
Apache Ignite is an extremely versatile open-source data platform that supports a wide-range of integrated components. These components include a robust Machine Learning (ML) library that supports popular ML algorithms, such as Linear Regression, k-NN Classification, and K-Means Clustering.
The ML capabilities of Apache Ignite provide a wide-range of benefits, as shown in Figure 1. For example, Ignite can work on the data in place, avoiding costly ETL between different systems. Ignite can also provide distributed computing that includes both data storage and compute. The ML algorithms implemented in Ignite are optimized for distributed computing and can use Ignite's colocated processing to great advantage. Ignite can also act as a sink for streaming data, allowing ML to be applied in real time.
Finally, ML is often an iterative process, and context may change whilst an algorithm is running. Therefore, to avoid loss of work and delay, Ignite supports Partition-Based Datasets which makes it tolerant to node failures.
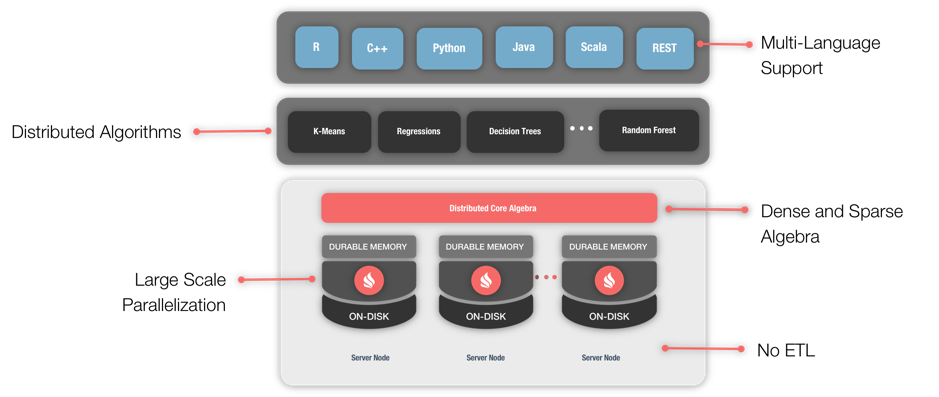
Figure 1. Apache Ignite Machine Learning Grid.
Apache Ignite ships with code examples that demonstrate the use of various ML algorithms on some well-known datasets. These code examples can work standalone making it very easy to get started with the ML library, and the examples can be used as templates for user-specific problems.
With these benefits in mind, let’s undertake some exploratory analysis and write some code for a real-world problem. Specifically, let’s look at how Apache Ignite’s machine learning capabilities could help with Credit Card Fraud Detection.
Background
Today, Credit Card Fraud continues to be a major problem experienced by many financial institutions. Historically, checking financial transactions was often a manual process. However, we can apply ML techniques to identify potentially fraudulent transactions and, therefore be able to develop real-time fraud detection systems that can act much faster and help stop these fraudulent transactions in their tracks.
The dataset
A suitable dataset for Credit Card Fraud Detection is available through Kaggle, provided by the Machine Learning Group at Université Libre de Bruxelles (ULB). The data are anonymized credit card transactions that contain both genuine and fraudulent cases. The transactions occurred over two days and the dataset contains a total of 284,807 transactions of which 492 are fraudulent, representing just 0.172% of the total. This dataset, therefore, presents some challenges for analysis as it is highly unbalanced.
The dataset consists of the following fields:
- Time: the number of seconds elapsed between a transaction and the first transaction in the dataset
- V1 to V28: details not available due to confidentiality reasons
- Amount: the monetary value of the transaction
- Class: the response variable (0 = no fraud, 1 = fraud)
Machine Learning algorithm
According to Andrea Dal Pozzolo who was involved in the collection of the original dataset, Fraud Detection is a classification problem. Also, since investigators may only review a limited number of transactions, the probability that a transaction is fraudulent is more important than the true classification. Therefore, a good algorithm to use for the initial analysis is Logistic Regression. This is because the outcome has only two possible values and we are also interested in the probability.
Data preparation
As previously mentioned, the dataset is highly unbalanced. There are a number of solutions we can use to manage an unbalanced dataset. The initial approach we can take is to under-sample. We will keep all the 492 fraudulent transactions and reduce the majority of non-fraudulent transactions to a smaller number. There are several ways we could perform this dataset reduction:
- Randomly remove majority class examples
- Select every nth row from the majority class examples
For our initial analysis, let’s use the second approach and select every 100th majority class example.
We know that there are columns V1 to V28, but not what these represent. The Amount column varies significantly, between 0 and 25691.16. We can remove the Time column, since it does not provide the actual time of a transaction. There are no missing values in the dataset.
Another decision that we need to make is do we normalize the data? For our initial analysis, we won’t use normalization.
One approach to data preparation for this Credit Card Fraud problem is described by Kevin Jacobs. Simple analysis can often provide good initial insights and help refine the strategy for further data analysis. Using the approach described by Jacobs, we’ll create our training and test data using Scikit-learn. We’ll then load the data into Ignite storage and perform our Logistic Regression using Ignite’s Machine Learning library.
Once our training and test data are ready, we can start coding the application. You can download the code from GitHub if you would like to follow along. We need to do the following:
- Read the training data and test data
- Store the training data and test data in Ignite
- Use the training data to fit the Logistic Regression model
- Apply the model to the test data
- Determine the confusion matrix and the accuracy of the model
Read the training data and test data
We have two CSV files with 30 columns, as follows:
- V1 to V28
- Amount
- Class (0 = no fraud, 1 = fraud)
We can use the following code to read-in values from the CSV files:
private static void loadData(String fileName, IgniteCache<Integer, FraudObservation> cache)
throws FileNotFoundException {
Scanner scanner = new Scanner(new File(fileName));
int cnt = 0;
while (scanner.hasNextLine()) {
String row = scanner.nextLine();
String[] cells = row.split(",");
double[] features = new double[cells.length - 1];
for (int i = 0; i < cells.length - 1; i++)
features[i] = Double.valueOf(cells[i]);
double fraudClass = Double.valueOf(cells[cells.length - 1]);
cache.put(cnt++, new FraudObservation(features, fraudClass));
}
}
The code reads the data line-by-line and splits fields on a line by the CSV field separator. Each field value is then converted to double format and then the data are stored in Ignite.
Store the training data and test data in Ignite
The previous code stores data values in Ignite. To use this code, we need to create the Ignite storage first, as follows:
IgniteCache<Integer, FraudObservation> trainData = getCache(ignite, "FRAUD_TRAIN");
IgniteCache<Integer, FraudObservation> testData = getCache(ignite, "FRAUD_TEST");
loadData("src/main/resources/resources/fraud-train.csv", trainData);
loadData("src/main/resources/resources/fraud-test.csv", testData);
The code for getCache() implemented as follows:
private static IgniteCache<Integer, FraudObservation> getCache(Ignite ignite, String cacheName) {
CacheConfiguration<Integer, FraudObservation> cacheConfiguration = new CacheConfiguration<>();
cacheConfiguration.setName(cacheName);
cacheConfiguration.setAffinity(new RendezvousAffinityFunction(false, 10));
IgniteCache<Integer, FraudObservation> cache = ignite.createCache(cacheConfiguration);
return cache;
}
Use the training data to fit the Logistic Regression model
Now that our data are stored, we can create the trainer, as follows:
LogisticRegressionSGDTrainer<?> trainer = new LogisticRegressionSGDTrainer<>(new UpdatesStrategy<>(
new SimpleGDUpdateCalculator(0.2),
SimpleGDParameterUpdate::sumLocal,
SimpleGDParameterUpdate::avg
), 100000, 10, 100, 123L);
We are using Ignite’s Logistic Regression Trainer with Stochastic Gradient Descent (SGD). The learning rate is set to 0.2 and controls how much the model changes. We have also specified the maximum number of iterations as 100,000 and the seed as 123.
We can now fit the Logistic Regression model to the training data, as follows:
LogisticRegressionModel mdl = trainer.fit(
ignite,
trainData,
(k, v) -> v.getFeatures(), // Feature extractor.
(k, v) -> v.getFraudClass() // Label extractor.
).withRawLabels(true);
Ignite stores data in a Key-Value (K-V) format, so the above code uses the value part. The target value is the fraud class and the features are in the other columns.
Apply the model to the test data
We are now ready to check the test data against the trained Logistic Regression model. The following code will do this for us:
int amountOfErrors = 0;
int totalAmount = 0;
int[][] confusionMtx = {{0, 0}, {0, 0}};
try (QueryCursor<Cache.Entry<Integer, FraudObservation>> cursor = testData.query(new ScanQuery<>())) {
for (Cache.Entry<Integer, FraudObservation> testEntry : cursor) {
FraudObservation observation = testEntry.getValue();
double groundTruth = observation.getFraudClass();
double prediction = mdl.apply(new DenseLocalOnHeapVector(observation.getFeatures()));
totalAmount++;
if ((int)groundTruth != (int)prediction)
amountOfErrors++;
int idx1 = (int)prediction;
int idx2 = (int)groundTruth;
confusionMtx[idx1][idx2]++;
System.out.printf(">>> | %.4f\t | %.0f\t\t\t|\n", prediction, groundTruth);
}
}
Determine the confusion matrix and the accuracy of the model
Now we can check by comparing how the model classifies against the actual fraud values (Ground Truth) using our test data.
Running the code gives us the following summary:
>>> Absolute amount of errors 80 >>> Accuracy 0.9520 >>> Precision 0.9479 >>> Recall 0.9986 >>> Confusion matrix is [[1420, 78], [2, 168]]
For the confusion matrix, we have the following:
| No Fraud | Fraud | |
|---|---|---|
| No Fraud | 1420 | 78 (Type I error) |
| Fraud | 2 (Type II error) | 168 |
A visual inspection of the output also shows that the probabilities align very well with the Ground Truth.
Summary
Our initial results look promising, but there is room for improvement. We made a number of choices and assumptions for our initial analysis. Our next steps would be to go back and evaluate these to determine what changes we can make to tune our classifier. If we plan to use this classifier for a real-time Credit Card Fraud Detection system, we want to ensure that we can catch all the fraudulent transactions and also keep our customers happy by correctly identifying non-fraudulent transactions.
Once we have a good classifier, we can use it directly with transactions arriving in Apache Ignite in real time. Additionally, with Ignite’s continuous learning capabilities, we can refine and tune our classifier further with new data, as the data arrive.
Finally, using Ignite as the basis for a real-time Fraud Detection system enables us to obtain many advantages, such as the ability to scale ML processing beyond a single node, the storage, processing and compute of massive quantities of data, and zero ETL.
This updated blog post was originally written by Akmal B. Chaudhri, published on December 10, 2022.