Distributed Training
Overview
Distributed training allows computational resources to be used on the whole cluster and thus speed up training of deep learning models. TensorFlow is a machine learning framework that natively supports distributed neural network training, inference and other computations. The main idea behind the distributed neural network training is the ability to calculate gradients of loss functions (squares of the errors) on every partition of data (in terms of horizontal partitioning) and then sum them to get the loss function gradient of the whole dataset:
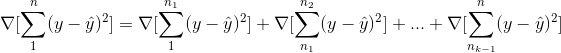
Using this ability, we can calculate gradients on the nodes the data are stored on, reduce them and then finally update model parameters. This avoids data transfers between nodes and thus prevents network bottlenecks.
Apache Ignite uses horizontal partitioning to store data in a distributed cluster. When we create an Apache Ignite cache (or table in terms of SQL), we can specify the number of partitions the data will be partitioned on. For example, if an Apache Ignite cluster consists of 10 machines and we create a cache with 10 partitions, then every machine will maintain approximately one data partition.
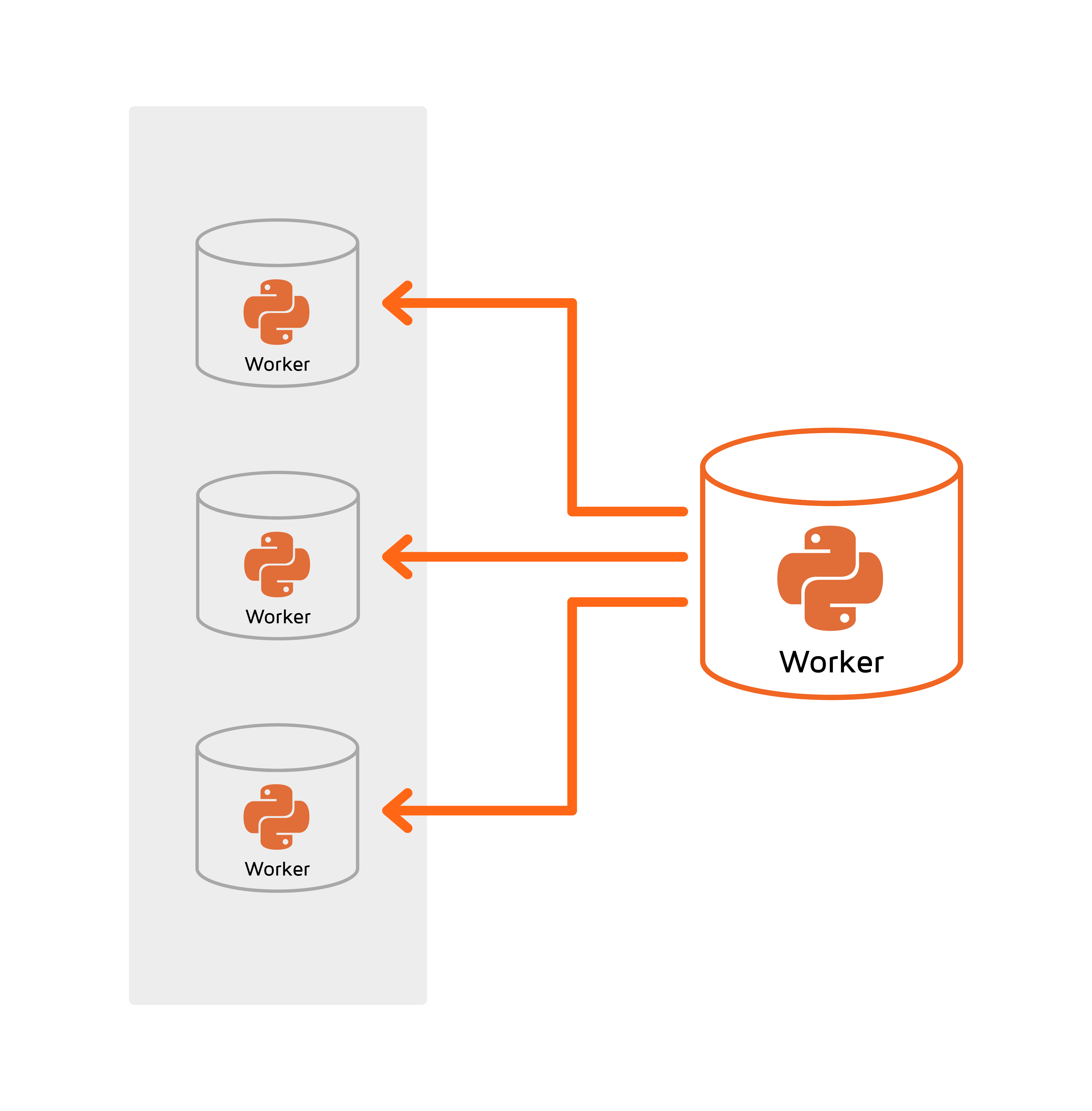
Distributed Training in TensorFlow on Apache Ignite is based upon the standalone client mode of distributed multi-worker training. Standalone client mode assumes that we have a cluster of workers with started TensorFlow servers and we have a client that actually contains model code. When the client calls tf.estimator.train_and_evaluate TensorFlow uses a specified distribution strategy to distribute computations across workers so that the most computationally intensive part performs on workers.
Standalone client mode on Apache Ignite
For TensorFlow on Apache Ignite, one of the most important goals is to avoid redundant data transfers and utilize data partitioning which is a core concept of Apache Ignite. Apache Ignite provides so called Zero ETL. To achieve this goal, TensorFlow workers are started and maintained on the nodes the data are stored on. The following diagram illustrates this idea:
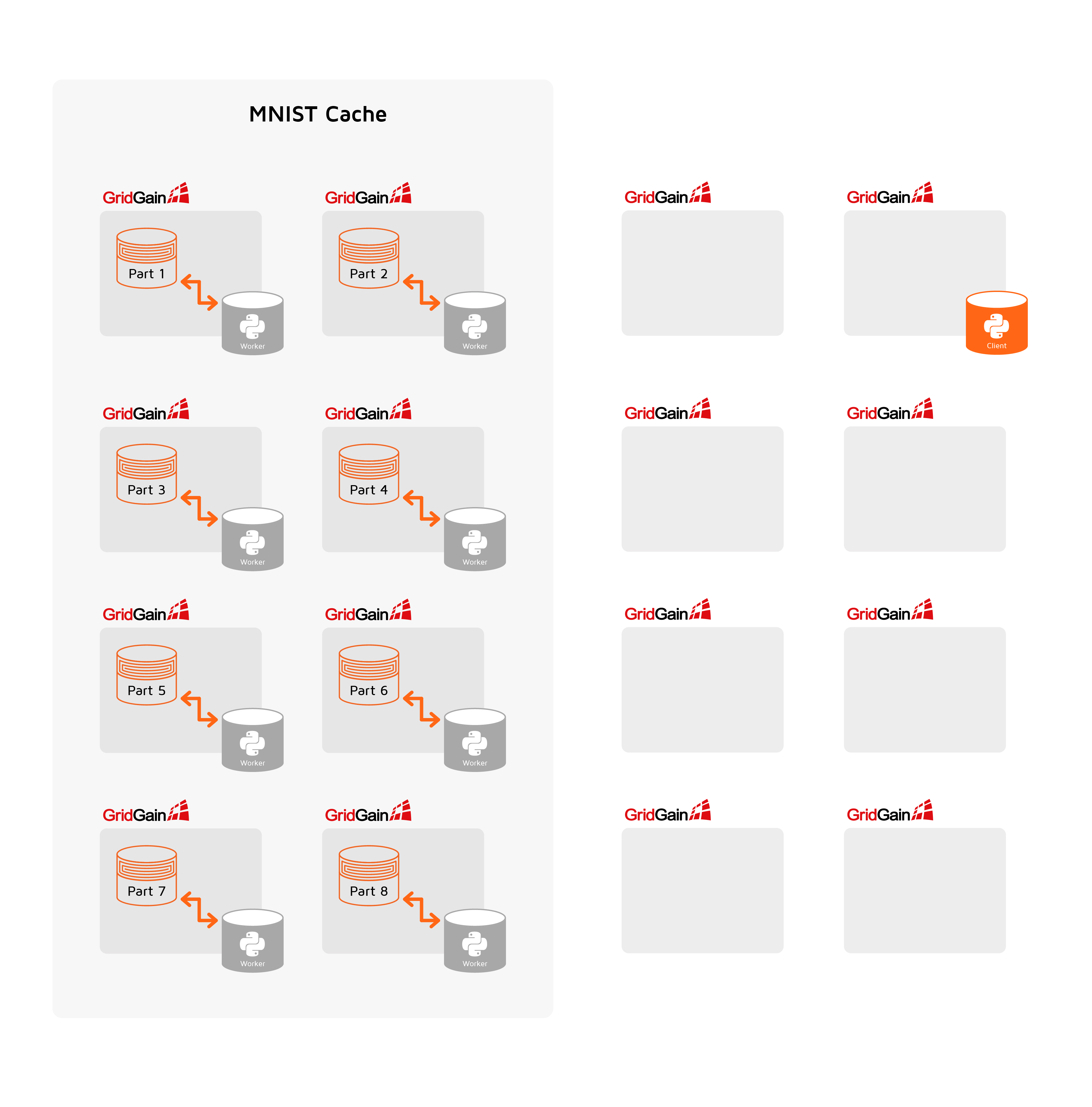
As we can see in the diagram, the MNIST Cache in an Apache Ignite cluster is distributed across 8 servers (1 partition per server). In addition to maintaining the data partition, each server maintains a TensorFlow worker. Each worker is configured to have access to its local data only (this “stickiness” is configured via an environment variable).
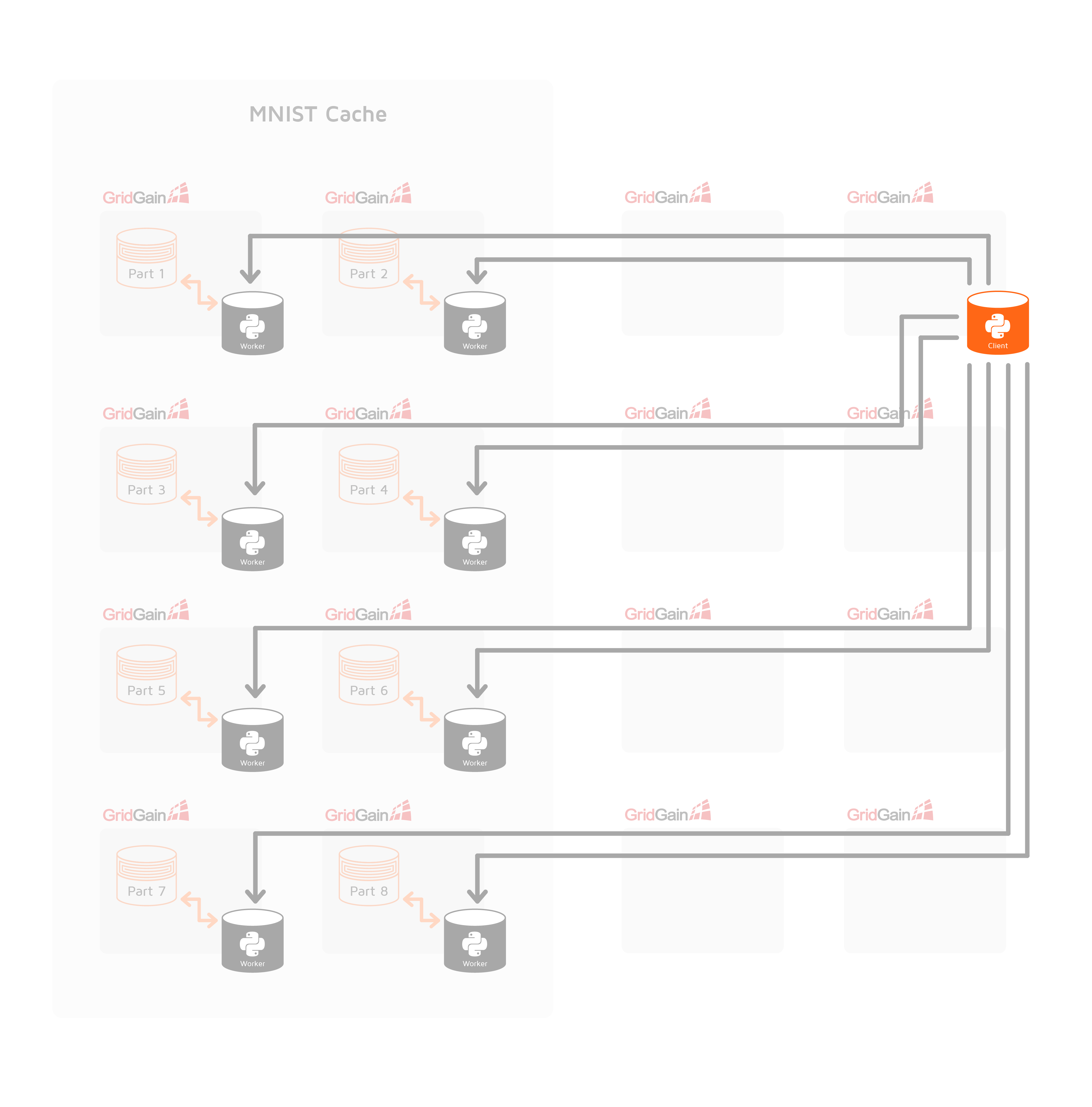
Unlike classic standalone client mode in TensorFlow on Apache Ignite, the client process is also started inside an Apache Ignite cluster as a service. This allows Apache Ignite to automatically restart training in case of any failure or after data rebalancing events.
When initialization is completed and a TensorFlow cluster is configured, Apache Ignite does not interfere with TensorFlow work. Only in the case of failures and data rebalancing events, Apache Ignite restarts a cluster. During the normal mode of operation we can consider the whole infrastructure as shown in the following diagram:
© 2024 GridGain Systems, Inc. All Rights Reserved. Privacy Policy | Legal Notices. GridGain® is a registered trademark of GridGain Systems, Inc.
Apache, Apache Ignite, the Apache feather and the Apache Ignite logo are either registered trademarks or trademarks of The Apache Software Foundation.