
In a previous post, we shared an Apache® Ignite™ primer for people new to this exciting this open source project. In it, we touched upon Ignite's key features. Today I'll focus on the commonly asked question: Does Ignite have persistent storage or memory-only storage?
The answer? Both. Native persistence in Ignite can be turned on and off. This allows Ignite to store data sets bigger than can fit in the available memory. Essentially, smaller operational data sets can be stored in-memory only, and larger data sets that do not fit in memory can be stored on disk, using memory as a caching layer for better performance.
Apache Ignite Native Persistence
Ignite native persistence is a distributed ACID and SQL-compliant disk store that transparently integrates with Ignite's durable memory. Ignite persistence is optional and can be turned on and off. When turned off Ignite becomes a pure in-memory store.
With the native persistence enabled, Ignite always stores a superset of data on disk, and as much as it can in RAM based on the capacity of the latter. For example, if there are 100 entries and RAM has the capacity to store only 20, then all 100 will be stored on disk and only 20 will be cached in RAM for better performance.
Also, it is worth mentioning that as with a pure in-memory use case, when the persistence is turned on, every individual cluster node persists only a subset of the data, only including partitions for which the node is either primary or backup. Collectively, the whole cluster contains the full data set.
The native persistence has the following characteristics making it different from 3rd party databases that can be used as an alternative persistence layer in Ignite:
- SQL queries over the full data set that spans both, memory and disk. This means that Apache Ignite can be used as a memory-centric distributed SQL database.
- No need to have all the data and indexes in memory. Ignite persistence allows storing a superset of data on disk and only most frequently used subsets in memory.
- Instantaneous cluster restarts. If the whole cluster goes down there is no need to warm up the memory by preloading data from the Ignite Persistence. The cluster becomes fully operational once all the cluster nodes are interconnected with each other.
- Data and indexes are stored in a similar format both in memory and on disk which helps avoid expensive transformations when moving data between memory and disk.
- An ability to create full and incremental cluster snapshots by plugging-in 3rd party solutions.
Usage
To enable the native persistence, pass an instance of DataStorageConfiguration to a cluster node configuration:


When persistence is enabled, data and indexes are stored both in memory and on disk across all the cluster nodes. The diagram below depicts the structure of Ignite persistence at the file system level of an individual cluster node.
Persistence per Data Region and Cache
Ignite allows the enabling of persistence per concrete data region and, thus, per cache. Refer to the data regions configuration section for details.
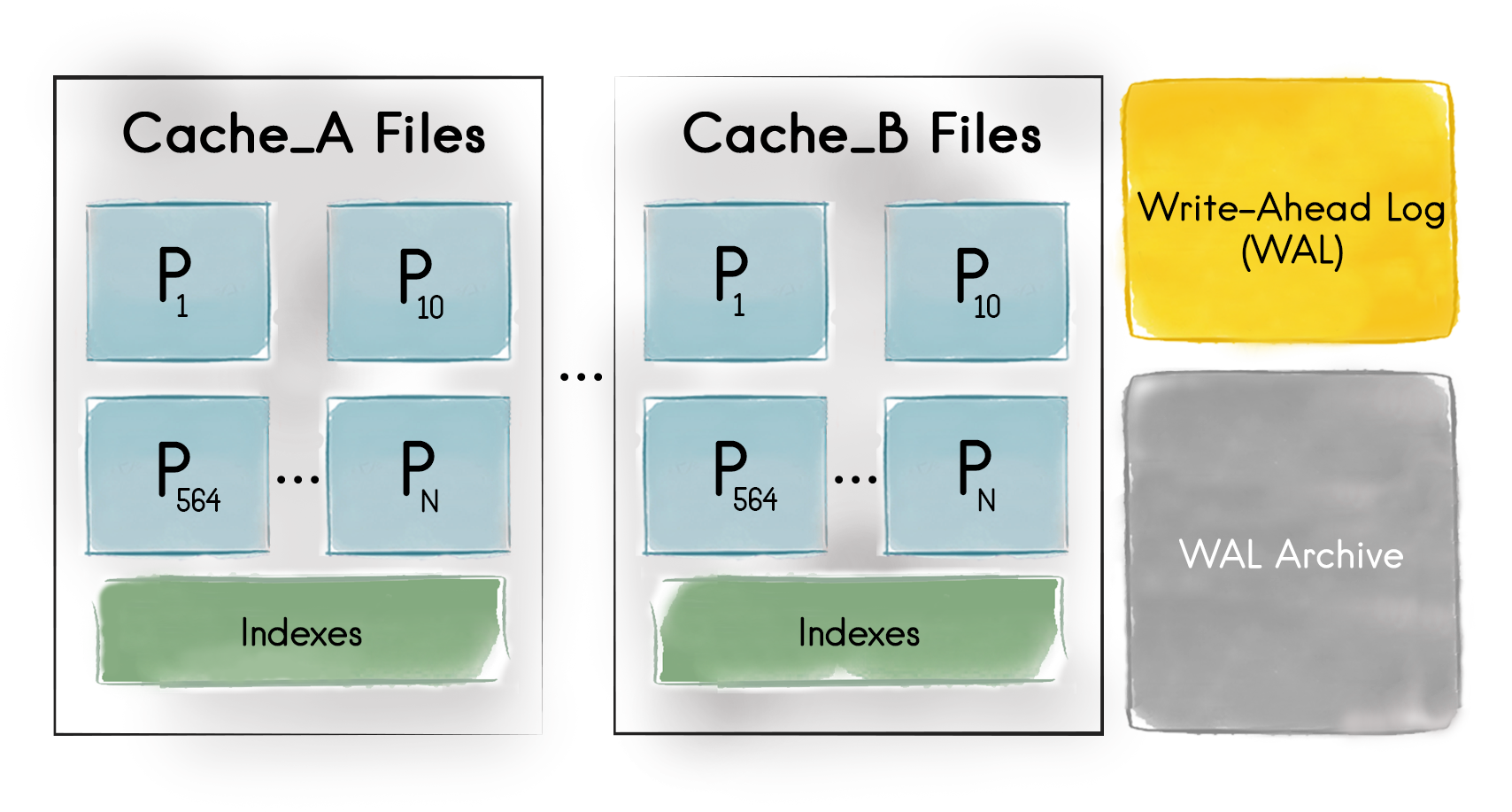
Ignite Native Persistence Structure on the File System
There is a unique directory for every cache deployed on the node. From the picture above, we can see that there are at least two caches (Cache_A and Cache_B) whose data and indexes are maintained by the node.
For every partition that this node is either a primary or backup, the persistence creates a dedicated file on the file system. For instance, the node from the picture above is responsible for partitions 1, 10 and 564. The indexes are stored in one file per cache.
Cache Groups and Partition Files
If Cache_A and Cache_B had belonged to a similar cache group, then there will be only a single directory with partition files shared by both caches. Learn more from cache groups documentation.
Finally, there are files and directories related to the write-ahead log activities that are explained in the Write-Ahead Log and Checkpointing documentation.
Cluster Activation
Note that if Ignite Persistence is used, the cluster is considered inactive by default disallowing any CRUD operations. A user has to manually activate the cluster. See cluster activation page for more information on how to activate the cluster.
By default, the files' hierarchy explained above is maintained under a shared ${IGNITE_HOME}/work/db directory. To change the default location of storage and WAL files, use setStoragePath(...), setWalPath(...) and setWalArchivePath(...) methods of DataStorageConfiguration respectively.
If several cluster nodes are started on a single box/machine, then every node process will have its persistence files under a uniquely defined subdirectory such as ${IGNITE_HOME}/work/db/node{IDX}-{UUID}. Both IDX and UUID parameters are calculated by Ignite automatically upon the nodes' startup as described here. If there are already several node{IDX}-{UUID} subdirectories under the persistence files hierarchy, then they will be assigned among the nodes in first-in-first-out order. To make sure a node gets assigned for a specific subdirectory and, thus, for specific data partitions even after restarts, set IgniteConfiguration.setConsistentId to a unique value cluster-wide. The consistent ID is mapped to UUID from node{IDX}-{UUID} string.
Nodes From Isolated Clusters on a Single Box/Machine
Ignite allows running nodes from isolated clusters on a single machine. In this case, every cluster has to store its persistence files under different paths in the file system. Use setStoragePath(...), setWalPath(...) and setWalArchivePath(...) methods of DataStorageConfiguration to redefine the paths for every individual cluster.
Transactional Guarantees
Ignite native persistence is an ACID-compliant distributed store. Every transactional update that comes to the store is appended to the WAL first. The update is uniquely defined with an ID. This means that a cluster can always be recovered to the latest successfully committed transaction or atomic update in the event of a crash or restart.
SQL Support
Ignite native persistence allows using Apache Ignite as a distributed SQL database.
There is no need to have all the data in memory if you need to run SQL queries across the cluster. Apache Ignite is able to execute them over the data that is both in memory and on disk. Moreover, it's optional to preload data from the persistence into the memory after a cluster restart. You can run SQL queries as soon as the cluster is up and running.
Ignite Persistence Internals
This documentation provides a high-level overview of the Ignite persistence. If you're curious to get more technical details refer to these documents:
Performance Tips
The performance suggestions are listed in durable memory tuning documentation section.
Example
To see how the Ignite native persistence can be used in practice, try this example that is available on GitHub and delivered with every Apache Ignite distribution.