
When your Apache Ignite cluster is using excessive memory, Ignite provides various techniques to enable you to handle the massive volumes of data generated by your applications and services. While the common advice is to "throw more resources into the cluster," it is often not practical or feasible to instantly scale out a cluster. Typically, an Ignite cluster with a specific memory capacity is provisioned for an application, and acquiring additional resources can be a constant and challenging task.
In this blog post, we will explore the various architectural techniques that enable you to manage memory in situations where your cluster is running out of memory space, scale the operation of your cluster, and keep your applications running.
Configure Ignite Eviction Policies to Avoid Out-of-Memory Issues
The first technique we will explore is data eviction, a well-established method utilized to safeguard your clusters against excessive memory usage. By actively monitoring the memory space being utilized, data eviction effectively prevents out-of-memory problems. It achieves this by removing surplus data whenever the amount of memory being used surpasses a predetermined maximum threshold.
Ignite offers support for various eviction policies that come into play when the maximum size of a data region is reached. These policies are responsible for removing the least recently used pages from memory.
To enable the DataPageEvictionMode.RANDOM_2_LRU policy for a custom data region, you can use the following code snippet:
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
regionCfg.setName("20GB_Region");
// 500 MB initial region size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);
// 20 GB maximum region size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);
// Enabling RANDOM_2_LRU eviction for this region.
regionCfg.setPageEvictionMode(DataPageEvictionMode.RANDOM_2_LRU);
Eviction policies in Apache Ignite can be configured for both pure in-memory clusters and clusters that store records in external databases like Oracle or MySQL. However, clusters with Ignite native persistence do not follow the eviction policy settings. Instead, they use a page-replacement algorithm to manage memory usage.
If you use Ignite eviction policies to prevent out-of-memory incidents, Ignite can automatically bring back evicted records under two conditions: a) The records have an on-disk copy in an external database connected through the CacheStore interface. b) An application attempts to read the records using Ignite key-value APIs.
In all other cases, it is your responsibility to reload the evicted data into Ignite when needed.
Consider Swapping to Avoid Memory Overflow
Swapping is another protection technique available in operating systems for excessive memory use in clusters. When the operating system identifies excessive memory usage, it can utilize swapping to transfer data in and out of memory, preventing application and system failures.
Ignite offers the capability to enable swapping for data regions. To activate swapping, use the code snippet below, which demonstrates how to enable swapping through the DataRegionConfiguration.setSwapPath setting:
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
regionCfg.setName("500MB_Region");
regionCfg.setInitialSize(100L * 1024 * 1024);
regionCfg.setMaxSize(5L * 1024 * 1024 * 1024);
// Enabling swapping.
regionCfg.setSwapPath("/path/to/some/directory");
// Applying the data region configuration.
storageCfg.setDataRegionConfigurations(regionCfg);
The Ignite storage engine operates by storing data in memory-mapped files within a specific environment. The responsibility of moving the file content between memory and disk is entrusted to the operating system, which does so based on the current memory usage.
Nevertheless, it is important to consider a couple of drawbacks before relying on swapping. Firstly, swapping does not provide any guarantee of data durability. If a node fails, any records that were swapped will be lost when the process terminates. Secondly, even if a node process has sufficient memory capacity to retain application records, the performance of a cluster with swapping (but no swapped data stored on disk) cannot be expected to match the performance of a similar cluster without swapping.
If you choose to use swapping as a technique to protect against memory overflow while minimizing the impact on cluster performance, it is necessary to thoroughly review and adjust various operating system settings related to swapping, such as vm.swappinness and vm.extra_free_kbytes.
Use Apache Ignite Native Persistence to Read Disk-Only Records and to Prevent Data Loss on Restarts
The Ignite multi-tier storage feature allows you to configure it to use Ignite native persistence as a disk tier. With native persistence, all data records and indexes are stored on disk, giving you the flexibility to choose how much data should be cached in memory. Even if the dataset of an application is too large to fit in memory, the cluster still retains disk-only records that the application can access. Unlike the swapping approach, native persistence ensures that no data is lost during restarts. Once the cluster nodes are connected, they can directly serve all the records from disk. Configuring native persistence is simple. By setting the DataRegionConfiguration.persistenceEnabled property to true, Ignite automatically stores all the records associated with your data region on disk.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration regionCfg = new DataRegionConfiguration();
regionCfg.setName("20GB_Region");
// 500 MB initial region size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);
// 20 GB maximum region size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);
// Enable Ignite Native Persistence for all the data from this data region.
regionCfg.setPersistenceEnabled(true);
If you configure persistence on a per-data region basis, you can specifically enable it for caches and tables that are likely to exceed their capacity. As a general recommendation, enable persistence for all data regions initially, and then decide whether to disable it for specific subsets of data.
With native persistence, Ignite does not impose any API restrictions on clusters. In fact, all Ignite APIs, including SQL and ScanQueries, have the ability to retrieve records from disk if they are not present in memory. This feature eliminates the need for applications to reload evicted records that have been removed from memory due to Ignite's eviction policies.
Using native persistence, Ignite employs page replacement and rotation techniques to prevent excessive memory consumption. While the algorithm automatically removes records from memory, it preserves the disk copy, which can be retrieved back into the memory tier whenever required by applications.
Use Bigger Heap and Pauseless Garbage Collector to Eliminate Issues With Java Heap
Ignite stores all application records and indexes in its off-heap memory, commonly referred to as "page memory" due to its organization and management. The memory space is divided into fixed-size pages, similar to modern operating systems, where the application records are stored. To prevent running out of off-heap memory, eviction policies and native persistence techniques are employed.
In addition, like any Java middleware, Ignite temporarily uses the Java heap as storage for objects and records requested by applications. For example, when data is retrieved through key-value or SQL calls, a copy of the requested off-heap records is kept in the Java heap. Once the on-heap-based result set is transmitted to the application, it is then garbage collected.
If the Java heap space starts to run out, it is unlikely that the JVM will generate out-of-memory exceptions that cause cluster nodes to go down. Instead, you may experience long garbage collection pauses on the cluster nodes, known as "stop-the-world" pauses. These pauses can significantly impact the cluster's performance and lead to unresponsive nodes.
A general solution to this issue is to allocate a sufficiently large Java heap that can handle application requests under production load. The appropriate heap size depends on the specific use case and can range from as small as 3GB to as large as 30GB per cluster node.
Applications with high throughput and low latency typically require larger Java heaps. In such cases, consider using pauseless Java garbage collectors such as C4 of Azul Zing JVM. These collectors offer reliable and consistent performance regardless of the heap size.
Use Memory Quotas for SQL to Make Java Heap Usage Predictable
SQL queries in Apache Ignite are resource-intensive operations, particularly in terms of Java heap usage. These queries involve scanning through numerous table records, grouping and sorting hundreds of records in memory, and joining data from multiple tables. The query-execution process can be visualized using the diagram below, with the "computing" phase being the most Java heap-intensive:
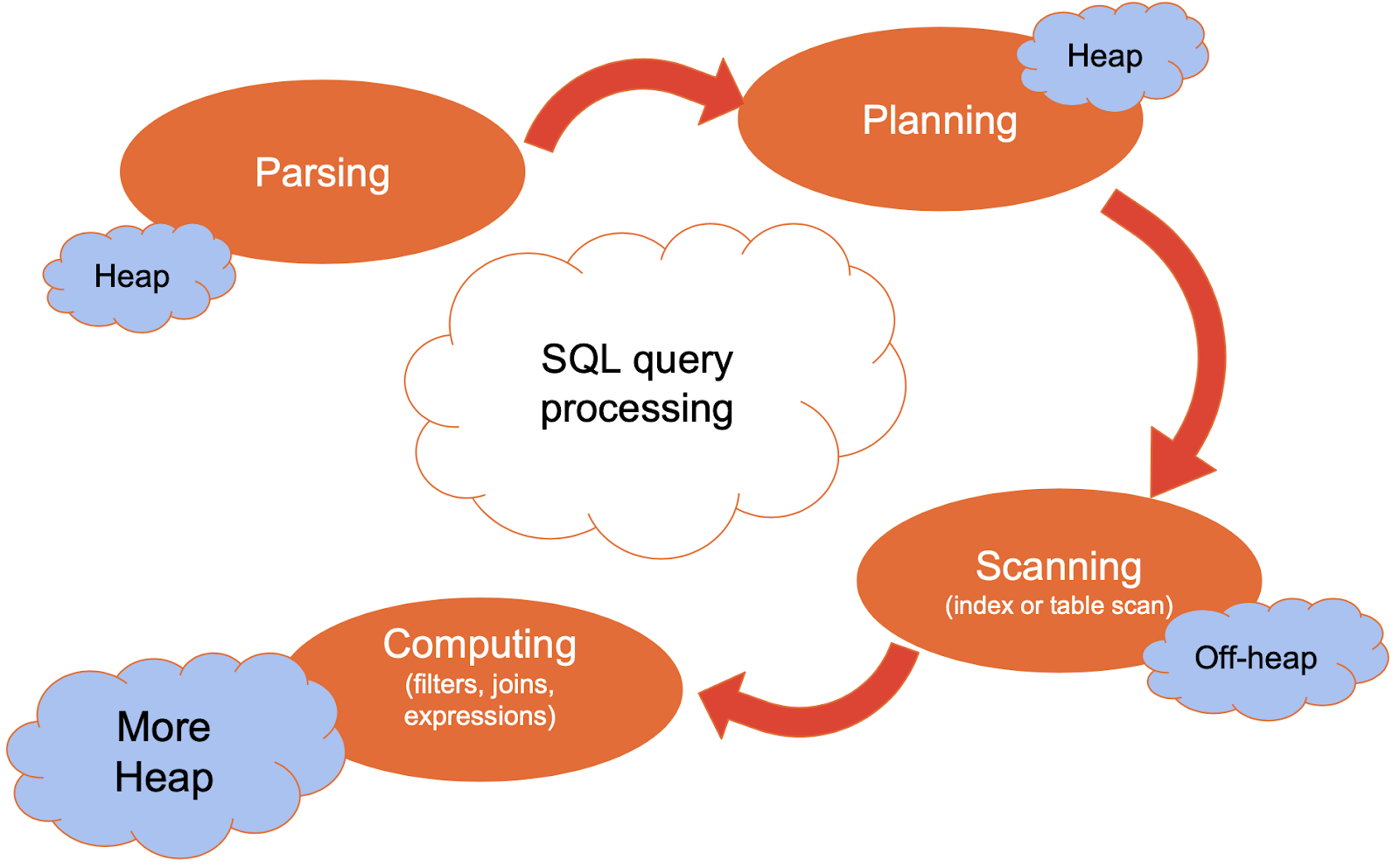
It is common for the final Java heap size in Apache Ignite deployments to be influenced by the requirements of SQL-based operations. As mentioned in the previous section, one approach to address this is to allocate a larger Java heap. However, another option is to utilize memory quotas to effectively manage Java heap space utilization.
Memory quotas in Apache Ignite are specifically designed for SQL operations and are available in GridGain. To set quotas per cluster node, you can refer to the following configuration example:
// Creating Ignite configuration.
IgniteConfiguration cfg = new IgniteConfiguration();
// Defining SQL configuration.
SqlConfiguration sqlCfg = new SqlConfiguration();
// Setting the global quota per cluster node.
// All the running SQL queries combined cannot use more memory as set here.
sqlCfg.setSqlGlobalMemoryQuota("500M");
// Setting per query quota per cluster node.
// A single running SQL query cannot use more memory as set below.
sqlCfg.setSqlQueryMemoryQuota("40MB");
// If any of the quotas is exceeded, Ignite will start offloading result sets to disk.
sqlCfg.setSqlOffloadingEnabled(true);
cfg.setSqlConfiguration(sqlCfg);
To ensure efficient performance, the current configuration limits a single Ignite cluster node to use only 500MB of allocated Java heap space for running SQL queries. Additionally, the SqlConfiguration.setSqlQueryMemoryQuota feature prevents any individual SQL query from consuming more than 40MB of the heap. If these quotas are exceeded, Ignite will start offloading query result sets to the disk tier, similar to how a relational database handles it when the SqlConfiguration.setSqlOffloadingEnabled parameter is disabled. However, if offloading to disk is also disabled, queries that exceed the quotas will be terminated and an exception will be reported.
Therefore, it is recommended to enable the quotas along with the offloading-to-disk feature, especially when the application needs to perform sorting (SORT BY) or grouping (DISTINCT, GROUP BY) operations on the data, or when running complex queries with sub-selects and joins.
Conclusion
Apache Ignite offers various preventive techniques to address when a cluster runs out of memory space. However, it is important to consider the implications of these techniques. Once triggered, they can impact the performance of the application. For instance, the cluster may start relying more heavily on disk operations such as page replacement for native persistence and offloading SQL result sets to disk.
Additionally, certain records may become unavailable as they are deleted from the cluster due to eviction policies. To assess the effectiveness of these techniques, it is recommended to experiment with scenarios where the cluster runs out of off-heap space and scenarios where it runs out of Java-heap space. The results of these experiments will provide insights into the tuning of native persistence and the ability of the application to reload records that have been removed by Ignite eviction policies.
This updated post was originally written by Denis Magda.