
I’ve created a checklist for new users of Apache® Ignite™ to help overcome common challenges I’ve seen people encounter when developing and configuring their first applications with an Ignite cluster. This checklist was put together from questions new users routinely ask the Apache Ignite community on the user and dev lists.
If you are new to Apache Ignite, click here for a quick introduction and refresher course on Apache Ignite.
In a nutshell, this post will discuss how to ensure that your Apache Ignite cluster has been assembled properly from the very beginning. You’ll also learn how to run some computations in the Compute Grid -- and then how to prepare a data model and the code to further write your data into Ignite and successfully read it later.
And, importantly, how not to break anything from the very beginning.
Preparing for launch: Configuring your logs
First off, we'll need logs. If you’ve ever read or submitted a question in the Apache Ignite newsletter or on StackOverflow (e.g. «why everything has frozen»), chances are, the response includes a request for the logs from each of the nodes.
Yes, logging is enabled in Apache Ignite by default. But there are some peculiarities to Apache Ignite log configuration. By default, Ignite starts in "quiet" mode suppressing INFO and DEBUG log output. If the system property IGNITE_QUIET is set to “false” then Ignite will operate in normal un-suppressed logging mode. Note that all output in "quiet" mode is done through standard output (STDOUT).
Only the most critical errors are seen in stdout and any others will be logged in a file, a path to which Apache Ignite gives at the very beginning (by default — ${IGNITE_HOME}/work/log). Don’t delete it! This may come in very handy in the future.
stdout Ignite when starting by default
For simpler issue discovery -- without pouring over discrete files and without setting standalone monitoring for Apache Ignite -- you can start it in verbose-mode with the command:
ignite.sh -v
The system will then print out all of the events into stdout together with the other application logging information.
Check the logs! Very often you can find solutions to your problems in the logs. For instance, if the cluster falls apart, chances are that you find messages like «Increase the said timeout in the said configuration. We have detached from it. It is too small. The network quality is poor».
Cluster Assembly
The first problem that many newbies encounter is that of “uninvited guests” in your cluster. Here’s what I mean by that: You startup a fresh cluster and suddenly you see that in the first topology snapshot, instead of one node, you have two servers from the very beginning. How can this happen when you only started a single server?
A message stating that there are two nodes in the cluster
![]()
This can happen because, by default, Apache Ignite uses Multicast upon starting and that seeks out any other Apache Ignite instances located in the same subnet -- within the same Multicast group. Having found any such nodes, it attempts to establish connections with them. If the connection fails, the whole “start” can fail altogether.
To prevent this from happening, the simplest solution is to set static IP-addresses. Instead of TcpDiscoveryMulticastIpFinder used by default you can leverage TcpDiscoveryVmIpFinder. Then specify all of the IPs and ports to which you’re connecting to. This will protect you from most problems, especially in testing and development environments.
Too many IP addresses?
Noticing that you have too many IP addresses is the next common issue. Let’s go over what’s happening. Having disabled Multicast, you start your cluster. You have one config where you have specified a lot of IPs from different environments. There are times when you need 5 to 10 minutes to start the first node in the new cluster, although the subsequent nodes connect to it in 5 to 10 seconds each.
Take for example a list of 3 IP-addresses. For each address we specify a range of 10 ports. We get 30 TCP-addresses in total. By default, Apache Ignite will try to connect to an existing cluster before creating a new cluster and it will check each IP in turn.
This is probably a minor problem if you are working on project just your laptop. However, cloud providers and corporate networks often enable port scanning protection. That means, when you attempt to access a private port on certain IP-addresses, you’ll get no answer before the timeout expires. By default, this timeout is 10 seconds.
The solution is trivial: do not specify excessive ports. In production systems a single port is usually enough. You can also disable the port scanning protection for the intranet.
IPv4 vs IPv6
Тhe third common issue has to do with IPv6. You may encounter strange network error messages along the lines of: “failed to connect” or “failed to send a message, node segmented.” This happens if you have detached from the cluster. Very often, such problems arise because of the heterogeneous environment of IPv4 and IPv6. Apache Ignite supports IPv6, but there are some issues with it.
The simplest solution is to supply the JVM the option:
-Djava.net.preferIPv4Stack=true
After that, Java and Apache Ignite are configured to not use IPv6. Problem solved.
Configuring the Apache Ignite codebase
At this point, the cluster has been assembled. One of the main interaction points between your code and Apache Ignite is “Marshaller” (serialization). To write anything into memory, persistence or send over network, Apache Ignite first serializes your objects. You might see messages like “cannot be written in binary format” or “cannot be serialized using BinaryMarshaller.” When this happens, you’ll need to tweak your code a little more to couple it with Apache Ignite.
Apache Ignite uses three serialization mechanism:
- JdkMarshaller — common Java-serialization;
- OptimizedMarshaller — optimized Java-serialization, but essentially the same;
- BinaryMarshaller — a serialization, implemented specifically for Apache Ignite. It has many advantages. Sometimes we can get rid of excessive serialization/deserialization, sometimes we even can give an API an unserialized object and handle it in binary format, as with JSON.
BinaryMarshaller will be able to serialize and deserialize your POJO that contain nothing except fields and simple methods. But when you use a custom serialization via readObject() and writeObject(), if you leverage Externalizable, your BinaryMarshaller won't be able to serialize your object, simply having written the non-transient fields and will give up – it falls back to OptimizedMarshaller.
If this happens you must implement the Binarylizable interface. It’s very straightforward.
For example, we have a standard TreeMap from Java. It uses custom serialization and deserialization via read and write object. First it describes some fields, then writes out to OutputStream the length and data as such.
TreeMap.writeObject()implementation
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out the Comparator and any hidden stuff
s.defaultWriteObject();
// Write out size (number of Mappings)
s.writeInt(size);
// Write out keys and values (alternating)
for (Iterator<Map.Entry<K,V> i = entrySet().iterator(); i.hasNext(); ) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}writeBinary() and readBinary() from Binarylizable work the same way: BinaryTreeMap wraps itself into simple TreeMap and writes it out to OutputStream. Such method is trivial to code, and it gives a significant performance boost.
BinaryTreeMap.writeBinary()implementation
public void writeBinary(BinaryWriter writer) throws BinaryObjectException {
BinaryRawWriter rewriter = writer. rewrite ();
rawWriter.writeObject(map.comparator());
int size = map.size();
rawWriter.writeInt(size);
for (Map.Entry<Object, Object> entry : ((TreeMap<Object, Object>)map).entrySet()) {
rawWriter.writeObject(entry.geKey());
rawWriter.writeObject(entry.getValue());
}
}
Run in Compute Grid
Ignite allows you to run distributed computations. How do we run a lambda expression so that it spreads across all servers and then runs?
First, let's investigate what's wrong with these code examples.
Can you identify the problem?
Foo foo =...;
Bar bar =...;
ignite.compute().broadcast(
() ->doStuffWithFooAndBar(foo, bar)
);
And so?
Foo foo =...;
Bar bar =...;
ignite.compute().broadcast(new IgniteRunnable() {
@Override public voide run() {
doStuffWithFooAndBar(foo, bar);
}
});
Those familiar with the pitfalls of lambda expressions and anonymous classes know that the problem arises when you capture outside variables. Anonymous classes are even more complicated.
One more example. Here we have a lambda again using the Apache Ignite API.
Using Ignite inside compute closure the wrong way
ignite.compute().broadcast(() {
IgniteCache foo = ignite.cache("foo");
String sql = "where id = 42";
SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true);
return foo.query(qry);
});
What’s happening here is basically that Ignite takes the cache and performs some SQL-query locally. This comes in handy when you need to send a task working only with local data on remote nodes.
What is the issue here? Lambda captures a reference again, but this time not to an object, but to the local Ignite instance on the node, from which we send it. This approach even works, because Ignite object has a readResolve()method, which allows by deserialization to substitute the Ignite, acquired over the network, with a local one on the target node. But this approach also can lead to undesired consequences.
Essentially, you simply transfer via network more data, than you would like to. If you need to reach out from any code, which you don't control, to Apache Ignite or whatever interfaces of it, the method Ignintion.localIgnite()is always for your convenience. You can call it from any thread, created by Apache Ignite and get the reference to a local object. If you have lambdas, services, whatever, and you are sure, that here you need Ignite, I advise you to proceed so.
Using Ignite inside compute closure correctly — via localIgnite()
ignite.compute().broadcast(() -> {
IgniteCache foo = Ignition.localIgnite().cache("foo");
String sql = "where id = 42";
SqlQuery qry = new SqlQuery("Foo", sql).setLocal(true);
return foo.query(qry);
});
The last example for this part. There is a Service Grid in Apache Ignite, which allows you to deploy microservices right in the cluster, and Apache Ignite assists you permanently keep online as many instances as you need. Imagine, we need a reference to Apache Ignite in this service too. How to get it? We could use localIgnite(), but in that case we would need to manually retain this reference in the field.
The service keeps Ignite in the field wrong — it accepts the reference as a constructor argument
MyService s = new MyService(ignite)
ignite.services().deployClusterSingleton("svc", s);
...
public class MyService implements Service {
private Ignite ignite;
public MyService(Ignite ignite) {
this.ignite = ignite;
}
...
}
This could be done in a simpler way. But we still have full-fledged classes, not lambda, so we can annotate the field with @IgniteInstanceResource. Having created the service, Apache Ignite will put itself into it, then you could easily use it. I very advise you to do so, but not to try passing into constructor Apache Ignite as such and its child objects.
The service uses @IgniteInstanceResource
public class MyService implements Service {
private Ignite ignite;
public MyService() { }
...
}
Writing and Reading Data: Monitoring the Baseline
Now we have an Apache Ignite cluster and duly prepared code.
Let's imagine this scenario:
- One REPLICATED cache — data replicas present on every node;
- Native persistence enabled — writing to disk.
Start one node. Because native persistence is enabled, we must activate the cluster before using it. Activate. Then run some more nodes.
It kinda works: reads and writes proceed as expected. We have data replicas on every node. We can easily shut down one node. But if we stop the very first node, everything breaks down: the data disappears and the operations stall. This is because of baseline topology — the set of nodes where we store persistent data. Other nodes contain no persistent data.
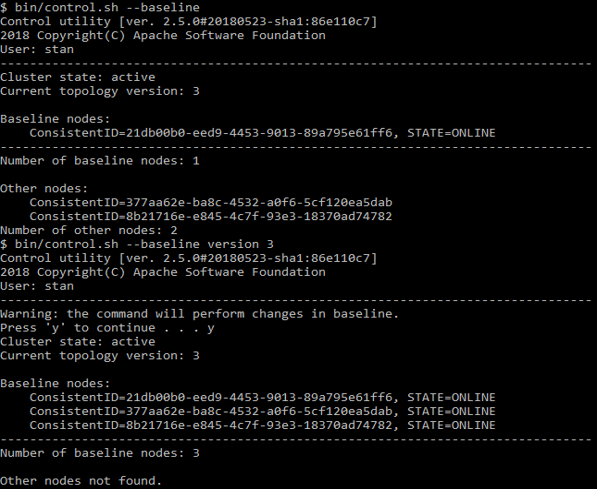
This set of nodes is initially defined at the time of activation. The nodes, that will be added later, will be not included into the baseline topology set. Consequently, the baseline topology contains of a single node being started first, and without it everything breaks down. To avoid this you should first start all the nodes and only then activate the cluster. If you need to add or remove a node with the command:
control.sh --baseline
This script also helps to refresh the baseline, making it up-to-date.
control.sh use case
Data colocation
We are now sure that the data is persisted, so let’s try to read it. We enjoy SQL support, so we can do SELECT — exactly as in Oracle. But, we can also scale and start on every number of nodes because the data is distributed. Consider such a model:
public class Person { @QuerySqlField public Long id; @QuerySqlField public Long orgId; } public class Organization { @QuerySqlField private Long id; }
Query:
SELECT * FROM Person as p JOIN Organization as o ON p.orgId = o.id
The example above won’t return all of the data. What’s wrong?
Here, (Person) references an organization (Organization) by ID. It’s a typical foreign key. But if we try to join two tables and send an SQL-query, then -- provided there are several nodes in the cluster -- we won’t get all of the data.
This is because by default SQL JOIN works only on a single node. If SQL would traverse the entire cluster to collect the data and return the whole response, it would be incredibly slow. We would sacrifice all the advantages of a distributed system. So Apache Ignite looks up only the local data.
To get the correct results, we need to collocate the data. To join Person and Organization correctly, the data from both tables should be stored on the same node.
The simplest way to do this is to declare an affinity key. This key determines the exact node and partition the given value will be. When declaring an organization ID in Person as an affinity key, the persons with this organization ID should be located on the same node.
If for some reason you cannot do this, there is another, less effective solution -- enable distributed joins. This is done through an API, and the procedure depends on whether you are using Java, JDBC, or something else. Then the JOIN will be slower, but will at least return the correct results.
Consider how to handle affinity keys. How can we conclude that a specific ID and associated field is suitable to define affinity? If we state that all persons with the same orgId will be collocated, then orgId is a single indivisible block. We can’t distribute it across multiple nodes. If we store 10 organizations in the database, then we’ll have 10 indivisible blocks that can be stored on 10 nodes. If there are more nodes in the cluster, then all «redundant» nodes won’t belong to any block. This is very hard to determine at runtime, so plan it in advance.
If you have one large organization and nine small ones, block size will also be different. But Apache Ignite doesn't regard how many records are in affinity groups when distributing them across nodes. It won’t locate a large block on one node and the nine remaining blocks on another one to balance the load. Much more likely, it will decide to store 5 and 5, (or 6 and 4, or even 7 and 3).
How to make the data evenly distributed? Let us have:
- Two keys
- Various affinity keys
- P partitions, that is, large groups of data that Apache Ignite will distribute between the nodes.
- N nodes
Then you need to satisfy the condition:
K >> A >> P >> N
where >> is "much more" and the data will be distributed relatively evenly.
Review! Checklist for Apache Ignite novices
- Config, read, keep logs
- Disable multicast, specify only the addresses and ports you actually use
- Disable IPv6
- Prepare your classes for BinaryMarshaller
- Track your baseline
- Adjust affinity collocation
Check out Apache Ignite vs Apache Spark: Integration using Ignite RDDs for information on using Apache Ignite and Apache Spark together.