

Introduction
In this two-part blog post, we will first explore and understand the major steps that are executed by GridGain’s SQL query processing engine. More importantly, we will share how data is exchanged in the above process and learn about certain limitations that exist within this process.
After learning the basics in part one, we will then explore how to overcome those limitations in part two by implementing an approach that avoids said limitations. The goals of this two-part blog post are as follows:
- Aid your understanding of how core SQL query processing works
- Ensure that you are aware of the core SQL query processing limitations
- Provide an understanding of how query processing is impacted by more data
- Provide an understanding of how query processing is impacted by more groups
- Provide an understanding of how query processing is impacted by more hosts (larger cluster footprint)
- Provide implementation details for how to implement an alternative process that improves upon standard query processing
- Provide an understanding of how the modified process improves over the standard query processing
We are imposing certain assumptions in these two blog posts. Firstly, we will execute a query that uses a grouping statement which is common but also requires network transmission of data to achieve grouping when data affinity is NOT in play. We are specifically not using affinity so that the performance impact of shuffling data among hosts can be understood and subsequently optimized. Moreover, it is not always possible to have affinity on all of your grouping columns anyway, and as such you will no doubt encounter the limitations of data shuffling at some point.
Secondly, we will use a query that is forced to scan all data without the benefit of an index. Once again, you will no doubt encounter this too, and it is important to understand the performance implications of full scan operations.
Background
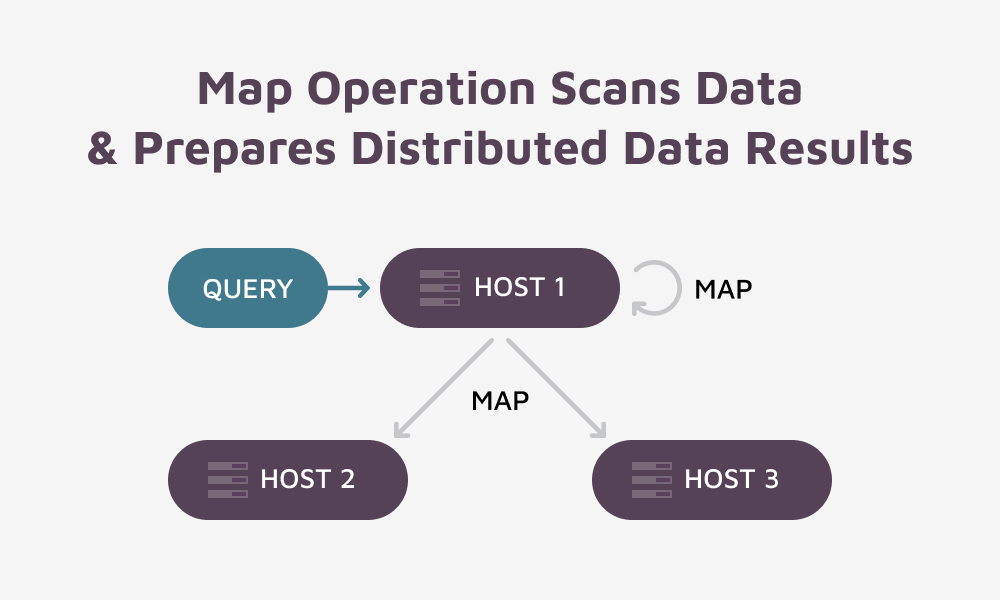
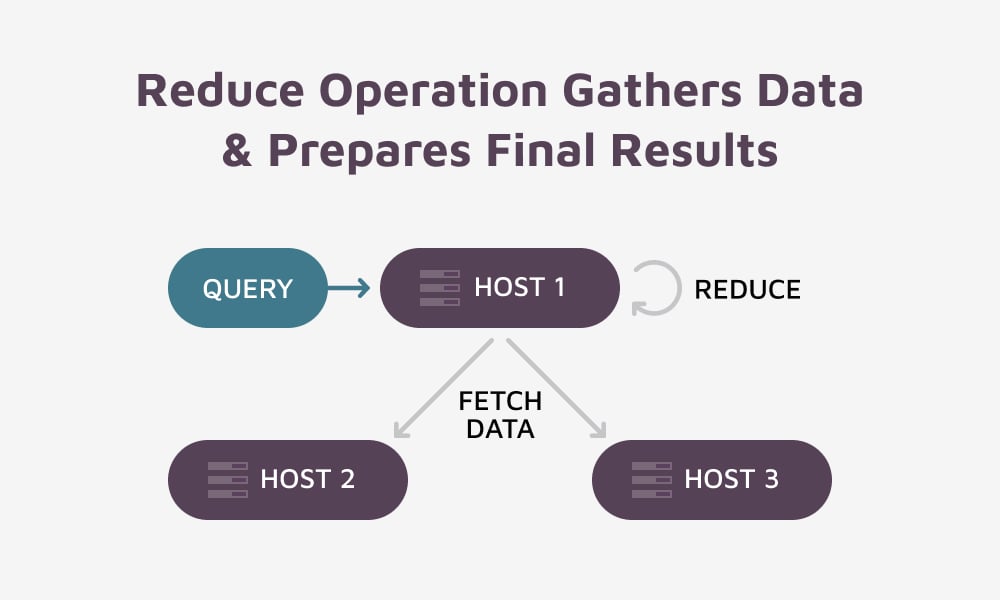
The GridGain platform uses Map / Reduce operations to implement its SQL query processing capabilities. You can see the Map / Reduce operations by executing an explain for your query. At a high level, each query executes the following basic steps:
- Submit the query to 1 of N hosts in a cluster
- The submission host will then parse the query and develop an execution plan
- Phase 1 will involve distributing Map operations to be executed on all hosts
- Phase 2 will involve executing 1 single reduce operation on the same host that received the query.
- Finally, results will be realized from the reduce operation
Table
We will use a simple table that has a primary key, a date column, and two numeric columns that are to be summed over our grouping element, which is a date field. Here’s the create statement for our example table:
CREATE TABLE IF NOT EXISTS CAR_SALES (
vin varchar,
sale_date date,
purchase_cost double,
sale_price double,
PRIMARY KEY (vin)
) WITH
"CACHE_NAME=CAR_SALES,
VALUE_TYPE=CAR_SALES";
Query
Here’s the query we will use to facilitate our understanding of GridGain’s basic query processing:
SELECT sale_date,
SUM(purchase_cost) AS total_expenses,
SUM(sale_price) AS total_income
FROM CAR_SALES
GROUP BY sale_date;
Understanding the Impact of Data Rows
We will presume that our cluster holds three years of data on N number of data nodes. From the above number of data rows, we should expect that each Map operation will transmit ~3 * 365 rows of result data to our reducer operation executing on one single host. If the cluster held 10 years worth of data it would be ~10 * 365 rows of data transmitted from each host to the reducer operation executing on one host.
Understanding the Impact of Cluster Size
If we execute the Map / Reduce operation for our query on a cluster that has three data nodes then hosts will send ~3 * 365 result rows to the reducer operation on one host. As such, our reducer will receive ~3 * 3 *365 (3285) total rows with three hosts contending in the transmit / receive operations. If we have a cluster that has 10 data nodes then our reducer operation will receive ~10 * 3 * 365 (10950) total rows with 10 hosts contending in the transmit / receive operations.
Getting a Mental Picture of Query Processing
The Map Operation:
The Reduce Operation:
Factors Impacting Performance
We can envision from the above that this Map / Reduce operation can be impacted by the following factors:
- The number of columns selected impacts the size of data for each mapper result row
- The number of grouping rows produced by a query (more groups = more map result rows, 3 years of data = 3 * 365, 10 years of data = 10 * 365)
- The number of hosts (data nodes) sending results to the reducer operation (more hosts = more participants sending an approximately equal number of rows for the final answer, 3 hosts, 3 years of data -> 3 * 3 * 365, 10 hosts, 3 years of data -> 10 * 3 * 365)
- The reducer operation executes on one host (the host might be data limited from lots of grouping results or connection limited from lots of hosts sending results, or both)
Summary
We have provided a verbal and graphic understanding of how a query is executed on the GridGain platform. We presented a distributed data problem that does NOT have the benefits of data affinity. We presented a distributed data problem that can produce many intermediate grouping result rows.
We shared how a reducer operation executes on a single host (single process) and how that process can be impacted by the number of selected columns. We shared how the reducer operation can be impacted by many grouping results. And finally, we shared how the reducer operation can be impacted by many hosts all sending results to a single reducer operation on one single host.
With a firm understanding of basic query processing in mind, we will explore how this process can be optimized and achieve improved performance in our upcoming blog post on Optimizing Distributed Query Processing.
Stay tuned for that blog – and a link to the sample code that you can access!