
When PostgreSQL Starts to Struggle
PostgreSQL is fantastic for transactional workloads. It's reliable, well-understood, and has saved my bacon more times than I can count. But somewhere around the 10TB mark, things get weird. You start seeing replica lag that won't quit, vacuuming takes longer and longer, and those cross-table analytical queries that used to run in seconds now take minutes.
The usual fixes like read replicas, materialized views, throwing Redis at everything all buy you time, but they don't really solve the problem. Read replicas still lag when your write traffic spikes. Cache invalidation becomes its own nightmare. And if you go the ETL route to a data warehouse, you're looking at data that's always a few hours stale.
What you really need is a way to run analytics in real-time without turning PostgreSQL into a bottleneck.
Enter the CDC Speed Layer
GridGain is about to publish a white paper where I go deeper into a PostgreSQL + Debezium + Kafka + GridGain 9 pattern which addresses the core problem in a way that makes sense.
The key insight is this: keep PostgreSQL as your source of truth for writes, but stream every change out to a separate analytics layer that's built for reads. No dual writes, no manual syncing, just pure change data capture doing its thing.
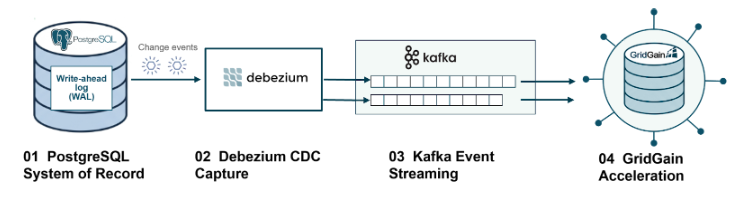
How logical replication changes everything
PostgreSQL's logical replication feature lets you tap into the write-ahead log (WAL) without any application changes. Debezium sits on top of this using the pgoutput plugin, capturing every insert, update, and delete as structured events.
Your application keeps writing to PostgreSQL exactly like it always has. Behind the scenes, Debezium streams everything to Kafka automatically. One source of truth, zero dual-write headaches.
Why Kafka belongs in the middle
Kafka isn't just message passing here; it's your safety net. Each table gets its own topic, partitioned by primary key. This gives you two critical things:
First, ordering guarantees. Updates to the same row always arrive in sequence, which matters a lot when you're reconstructing state downstream.
Second, durability. If your GridGain cluster hiccups or you need to restart the pipeline, Kafka has the full event history. You can replay from any point without manual intervention or data loss.
I've dealt with enough fragile CDC scripts to appreciate what this eliminates. Kafka essentially turns PostgreSQL's WAL into a first-class distributed event log.
GridGain as the query layer
GridGain 9 consumes those Kafka streams and materializes them into distributed, in-memory tables. The trick is colocation. Using COLOCATE BY, you tell GridGain to store related records (like customers and their orders) on the same node.
When you run a join between colocated tables, everything happens in-memory on a single node. No network shuffles, no expensive data movement. Queries that would choke PostgreSQL run in milliseconds.
And because GridGain speaks ANSI SQL, your BI tools and applications don't need to change. They just point at GridGain for analytics while PostgreSQL keeps handling the transactional writes.
How consistent is it, really?
This is probably the first question any engineer asks about CDC pipelines: what about consistency?
The architecture uses at-least-once delivery, which means you might see duplicate events. GridGain handles this through idempotent upserts. Every event includes the primary key, so replays just overwrite the same record. No corruption, no drift.
Kafka's partitioning ensures per-entity ordering.
Debezium's snapshot mechanism ensures you don't miss changes during initialization. And in practice, latency from PostgreSQL commit to queryable data in GridGain is usually single-digit seconds. For operational analytics, that's good enough to be called "real-time."
What this actually fixes
PostgreSQL gets to breathe again
Once analytical queries move to GridGain, PostgreSQL's CPU and I/O usage drops noticeably. We've seen teams retire half their read replicas. Index bloat slows down because you're not maintaining indexes purely for analytical queries. Vacuum runs faster. The primary instance just-works-better.
Recovery becomes boring (in a good way)
The old approach of manual snapshots, custom scripts, crossing your fingers is just gone. If something breaks, you replay from Kafka. Debezium can take an incremental snapshot and rebuild GridGain state deterministically. It's not exciting, but it works.
BI workloads stop interfering with transactions
Before, a long-running report could evict hot data from PostgreSQL's buffer cache, causing latency spikes for your application. Now those queries hit GridGain's in-memory tier instead. The database stays stable, and nobody's pager goes off at 3am because someone ran a dashboard refresh.
The colocation advantage
This deserves its own section because it's not obvious until you see it in action.
When you colocate tables by something like customer_id, GridGain stores all related rows (customers, orders, line items, payments) on the same physical node. A join across those tables becomes a local operation. No network. No serialization overhead. Just pure in-memory processing.
We're talking about queries that used to take 30+ seconds on PostgreSQL running in under a second on commodity hardware. It's the kind of performance improvement that changes what you think is possible.
Cost implications
Scaling PostgreSQL vertically gets expensive fast. Bigger instances, faster storage, more replicas—it adds up.
GridGain lets you scale horizontally instead. You add commodity nodes as your data grows. The cost curve is completely different, and you get better resilience in the bargain.
In real deployments, teams have cut their database infrastructure costs significantly: fewer replicas, less storage overhead, faster recovery from incidents.
When you should (and shouldn't) use this
This pattern makes sense when you're dealing with:
- Complex joins and aggregations that need to run on fresh data
- Dashboards and operational analytics that can't tolerate staleness
- Growing PostgreSQL clusters where read pressure is becoming a problem
But if your use case is mostly single-table lookups on hot data, you might be better off with GridGain's simpler JDBC cache pattern. It gives you millisecond reads without the complexity of Kafka and Debezium.
Final thoughts
The CDC speed layer isn't revolutionary—it's just good engineering. Take proven components (PostgreSQL, Debezium, Kafka, GridGain), wire them together thoughtfully, and you get a system that scales way past what PostgreSQL alone can handle.
You keep PostgreSQL as your transactional foundation. You get real-time analytics without rewriting your application. And you maintain strong consistency guarantees throughout.
For teams hitting the limits of PostgreSQL but not ready to abandon it, this architecture offers a pragmatic way forward. One source of truth, sub-second analytics, and the ability to scale past 10TB without everything catching fire.
That's a pretty good trade-off.