
This post takes a closer look at Apache Ignite’s C++ API (called Ignite C++). It's intended primarily for C/C++ programmers.
Ignite and Ignite С++
- Ignite C++ is built on top of Ignite
- Ignite С++ starts the JVM in the same process and communicates with it via JNI
- .NET, C++ and Java nodes can join the same cluster, use the same caches, and interoperate using common binary protocol
- Java compute jobs can execute on any node (Java, .NET, C++)
Getting started
Because Apache® Ignite™ is a distributed platform, we must start at least one node to begin. It’s very simple to do with the ignite::Ignition class:

Congratulations! You just started your first Apache Ignite node in C++ with default settings. "Ignite class" is the main entry point to access the entire cluster API.
Data manipulation
The main Ignite C++ component that exposes the API for data manipulations is the cache ignite::cache::Cache<K,V>. The cache contains the basic set of data manipulation methods. As Cache essentially acts as an interface for a distributed hash table, basically you interact with it as with simple containers — map or unordered_map.

Apache Ignite is written mainly in Java and many of its features were used to implement Ignite components. For example, to serialize/deserialize objects for storage on disk and transfer objects via a network.
In Ignite C++, this feature has been implemented via template specialization ignite::binary::BinaryType<T>. This approach is used in thick as well in thin clients. For the Person class presented above, such specialization may look like this:

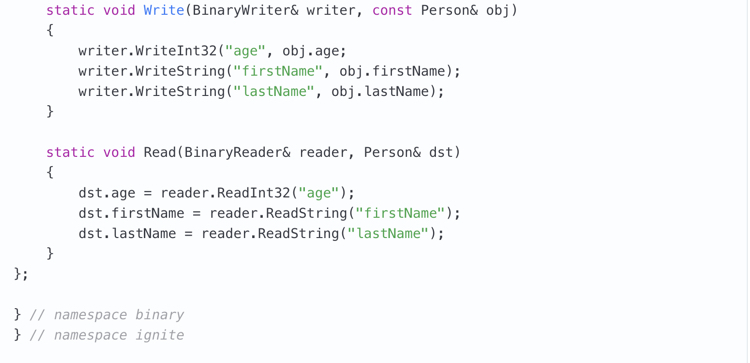
As you can see, apart from serialization/deserialization methods BinaryType<Person>::Write, BinaryType<Person>::Read, there are some more methods in place. We need them to explain to the platform, how to handle the custom C++ types in other languages, particularly in Java. Let’s explore each method in details:
- GetTypeName() — returns the type name. The type name must be the same on all platforms, where this type is used. If you use the type only in Ignite C++, you can name it as you wish.
- GetTypeId() — returns the unique cross-platform type ID. To behave correctly on any platform, the type must be equally evaluated everywhere. The GetBinaryStringHashCode(TypeName) method returns the same Type ID, as in any other platform by default, so such implementation of this method allows correctly use this type from other platforms as well.
- GetFieldId() — returns the unique ID for the type name. Again, you should use the GetBinaryStringHashCode(); method to enable correct cross-platform functionality.
- IsNull() — checks, if the class instance is NULL. This method is used for correct serialization of NULL-values. Not very useful with the class instances as such, but may be very handy, if the user wants to work with smart pointers and define some specialization, e.g. for BinaryType< std::unique_ptr<Person> >.
GetNull() — called if you try to deserizlize the NULL value. Any said about IsNull, also holds true for GetNull().
SQL
Drawing analogy to traditional databases, we can consider the cache as a database schema with a class name, and this schema contains a single table – with the type name. Apart from cache-schemas there is also a common schema named PUBLIC, where one can create/delete any number of tables using standard DDL instructions, such as CREATE TABLE, DROP TABLE, etc. Typically, we connect to the PUBLIC scheme via ODBC/JDBC if we want to use Ignite only as a distributed database.
Ignite supports full-fledged SQL queries, including DML and DDL. SQL-transactions aren't supported yet, but the community now is actively developing the MVCC implementation, which allows to add transactions support. As far as I know, main changes were recently merged into master.
To handle cache data via SQL you must explicitly specify in the cache configuration, which object fields will be used in SQL-queries. The configuration is described in the XML-file, after that the path to the configuration file will be specified at node start:

The config will be parsed by Java-engine, so the base types must be specified for Java too. Having created the configuration file, you need start the node, get a cache instance – and go on with SQL:

You can equivalently use insert, update, create table and other queries. Obviously, cross-cache queries are also supported. Though, in such situations you must give the cache name in the query in quotes, as a scheme name. For example, instead of...

... you should write

Apache Ignite is definitely packed with features and it's simply impossible to cover them all in a single post. The C++ API is still being vigorously developed today, so stay tuned for more updates.
P.S. I have been an Apache Ignite committer since 2017, actively developing C++ API for this product. If you are fluent in C++, Java or .NET and wish to contribute to an open source product with an active and friendly community, we always find a few challenging tasks for you.