

Recently, I've started seeing the names GridGain and Apache® Ignite™ popping up on the Internet more and more frequently. However, judging from some of the chatter I've seen in social media around these mentions, very few people understand either product -- let alone what each can be used for.
In this post, I will try to explain a little about both -- along with some examples.
Ignite vs GridGain
Short educational note: GridGain released the first version of the same product in 2007. In 2014, GridGain donated most of the code to the Apache Software Foundation, resulting in the birth of the Apache Ignite project. GridGain provides paid support and additional functionality in the form of a plug-in.
It is important to understand: Apache Ignite does not belong to GridGain and is free software under the Apache 2.0 license. So to be clear, Ignite belongs to the Apache Software Foundation.
Ignite.NET
Ignite is written in Java, and also provides an API on .NET and C++ . In this post, it will be a question of the .NET API, in which there are approximately 90% of the functionality of the Java API, plus its own buns (LINQ).
What is it and why?
The simplest and most capacious answer is the database. It is based on the key-value store; roughly speaking, "ConcurrentDictionary" in which the data is located on several machines.
Distributed transactions, SQL with indexes, full-text Lucene search, map-reduce calculations, and much more are supported. But first things first.
How to start?
In one line! This is the easiest database to install and use that I know.
The bad news: we need to have Java Runtime 7+ installed.
The good news: from now on, Java can be forgotten.
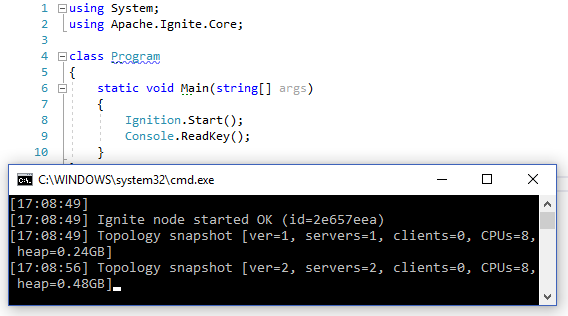
Create a simple Console Application in Visual Studio, install the NuGet Apache.Ignite package, add one line to the Main method Ignition.Start();.
Done! After a couple of seconds, "Topology snapshot [ver = 1, servers = 1" appears in the console. Run the program again and see in both consoles "Topology snapshot [ver = 2, servers = 2". The distributed database is launched spanning across two nodes.
Working with data
Well, we started the database, now it would be nice to create tables and fill them.
The table in Apache Ignite - This cache ICache<K, V>. The work goes directly with the user data types, so we have an ORM in one vial here (although it is possible to work with the data directly, without mapping into objects).
As you can see, the basic work with the cache is no different from all the friends Dictionary<,>. The data is immediately available on all nodes of the cluster.
This part of the functionality can be compared with Redis.
SQL
Data can be added and queried via SQL. To do this, you must explicitly specify which fields of the object are involved in the requests (attribute [QuerySqlField]), and specify the key types and values in the cache configuration:
These two approaches, key-value and SQL, can be mixed to taste. Get or insert one value easier and faster through cache[key], and update a set of values by condition - via SQL.
LINQ
The query from the example above can be rewritten to LINQ (you will need the NuGet package Apache.Ignite.Linq):
This query will be translated into SQL, as you can see by typing linqSelectto ICacheQueryable.
Pay attention to AsCacheQueryable()- it's important! Forgetting this call, we will turn the distributed SQL query into LINQ-To-Objects, which will cause all data to be loaded onto the local node, which we usually do not want to do.
How does it work?
By default, the caches in Ignite work in a Partitioned mode in which the data is evenly distributed among the nodes. The SQL query is sent to each node and is executed, the results are then aggregated on the node that initiated the query. Each node parallels the others in processing only its own part of the data. By adding more nodes to the cluster, we can increase the performance and the amount of stored data.
To provide fault tolerance, you can specify one or more backup copies, that is, the number of nodes that store each data item.
In some cases, it makes sense to have a Replicatedmode where each node stores a complete copy of all the data.
Map-Reduce, Locks, Atomics ...
Suppose we need to translate a huge text, or recognize a large number of images. Such tasks can be easily parallelized between several servers:
Synchronizing various processes between nodes can be done using distributed locks. The functional is analogous to lock {}/ Monitor, with the only difference being that it extends to the entire cluster:
Are you familiar with the Interlocked class? Ignite provides a similar nonblocking functional -- only operations are atomic within the entire cluster.
This group of features can be compared with Akka.
Conclusion
I work for GridGain, but I'm writing this post on behalf of being a contributor Apache Ignite. I think the product deserves attention. Especially in the .NET world, where the whole theme of Big Data and distributed computing is poorly disclosed. Few such projects normally support .NET, even less is written on it.
Ignite.NET is really easy to try -- it runs even in LINQPad (code examples for LINQPad are included in NuGet!). The ways Ignite can be used are massive. There is integration with ASP.NET ( output cache , session state cache ), with Entity Framework (second level cache). It can be used as a platform for (micro) services. In any project where more than one server is required, Ignite can somehow make life easier.
Yes, there are other projects that have this or that feature of Ignite, but there is no other project where all this is integrated and integrated into one product.
References
- website ignite.apache.org
- GitHub Code github.com/apache/ignite
- .NET github.com/apache/ignite/tree/master/modules/platforms/dotnet code
- NuGet nuget.org/packages/Apache.Ignite
- Sample code on GitHub
P.S. We at Apache Ignite are always glad to new contributors! There are many interesting tasks on .NET, C ++, Java. Participating is easier than it seems! Questions, let me know in the comments section.