
This article on GridGain and the two-phase commit protocol is the first in a series of five posts regarding the GridGain transactions architecture.
GridGain supports a range of different Application Programming Interfaces (APIs). In this multi-part article series, we will take a more detailed look at how GridGain manages transactions in its key-value API and some of the mechanisms and protocols it supports.
Here are the topics we will cover in this series:
- GridGain transactions and the two-phase commit protocol
- Concurrency modes and isolation levels
- Failover and recovery
- Transaction handling at the level of GridGain persistence (WAL, checkpointing, and more)
- Transaction handling at the level of 3rd-party persistence
In this first part, we will begin with a discussion of the two-phase commit protocol and then look at how this works with various types of cluster nodes.
Two-Phase Commit (2PC)
In a distributed system, a transaction may span multiple cluster nodes. Obviously, this poses some challenges when we want to ensure that data are consistent across all the participating nodes. For example, in the event of the loss of a cluster node, the transaction may not have fully committed on the lost node. A widely-used approach to ensuring data consistency in this type of scenario is the two-phase commit protocol.
As the name implies, there are two phases: prepare and commit. Let’s see how this works in more detail.
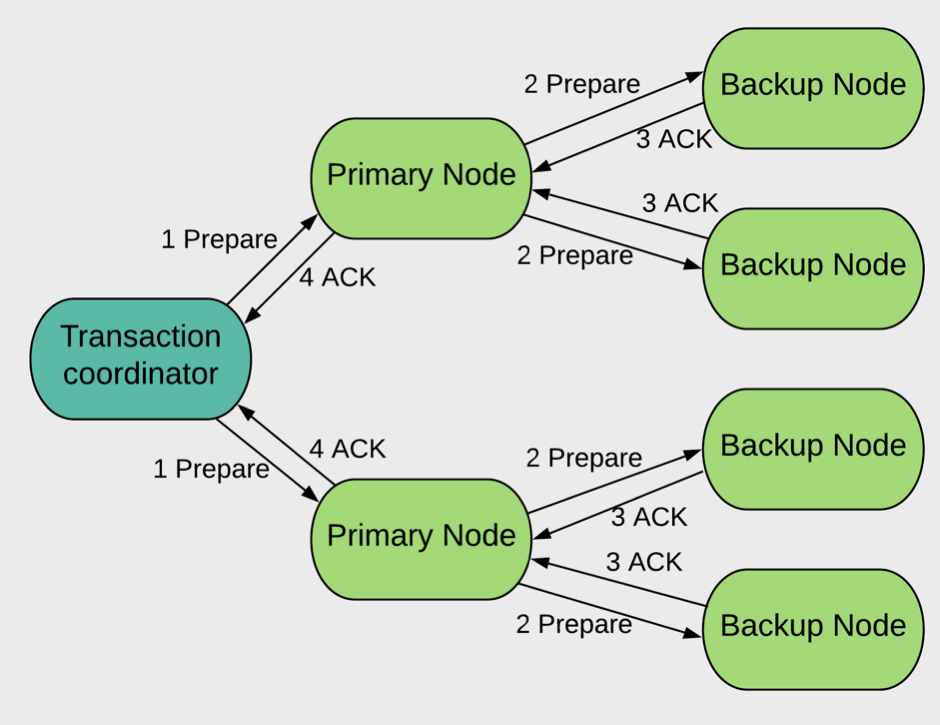
Figure 1. Prepare Phase
Let’s begin with the prepare phase. In Figure 1, we have an example network consisting of a Client (Transaction coordinator), two Primary Nodes and four Backup Nodes.
GridGain uses a Distributed Hash Map to determine how data are distributed (partitioned) in a cluster. Each Primary and Backup Node in a cluster keeps a portion of the data. These nodes maintain an internal Distributed Hash Table of the partitions a node owns. Primary and Backup Nodes just refer to where data reside. The Primary Node is where the main copy of the data resides. In the event that a Primary Node was not available and a Backup Node was created, the data would still be available.
Note, that GridGain doesn’t have pure Primary or Backup Nodes. By default, every node is both a Primary and a Backup; it’s a Primary for one set of partitions and a Backup for another.
In Figure 1, there are also arrows to show various message flows between the different types of nodes:
- The Client sends a prepare message (1 Prepare) to all the Primary Nodes participating in the transaction.
- The Primary Nodes acquire all their locks (depending upon whether the transaction is optimistic or pessimistic) and forward the prepare message (2 Prepare) to all the Backup Nodes.
- Every node confirms to the Client (3 ACK, 4 ACK) that all the locks are acquired and the transaction is ready to commit.
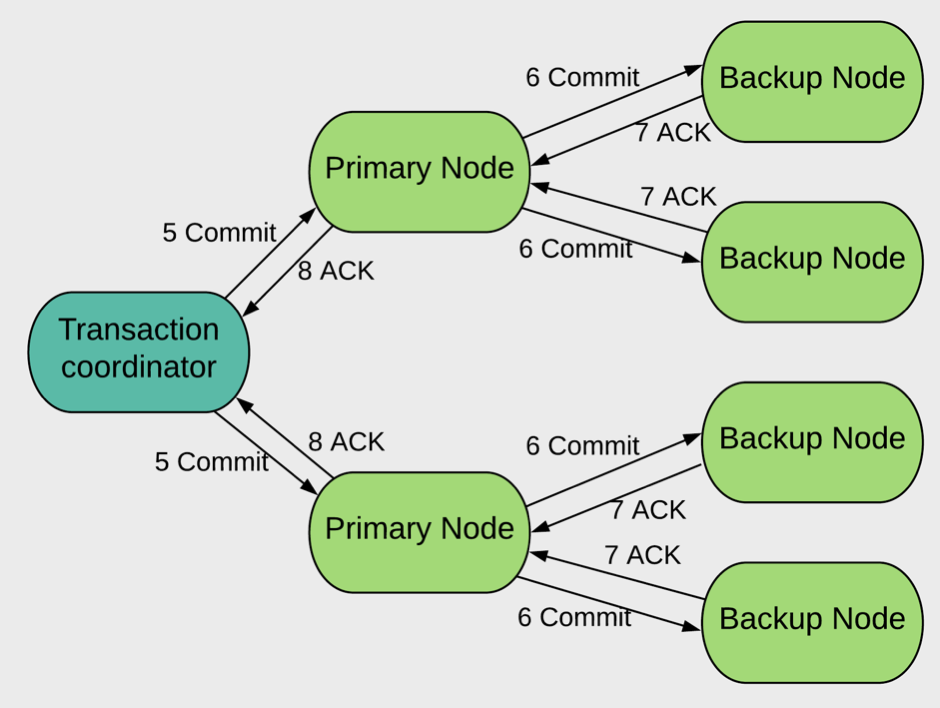
Figure 2. Commit Phase
In the next phase, the commit operation is performed. In Figure 2, we can see a similar message flow to the prepare phase:
- The Client sends a commit message (5 Commit) to all the Primary Nodes participating in the transaction.
- The Primary Nodes commit the transaction and forward the commit message (6 Commit) to all the Backup Nodes and these Backups Nodes commit the transaction.
- Every node confirms to the Client that the transaction has been committed (7 ACK, 8 ACK).
Even with two-phase commit, there are a number of failures that could occur such as loss of a Backup Node, loss of a Primary Node, or loss of the Client. We will look at these scenarios and how GridGain copes with these situations in other articles in this series.
Node Types
The previous discussion mentioned several different types of cluster nodes. The Client (Transaction coordinator) is also often referred to as the Near Node. Other nodes are referred to as Remote Nodes. This is shown in Figure 3.
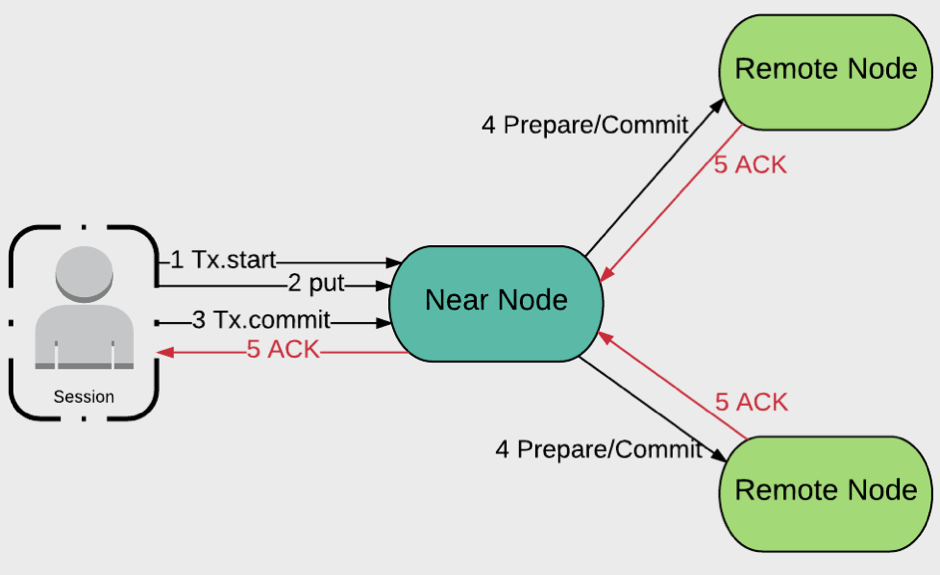
Figure 3. Node Types
Typically, a user application will connect to a cluster through a Client Node. The division of responsibility between the user application and the Client Node is as follows:
- The user application calls the methods:
- txStart()
- cache.put()
- cache.get()
- tx.commit()
- The Client Node manages all other operations:
- Initiating a transaction.
- Tracking the state of a transaction.
- Sending prepare and commit messages.
- Orchestrating the overall transaction process.
Here is a simple Java code example that shows how transactions are performed:
try (Transaction tx = transactions.txStart()) {
Integer hello = cache.get("Hello");
if (hello == 1)
cache.put("Hello", 11);
cache.put("World", 22);
tx.commit();
}
In this example, we can start the txStart() and tx.commit() methods to start and commit the transaction, respectively. Within the body of the try block, the code performs a cache.get() on the “Hello” key. Next, the code checks if the value of the key is 1 and, if so, sets the value to 11 and writes it to the cache using cache.put(). Then, another key-value pair is written to the cache using a cache.put().
Summary
In this first article, we have quickly reviewed the two-phase commit protocol and described how it
works with GridGain. In the next post in this series, we will look at optimistic and pessimistic locking modes and isolation levels.
Be sure to check out the other articles in this “GridGain Transactions Architecture” series:
- GridGain Transactions Architecture: Concurrency Modes and Isolation Levels
- GridGain Transactions Architecture: Failover and Recovery
- GridGain Transactions Architecture: Persistence Transaction Handling
- GridGain Transactions Architecture: Transaction Handling at the Level of 3rd Party Persistence
If you have further questions about Ignite and the two-phase commit protocol, please Contact Us and we can connect you with an Ignite expert.
This post was originally written by Akmal Chaudhri, Technical Evangelist at GridGain.