporting to the Web Console. We will start them in the following steps.
Start up the GridGain Node:
C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>.\start-node.batNote: HDP 2.5 uses port 8080 via Oracle Virtual VM Box and so you must choose a different REST port while starting GridGain Ignite (I chose port 7080 in the start-node.bat. You can choose a different port as needed).
C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>.\start-node.bat Ignite Command Line Startup, ver. 8.7.10#20191227-sha1:c481441d 2019 Copyright(C) GridGain Systems, Inc. and Contributors [06:28:15,755][WARNING][main][G] Ignite work directory is not provided, automatically resolved to: C:\Users\rdharampal\apache-ignite-developer-training\GGDevTrainee\runtime\gridgain-ultimate-8.7.10\work [06:28:15,859][INFO][main][IgniteKernal] >>> __________ ________________ >>> / _/ ___/ |/ / _/_ __/ __/ >>> _/ // (7 7 // / / / / _/ >>> /___/\___/_/|_/___/ /_/ /___/ >>> >>> ver. 8.7.10#20191227-sha1:c481441d >>> 2019 Copyright(C) GridGain Systems, Inc. and Contributors >>> >>> Ignite documentation: http://gridgain.com [06:28:15,860][INFO][main][IgniteKernal] Config URL: file:/C:/Work/Demos/gridgain-hadoop-acceleration-demo/scripts/../config/server.xmlStart up the Web Agent:
C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>.\start-web-agent.bat C:\Work\Demos\gridgain-hadoop-acceleration-demo\scripts>[2020-06-05T06:30:15,157][INFO ][main][AgentLauncher] Starting Apache GridGain Web Console Agent... [2020-06-05T06:30:15,268][INFO ][main][AgentLauncher] [2020-06-05T06:30:15,269][INFO ][main][AgentLauncher] Web Console Agent configuration : [2020-06-05T06:30:15,354][INFO ][main][AgentLauncher] User's security tokens : ********************************6441 [2020-06-05T06:30:15,355][INFO ][main][AgentLauncher] URI to Ignite node REST server : http://127.0.0.1:7080 [2020-06-05T06:30:15,356][INFO ][main][AgentLauncher] URI to GridGain Web Console : http://localhost:3000 [2020-06-05T06:30:15,358][INFO ][main][AgentLauncher] Path to properties file : default.properties [2020-06-05T06:30:15,358][INFO ][main][AgentLauncher] Path to JDBC drivers folder : C:\Users\rdharampal\apache-ignite-developer-training\GGDevTrainee\runtime\gridgain-web-console-2020.02.00\web-agent\jdbc-drivers [2020-06-05T06:30:15,358][INFO ][main][AgentLauncher] Demo mode : enabled [2020-06-05T06:30:15,359][INFO ][main][AgentLauncher] [2020-06-05T06:30:15,429][INFO ][main][WebSocketRouter] Starting Web Console Agent... [2020-06-05T06:30:15,436][INFO ][Connect thread][WebSocketRouter] Connecting to server: ws://localhost:3000 [2020-06-05T06:30:16,165][INFO ][http-client-17][WebSocketRouter] Successfully completes handshake with server [2020-06-05T06:30:16,289][INFO ][pool-2-thread-1][ClusterHandler] Connected to node [url=http://127.0.0.1:7080] [2020-06-05T06:30:16,312][INFO ][pool-2-thread-1][ClustersWatcher] Connection successfully established to cluster with nodes: [1AA10D83]At this point, we have a Web Agent that connects a running GridGain node to the Web Console. Open the GridGain Web Console Dashboard screen and you should see a cluster being reported at the top.
Scroll down to the “Caches” section and check that an empty cache “Person” has been initialized:

- Start up the GridGain Web Console:
Load Data Into GridGain From Hadoop
With both GridGain and Hadoop clusters running, you are ready to load GridGain with data from Hadoop. While in this guide GridGain keeps a full copy of Hadoop’s data, in real life you will be loading only a data subset needed for low-latency and high-throughput operations to be executed through GridGain.
Now that your Maven project is built, you are ready to run the demo. Ensure that your project folder looks something like this:
C:\Work\Demos\gridgain-hadoop-acceleration-demo>dir Volume in drive C has no label. Volume Serial Number is 78AB-9467 Directory of C:\Work\Demos\gridgain-hadoop-acceleration-demo 05/21/2020 11:10 AM <DIR> . 05/21/2020 11:10 AM <DIR> .. 05/21/2020 08:02 AM 1,088 .classpath 05/21/2020 08:01 AM 318 .gitignore 05/21/2020 08:02 AM 569 .project 05/21/2020 08:02 AM <DIR> .settings 05/21/2020 08:01 AM <DIR> config 05/21/2020 08:16 AM <DIR> img 05/21/2020 08:01 AM 11,357 LICENSE 05/21/2020 08:01 AM 2,483 pom.xml 05/21/2020 08:18 AM 1,030 README.md 05/21/2020 08:01 AM <DIR> scripts 05/21/2020 08:01 AM <DIR> src 05/21/2020 11:10 AM <DIR> target 6 File(s) 16,845 bytes 8 Dir(s) 705,501,728,768 bytes free C:\Work\Demos\gridgain-hadoop-acceleration-demo>Load data from Hadoop using HadoopSparkCSV SparkLoader:
C:\Work\Demos\gridgain-hadoop-acceleration-demo> java -cp ".\target\libs\*;.\target\gridgain-dla-demo-1.0.0.jar" org.gridgain.dla.sparkloader.HadoopSparkCSV .\config\client.xml hdfs://sandbox.hortonworks.com:8020/user/maria_dev/person.csv trueThe console output will scroll and should look something like this:
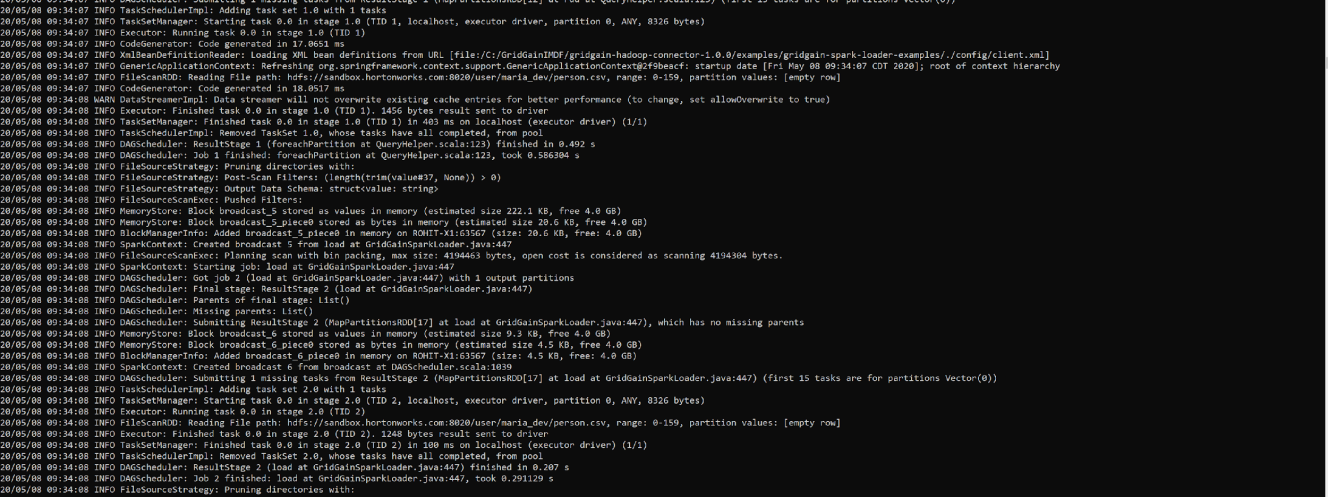
The HadoopSparkCSV SparkLoader Application retrieves the CSV from the HDFS and creates a Cache table in GridGain. See below:

- Add the following property to hdfs-site.xml in your sandbox: <property><name>dfs.client.use.datanode.hostname</name><value>true</value></property>
- Add a port forwarding rule in your VM to 50010
- Enable NAT forwarding on hostbox
- Spark only: SparkSession.builder().config("spark.hadoop.dfs.client.use.datanode.hostname", "true").[...]
- Edit your Windows hosts file on your laptop (c:\windows:\System32\drivers\etc) and set the following: 127.0.0.1 localhost sandbox.hortonworks.com
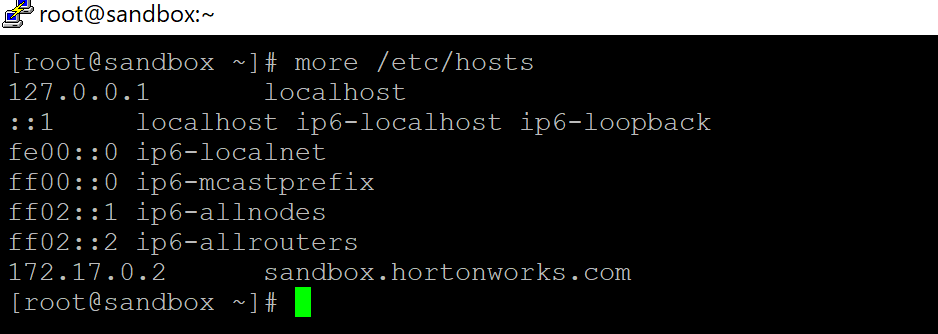
- Login as root via putty to your sandbox and ensure that it has the last entry in /etc/hosts:
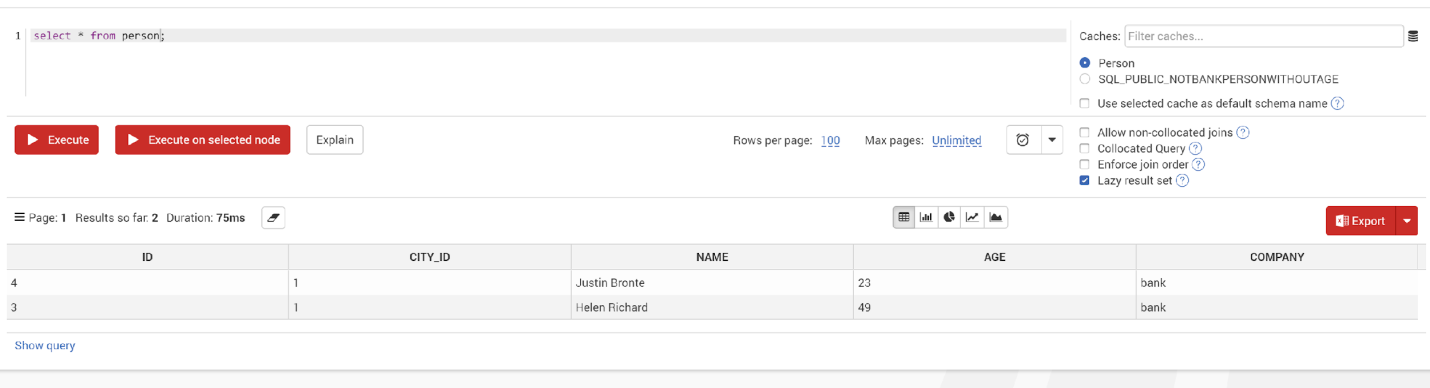
Check the SQL Notebook tab in the Web Console and run a query such as:
select * from personVerify that the persons working at the bank have been populated in the Person cache.
You can also verify the caches in GridGain via a third party SQL client such as DBeaver:
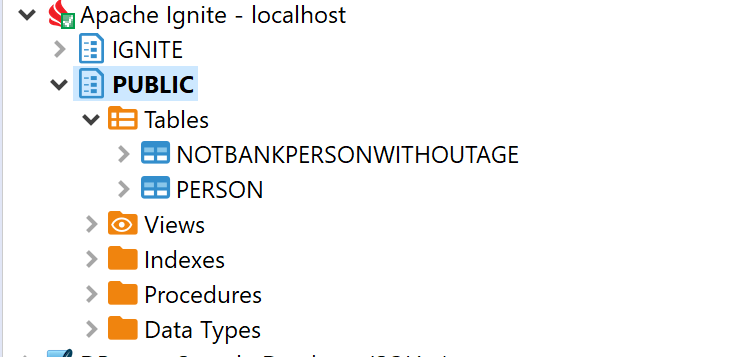
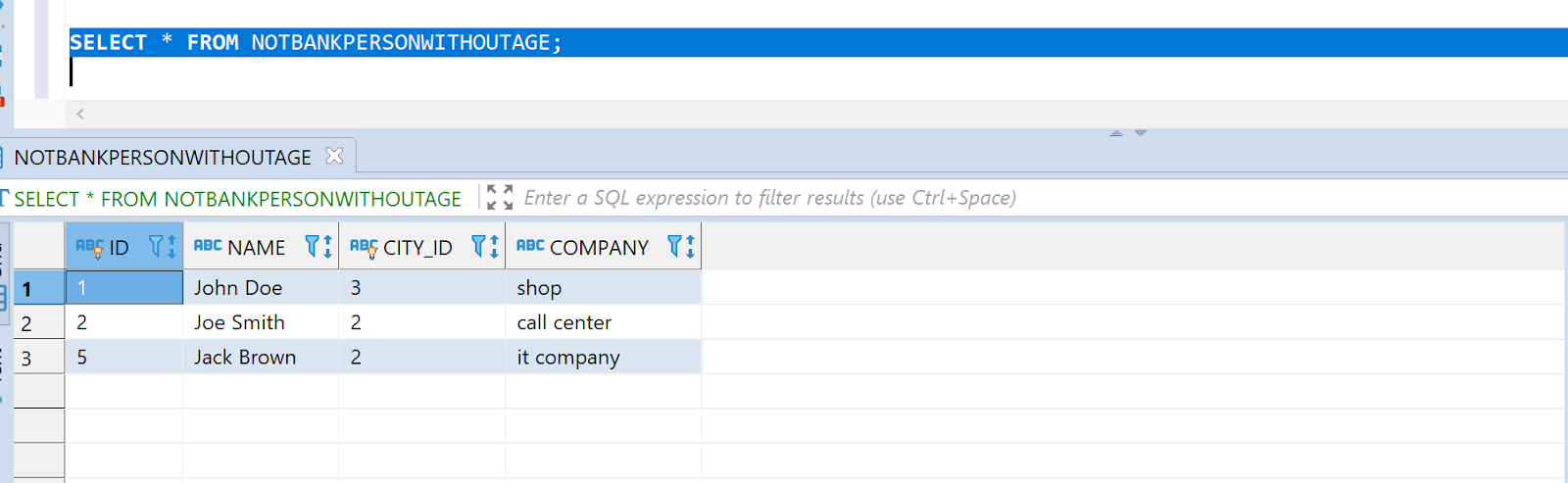
Verify that the above SQL returns values that match the person.csv you uploaded to HDFS:
Stop and start GridGain Server and this time run the HadoopSparkJSON application:
C:\Work\Demos\gridgain-hadoop-acceleration-demo>java -cp ".\target\libs\*;.\target\gridgain-dla-demo-1.0.0.jar" org.gridgain.dla.sparkloader.HadoopSparkJSON .\config\client.xml hdfs://sandbox.hortonworks.com:8020/user/maria_dev/person.json trueCheck that you get the same results in the GridGain cluster.
Some issues you may run into with HortonWorks HDP sandbox and how to resolve them:
DLA Sparkloader (HadoopSparkCSV.java) connects to Hadoop’s NameNodes; namenodes returns the IP of datanode where the csv is set to 172.17.0.2 and that is where it receives its connection exception:
FSClient:Failed to connect to /172.17.0.2:50010 for block
Query Data From GridGain and Hadoop
Conclusion
You have demonstrated that you can easily ingest/load semi-structured data such as CSV or JSON from Hadoop into GridGain using the Data Lake Accelerator API.
Once in the cache, you can employ the powerful GridGain/Ignite API: SQL, Continuous Query, Compute, Service, ML, etc.
Hadoop continues to be utilized for batch processing while GridGain serves your real-time processing needs.
In future articles I will showcase more integration use cases such as how you can replicate your data in other integration points like Kafka once you have ingested and enriched it in your GridGain cache.