
In this article, we will focus on how GridGain handles failover and recovery during transaction execution.
In the previous article in this series, we looked at concurrency modes and isolation levels. Here are topics we will cover in
the rest of this series:
- Failover and recovery [this article]
- Transaction handling at the level of GridGain persistence (WAL, checkpointing, and more)
- Transaction handling at the level of 3rd-party persistence
In a distributed cluster consisting of a Transaction Coordinator, Primary Nodes, and Backup Nodes, there are a number of scenarios where we may lose some or all parts of the cluster, as follows, in increasing order of severity:
- Backup Node failure
- Primary Node failure
- Transaction Coordinator failure
Let’s look at each of these in turn and see how GridGain manages failure and recovery in these situations. We’ll begin with Backup Node failure.
Backup Node Failure
Recalling the discussion in the first article in this series, we know that in the two-phase commit protocol, there are the Prepare and Commit phases. In the event that we lose a Backup Node in either of these phases, no action is required by GridGain, since any transactions will still continue to be applied to the remaining Primary and Backup Nodes in the cluster. This is shown in Figure 1.
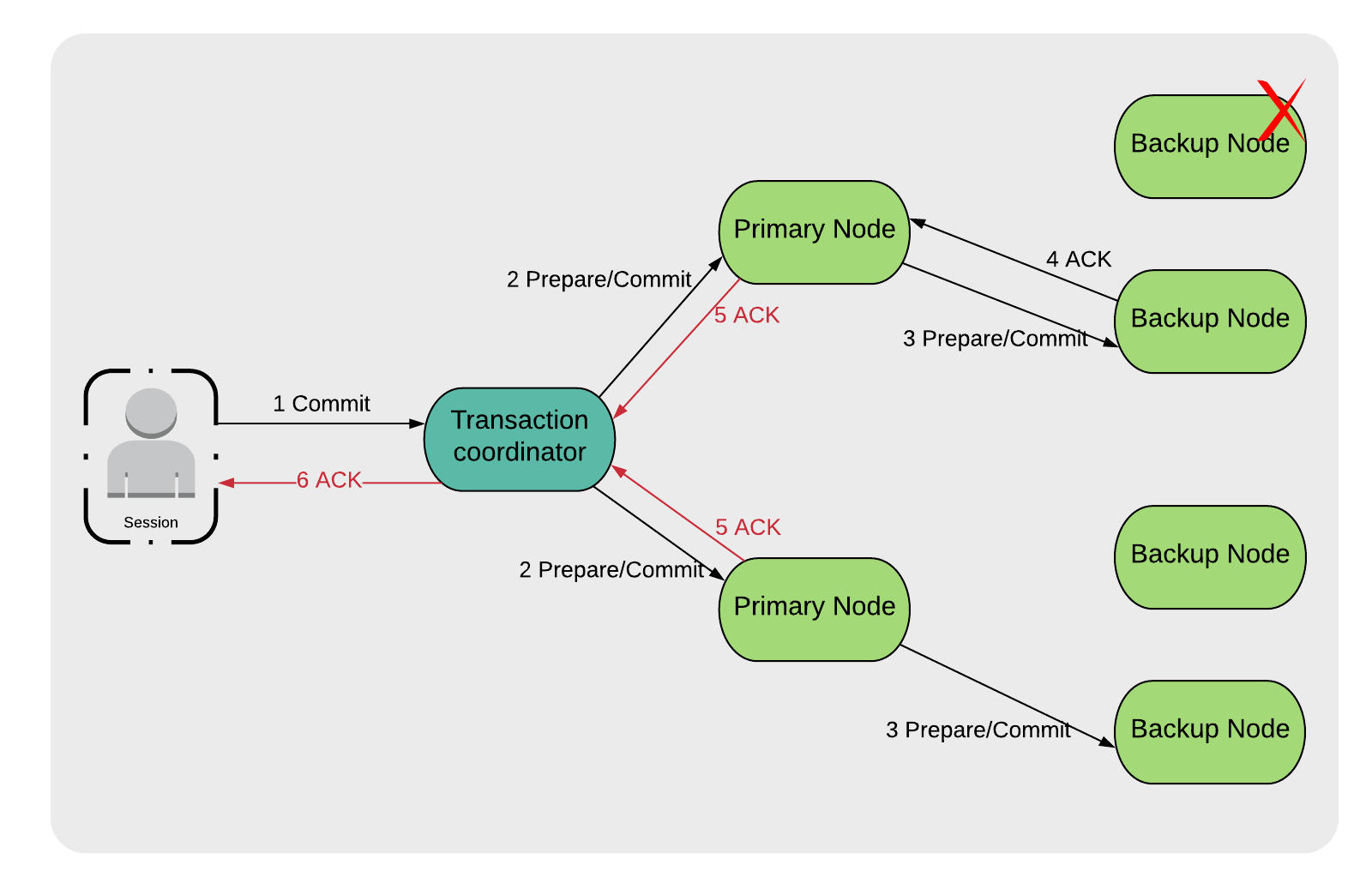
Figure 1. Backup Node Failure
After all the active transactions including this one are completed, GridGain will update its cluster topology version due to the node failure, will elect a new node or nodes that will hold a copy of the data previously stored on the lost Backup Node, and will start rebalancing in the background to meet the desired data replication level.
Next, let's look at how GridGain manages failover and recovery for a Primary Node failure.
Primary Node Failure
A Primary Node failure requires different handling depending upon whether the failure occurs at the Prepare or the Commit phase.
If the failure occurs at the Prepare phase, the Transaction Coordinator will raise an exception as shown in Figure 2 (3 exception). It is then the responsibility of the application to handle this exception and decide what action to take. For example, whether to restart the transaction or to use additional exception handling.
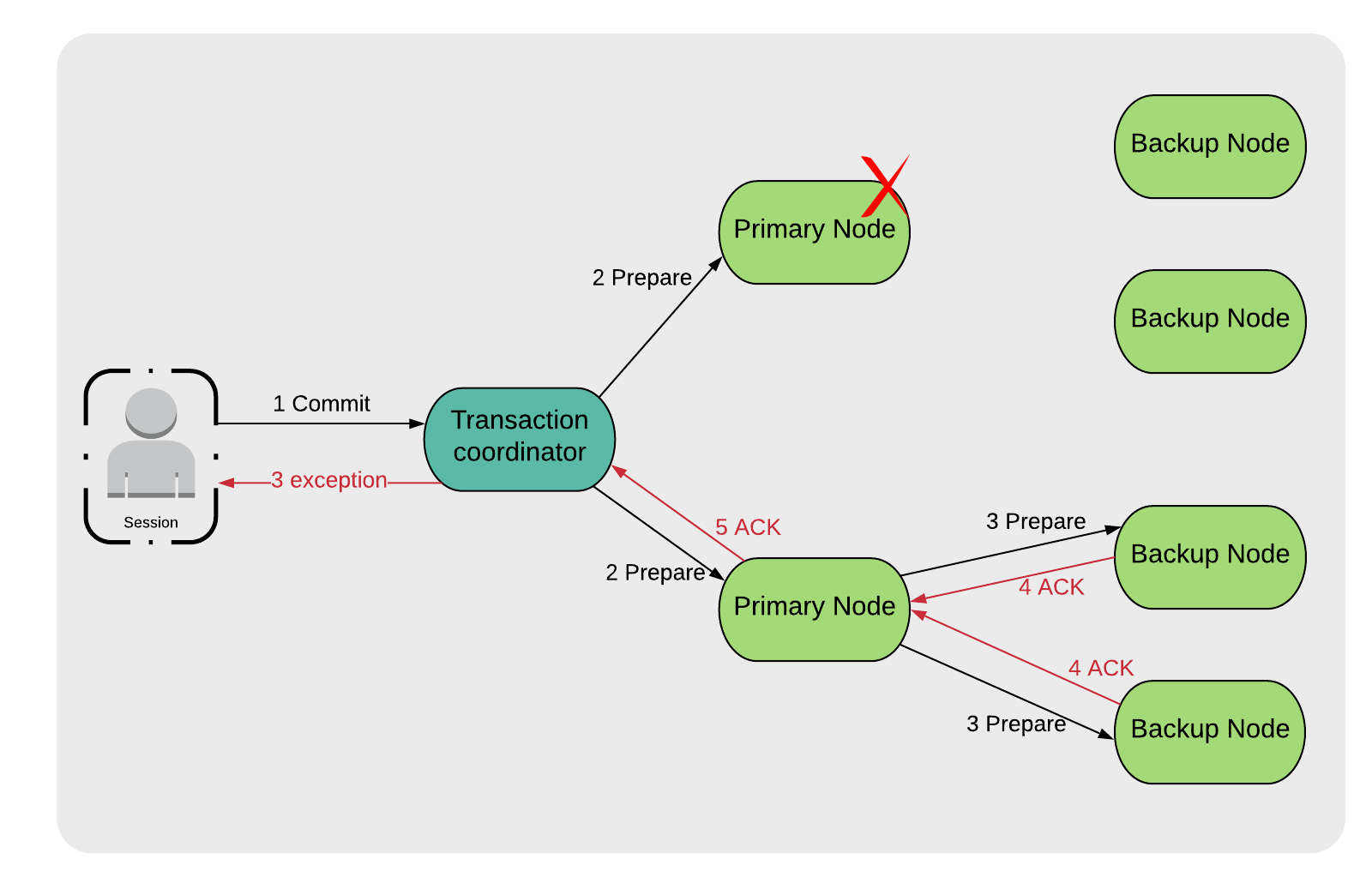
Figure 2. Primary Node Failure on prepare phase
If the failure occurs at the commit phase, as shown in Figure 3, the Transaction coordinator will be waiting for a special message (4 ACK) from the appropriate Backup Nodes.
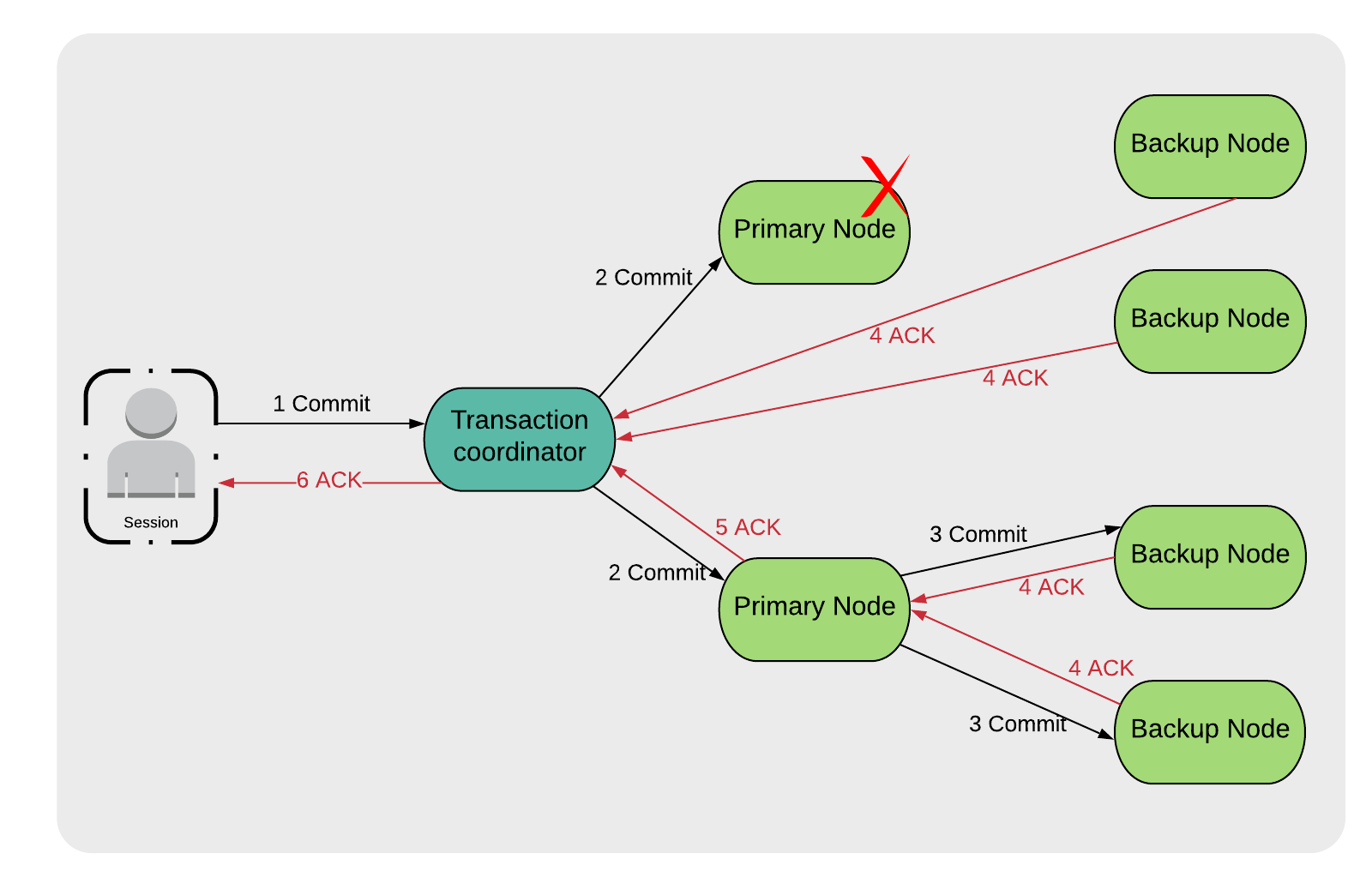
Figure 3. Primary Node Failure on commit phase
When the Backup Nodes detect the failure, they will notify the Transaction Coordinator that they committed the transaction successfully. In this scenario, there is no data loss because the data are backed up and can still be accessed and used by applications.
After the Transaction Coordinator completes the transaction, GridGain will rebalance the cluster due to the loss of the Primary Node. An election will take place to assign a new Primary Node for the partitions that were previously stored on the failed Primary Node.
Next, let's look at how GridGain manages failover and recovery for a Transaction Coordinator failure.
Transaction Coordinator Failure
A worse-case scenario is if we lose the Transaction Coordinator. This is because all Primary and Backup Nodes are only aware of the transaction state locally, and not of the transaction state globally. We may have some cluster nodes that received a commit message and others that did not, as shown in Figure 4.
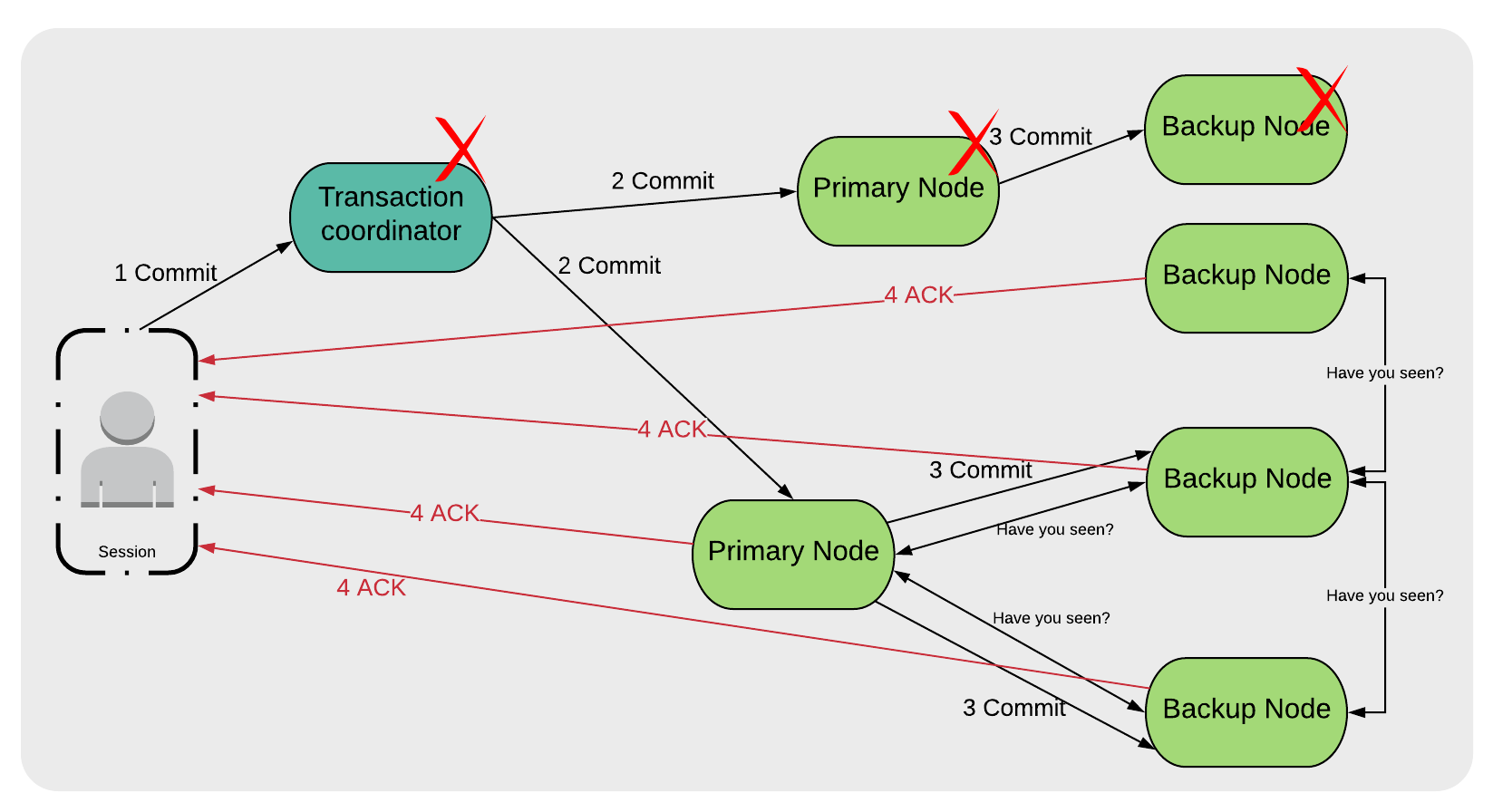
Figure 4. Transaction Coordinator Failure
The failover and recovery solution to this scenario is for the nodes to exchange their local transaction status with each other, as shown in Figure 4. This allows them to see the global transaction status.
In this final scenario, GridGain initiates a Recovery Protocol [1]. This works as follows. All nodes participating in the transaction send messages to all other nodes participating in the transaction asking whether they received the Prepare message. If any node replies that it did not receive the Prepare message, the transaction will be rolled-back. Otherwise, the transaction will be committed.
However, some of the nodes may have already committed the transaction before receiving the Recovery Protocol message. For this type of situation, all nodes keep completed transaction ID information for a period of time. If no ongoing transaction is found with a given ID, the backlog is checked. If the backlog does not contain the transaction, then the transaction was never started. Therefore, the failure occurred before the Prepare phase was completed, so the transaction can be rolled back. The Recovery Protocol also works if any of the Primary or Backup Nodes also crashed with the Transaction Coordinator.
Summary
Various types of cluster failures can occur at a number of different phases. Through these examples, we have seen how GridGain can effectively manage failover and recovery across a range of scenarios.
Be sure to check out the other articles in this “GridGain Transactions Architecture” series:
- GridGain Transactions Architecture: 2-Phase Commit Protocol
- GridGain Transactions Architecture: Concurrency Modes and Isolation Levels
- GridGain Transactions Architecture: Persistence Transaction Handling
- GridGain Transactions Architecture: Transaction Handling at the Level of 3rd Party Persistence
If you have further questions about GridGain failover and recovery, please Contact Us and we can connect you with an GridGain expert.
References
[1] Two-Phase-Commit for Distributed In-Memory Caches
This post was originally written by Akmal Chaudhri, Technical Evangelist at GridGain.