
Lately there has been lots of noise about "Real Time" Big Data. Lots of companies that associate themselves with this term are generally in analytical space and to them it really means "low-latency" for analytical processing of data which is usually stored in some warehouse, like Hadoop Distributed File System (HDFS). To achieve this they usually create in-memory indexes over HDFS data which allows their customers run fast queries on it.
Although low latencies are very important, they only cover one side of what "Real Time" really means. The part that is usually not covered is how current the analyzed data is, and in case of HDFS it is as current as the last snapshot copied into it. The need for snapshotting comes from the fact that most businesses are still running on traditional RDBMS systems (with NoSql gaining momentum where it fits), and data has to be at some point migrated into HDFS in order to be processed. Such snapshotting is currently part of most Hadoop deployments and it usually happens once or twice a day.
So how can your business run in "Real Time" if most of the decisions are actually made based on yesterday's data? The architecture needs to be augmented to work with LIVE data, the data which has just been changed or created - not the data that is days old. This is where In-Memory Data Grids (a.k.a. Distributed Partitioned Caches) come in.
By putting a Data Grid in front of HDFS we can store recent or more relevant state in memory which allows instant access and fast queries on it. When the data is properly partitioned, you can treat your whole Data Grid as one huge memory space - you can literally cache Terabytes of data in memory. But even in this case, the memory space is still limited and when the data becomes less relevant, or simply old, it should still be offloaded onto RDBMS, HDFS, or any other storage. However, with this architecture, businesses can now do processing of both, current and historic data - and this is very powerful. Now financial companies can quickly react to latest ticks in market data, gaming applications can react to latest player updates, businesses can analyze latest performance of ad campaigns, etc.
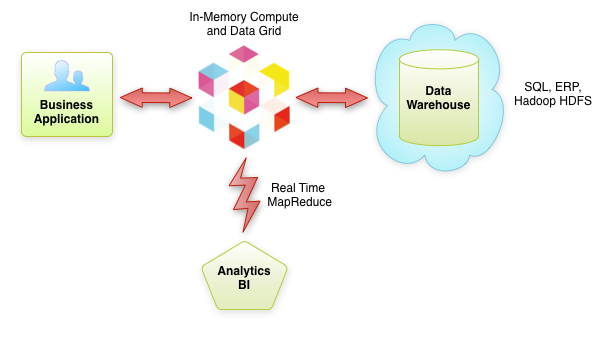
Here are some of the important benefits our customers get when deploying GridGain In-Memory Compute and Data Grid in the above architecture:
Note that in this architecture In-Memory Data and/or Compute Grids really complement warehouse technologies, like HDFS - one is for in-memory processing of current data and another is for processing of historic data.
Although low latencies are very important, they only cover one side of what "Real Time" really means. The part that is usually not covered is how current the analyzed data is, and in case of HDFS it is as current as the last snapshot copied into it. The need for snapshotting comes from the fact that most businesses are still running on traditional RDBMS systems (with NoSql gaining momentum where it fits), and data has to be at some point migrated into HDFS in order to be processed. Such snapshotting is currently part of most Hadoop deployments and it usually happens once or twice a day.
So how can your business run in "Real Time" if most of the decisions are actually made based on yesterday's data? The architecture needs to be augmented to work with LIVE data, the data which has just been changed or created - not the data that is days old. This is where In-Memory Data Grids (a.k.a. Distributed Partitioned Caches) come in.
By putting a Data Grid in front of HDFS we can store recent or more relevant state in memory which allows instant access and fast queries on it. When the data is properly partitioned, you can treat your whole Data Grid as one huge memory space - you can literally cache Terabytes of data in memory. But even in this case, the memory space is still limited and when the data becomes less relevant, or simply old, it should still be offloaded onto RDBMS, HDFS, or any other storage. However, with this architecture, businesses can now do processing of both, current and historic data - and this is very powerful. Now financial companies can quickly react to latest ticks in market data, gaming applications can react to latest player updates, businesses can analyze latest performance of ad campaigns, etc.
Here are some of the important benefits our customers get when deploying GridGain In-Memory Compute and Data Grid in the above architecture:
- Partitioning of data
- Real Time MapReduce
- Integration between Compute and Data Grids and ability to collocate your computations with data (a.k.a. data affinity)
- In-Memory data indexing and ability to run complex SQL queries, including ability to execute "SQL Joins" between different types of data
- Native affinity-aware clients for Java, .NET, C++, Android (with Objective-C client right around the corner)
- Tight integration with various storage systems, including any type of RDBMS, Hadoop HDFS, HBase, etc...
Note that in this architecture In-Memory Data and/or Compute Grids really complement warehouse technologies, like HDFS - one is for in-memory processing of current data and another is for processing of historic data.
Try GridGain for free
Stop guessing and start solving your real-time data challenges: Try GridGain for free to experience the
ultra-low latency, scale, and resilience that powers modern enterprise use cases and AI applications.