
Apache Ignite's new native persistence (released in late July with version 2.1) means that the open-source platform is much more than an in-memory data grid: It's a full-fledged distributed, scalable HTAP database with the ability to reliably store raw data that supports SQL, and processes information in real time.
Apache Ignite Persistence
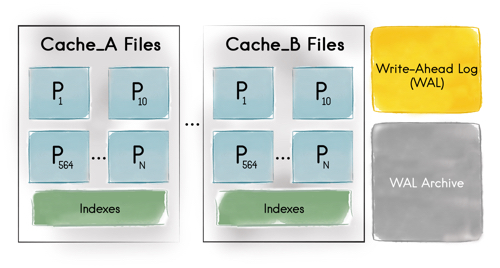
Ignite Persistence is a new component of the platform, which allows you to use not only RAM, but also a disk for data storage. A lot of programming work has gone into the persistence development because of the limitations of classic third-party RDBMSs when using them in conjunction with systems like Apache Ignite. Let's take a closer look.
1. RDBMS is a bottleneck for write-intensive applications. With the help of memory calculation and horizontal scaling, you can achieve significantly higher reading rates. But the updates rates will remain a bottleneck because the platform will need to duplicate the write operations in the DBMS -- which almost always scales much worse if scaled at all. And the need for rapid updates can sometimes be higher than the need for rapid reading. For example, one of our customers has only a few dozen read requests per second (very low delay in data retrieval for arbitrary reading), and at the same time tens of thousands of write operations per second that need to be transacted for later access.
2. RDBMS is a single point of failure. Apache Ignite clusters can consist of dozens and hundreds of nodes that reserve each other, ensuring the security of client data and operations. In this case, the DBMS has much more limited backup capabilities. A database failure in this situation will be much more expensive (and stressful) than the failure of one or several cluster nodes.
3. The inability to simultaneously execute SQL on top of the data in Ignite and in the RDBMS. You can perform ANSI SQL 99 queries on the data stored in the memory of the Apache Ignite cluster, but you cannot correctly execute such queries if at least some of the data is inside a third-party DBMS. Cause: Apache Ignite does not control this database and does not know what data is in it and which is not. The pessimistic hypothesis that not all data is in RAM would lead to the need to duplicate each query in the DBMS, which would significantly reduce performance (not to mention the need to integrate with many SQL and NoSQL solutions, each with its own peculiarities and limitations of operation with data that is virtually impossible task!).
4. The need for warming up. If Apache Ignite is deployed on top of the RDBMS, you must first preload the data from the RDBMS into the cluster. This can take an immense amount of time for large volumes of data. Imagine how much it might take to load 4 terabytes of data into the cluster! Apache Ignite can not do this speedy without additional logic written by the user for the same reasons as in the previous paragraph.
The implementation of Ignite own persistence allowed us to organize distributed, horizontally scalable storage, which is limited in size primarily by available physical disk arrays, and which solves the problems described above. Again, let's take a closer look.
1. Ignite persistence is scaled together with the cluster. Each Apache Ignite node now stores its data portion not only in memory, but also on disk. This gives a near-linear scalability in the performance of write operations.
2. Ignite persistence supports the failover mechanisms of Apache Ignite. To efficiently distribute and backup data, you can use the same redundancy factor and colocated processing approaches. The proprietary GridGain module will also allow you to make backup copies of the entire disk space online. They can be used for subsequent disaster recovery (DR), or deployed on a different cluster, including a smaller cluster, for non-real-time analytics that could load the main cluster too.
3. Ignite persistence allows you to span SQL queries over memory and disk. Because Apache Ignite is tightly integrated with its own persistence, the platform has comprehensive information on the location of the data and can perform "through" SQL queries. Due to this, the user gets the opportunity to use Apache Ignite as Data Lake - store a large archive of information that will be on the disk, and if necessary, execute queries based on this information.
4. Ignite persistence allows you to use "lazy run" - load data into memory gradually, as needed. In this case, the cluster can start almost instantly, cold, and as data accesses, they will be gradually cached in RAM. This allows significantly speed up recovery after an accident (DR RTO), reduces risks for business, and also facilitates and reduces the cost of testing and development procedures by saving time on warm-up.
In this case, Ignite persistence provides a higher level of performance than third-party products due to the lack of unnecessary network interaction.
The interaction between memory and disk is based on the technologies implemented in Apache Ignite 2.0. The available storage space is divided into pages, each of which can contain 0 or more objects, or the site of the object (in those cases when the object exceeds the page by volume). The page can be located in RAM with duplication on disk, or only on disk.
By default, the page is created and maintained in memory, but when the available volume is exhausted, the page is pushed to disk. Then when you request data from this page, it will return to the memory.
The indexes are on separate pages, and with well-constructed queries, the search should follow the data in the indexes that are contained in the memory in order to avoid a full scan and a sequential raising of the entire array of information from the disk.
Ignite persistence can be enabled with a single configuration parameter:
or
Upshot