
In this post, I will cover the changes in Apache® Ignite™ 2.0/2.1 (which tracks to GridGain 8.0/8.1) that are important when implementing a project in Ignite. Then we will discuss the easiest way to setup a cache and just use the basic functionality of the Data Grid.
So, Apache Ignite 2.0 & 2.1 have dropped! This is awesome news for you as a user. This is fun times for us at GridGain too. However, things have radically changed in the codebase of good old Apache Ignite since my last blogpost. Fear not, if you are starting out I am here to show you where to go to navigate the new lay of the land. YAY!
Alright - first things first. On the off chance you are already rolling with a previous version of Apache Ignite (meaning prior to 2.0) this blogpost can still help you. The lovely folks who I am honored to call my team have provided this handy dandy migration guide to make your life a lot easier. The shift to 2.0 will provide performance enhancements should you make the plunge and other benefits I will dive into in a moment. Yet there are those that are looking for that quick and dirty migration link, so there you are without much ado. If you need help and have migration questions - I am happy to be a pal, reach out @dtrapezoid in the land of Twitter.

You will also find relevancy in this post as you explore the new concepts within the new releases which include our persistence store and virtual or durable memory. Before I lose you entirely let me break something on down. In 2.0 the memory implementation was called virtual memory, in 2.1 it was called durable memory...well, because words are hard. I kid. Mainly this is because under the hood, virtual memory is more telling from an development perspective of how Ignite was developed but durable memory is more telling of how it functions.
What do I mean by that? Well, Ignite's new memory implementation works a lot like the good ol' virtual memory you know and love. A quick summary is that memory is broken down into logical regions then physical pages. As, the 2.0 release brought us Virtual Memory and off-heap storage which garnered performance gains. However, 2.1 brought us the persistence store and brought us durable memory along for the ride. Meaning, when Ignite's persistence store is invoked, it is always a superset of whatever is on memory making it a further enhancement and providing Apache Ignite as a Distributed Database option. Hence, the shift in terminology.

2.0/2.1 Based Improvements:
On the note of shifts, let's discuss how things have shifted inside the project from pre 2.0 to post. First of all, things are off-heap and not on-heap at all anymore. This is a big deal and you should care. Why? Well, this does some things that matter in terms of performance for Apache Ignite in general.
- Number 1, when things move off-heap we don't have to worry as much about garbage collection and stop the world pauses as when we are subjected to the fresh hell of living on-heap in the JVM.
- Number 2, improvement to the performance of the memory utilization by the Apache Ignite SQL engine was enhanced by approximately 20%!
- Number 3, configurable memory use. You can use the default settings or you can configure it for your specific use case. See more.
- Number 4, Ignite handles memory even more efficiently than before, carrying out defragmentation processes so things don't get nasty.
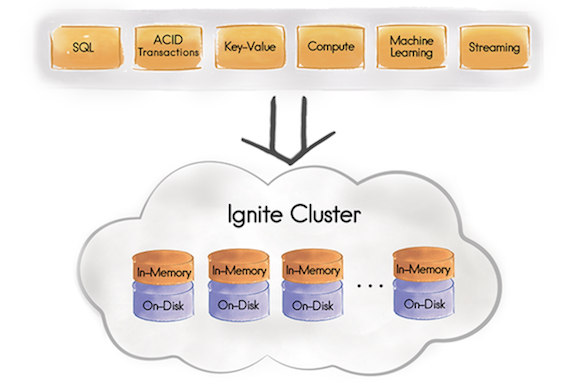
Apache Ignite employs a memory-centric architecture meaning that even though as I mentioned above when using the persistence store, disk is a superset of anything in memory, the cache is always the initial check. This is obviously because RAM is abundantly more performant and for all the other reasons I pointed to in my last blogpost. As you see in the image directly above, Ignite is a distributed database with the possibility to allow for pluggable APIs to access it for whatever your use case might be. It's a pick your poison kind of a cache and store solution. More than this though and what really gives it it's edge, is that Ignite can handle distributed transactions and perform many SQL operations as a distributed database. For more clarity on what Ignite is and isn't check out this FAQ.
- Previously to 2.1 you would have to fit all your data in RAM to perform SQL queries against it. This is no longer the case with Ignite 2.1. This makes the persistence store an ideal solution for hot/cold data use cases.
- Lighting fast cluster restarts - You need to keep under a minute SLA? We got you.

Now that we've discussed all there is to know about the new 2.0 and 2.1, we are ready to build on to the foundation. The Data Grid provides key-value APIs and it can also be used altogether with the persistent store. You can also bring your own system of record to the table if you like, by using JDBC/ODBC connectors. There's a lot more functionality possible but we are going to start with the very basic use case which is using Ignite as a Data Grid.
Conceptually Mastering the Data Grid
The Data Grid just defines how the data is stored - key-value pairs. "Grid" as a term is used heavily within the context of the Ignite project because it refers back to "Grid Computing" - the utilization of a shared pool of computing resources to accomplish given tasks. This terminology is heavily used in in-memory computing because here, we cache data in a shared pool of clustered nodes off your production system with the underlying data stored according to certain policies you can configure based on your use case. The data grid is really just a series of "tables" or "caches" (these two terms are synonymous in Ignite-land) that are stored as key-value pairs. When we want to utilize additionally functionalities like compute tasks or perform SQL queries, we will access this data grid. You can think of all the various functionalities within Ignite as APIs you will use, it's a much better way of becoming mentally aligned with the best way to work with the project. Ignite is extremely flexible but it requires you approach it programmatically to achieve optimal results.
Setting up the Data Grid I.E. Alright Enough Talk More Code
Now that from my last blog post we're either convinced memory is the new disk, or you're at least still reading so we are getting somewhere...let's just try using Ignite by setting up the cache with the WebConsole. You can see how easy it is to spring (pun intended) up a cluster following along with the steps I've provided here and the GitHub link for the code snippets.
What You need
- Oracle JDK 8 - when this was written, otherwise what is referenced in our docs
- Supported OS: Linux, MacOS 10.6 & up, Windows XP & up, Windows Server 2008 & up
- Network: 10G at least
- RAM: 1GB at min for dev environment
- IntelliJ or IDE of Your Choosing
Cluster Setup
Step 1:

Download Ignite or GridGain (production ready version of Ignite) like the rockstar … I’m going to pick GridGain because I'm tempted to demonstrate some of the features that are available in GG only in the future blog posts.
Options: 1. From the GridGain side or 2. From the Apache Ignite walk of life
Step 2:
From whichever option you selected, download it and place it in a logical location for your development environment.
I placed my copy (GridGain Ultimate Edition 8.1.2) in my projects directory for example:
Step 3:
Navigate to bin dir and start up two nodes:
Node 1 started:
Node 2 started:

Step 4:
Load up your POM:

Step 5:
Check out the examples given in the download in your IDE:
For this configuration file, you will provide the referenced xml file to configure your Ignite cluster for your specific use case. As you can see, there are plenty of referenced examples given depending on your specific needs. Not only are these available, but there are also examples on GitHub to reference as well.
In the "example-cache.xml" file given, for instance you could do a simple key value data grid use case in atomic mode - meaning you don't care too much about transactionality. So, it's important to deeply understand your use case before you start writing the code. This is why I spoke to not boiling the ocean in my last post.
Now that we have a taste of how to start up Ignite and look up the examples in the next post we will set up a basic key-value cache and play with it!
Enjoy & code-namaste!
