
In this article, we will be discussing transaction handling at the level of GridGain persistence.
In the previous article in this series, we looked at failover and recovery. Here are topics we will cover in the rest of this series:
- Transaction handling at the level of GridGain persistence (WAL, checkpointing, and more)
- Transaction handling at the level of 3rd-party persistence.
Those who use GridGain as an In-Memory Data Grid (IMDG) know that keeping data only in-memory has some serious drawbacks if there is a catastrophic cluster failure. This is an issue that is also faced by other IMDGs and caching technologies. One solution to this problem is to integrate GridGain with third-party persistence stores and provide read-through and write-through semantics, as shown in Figure 1.
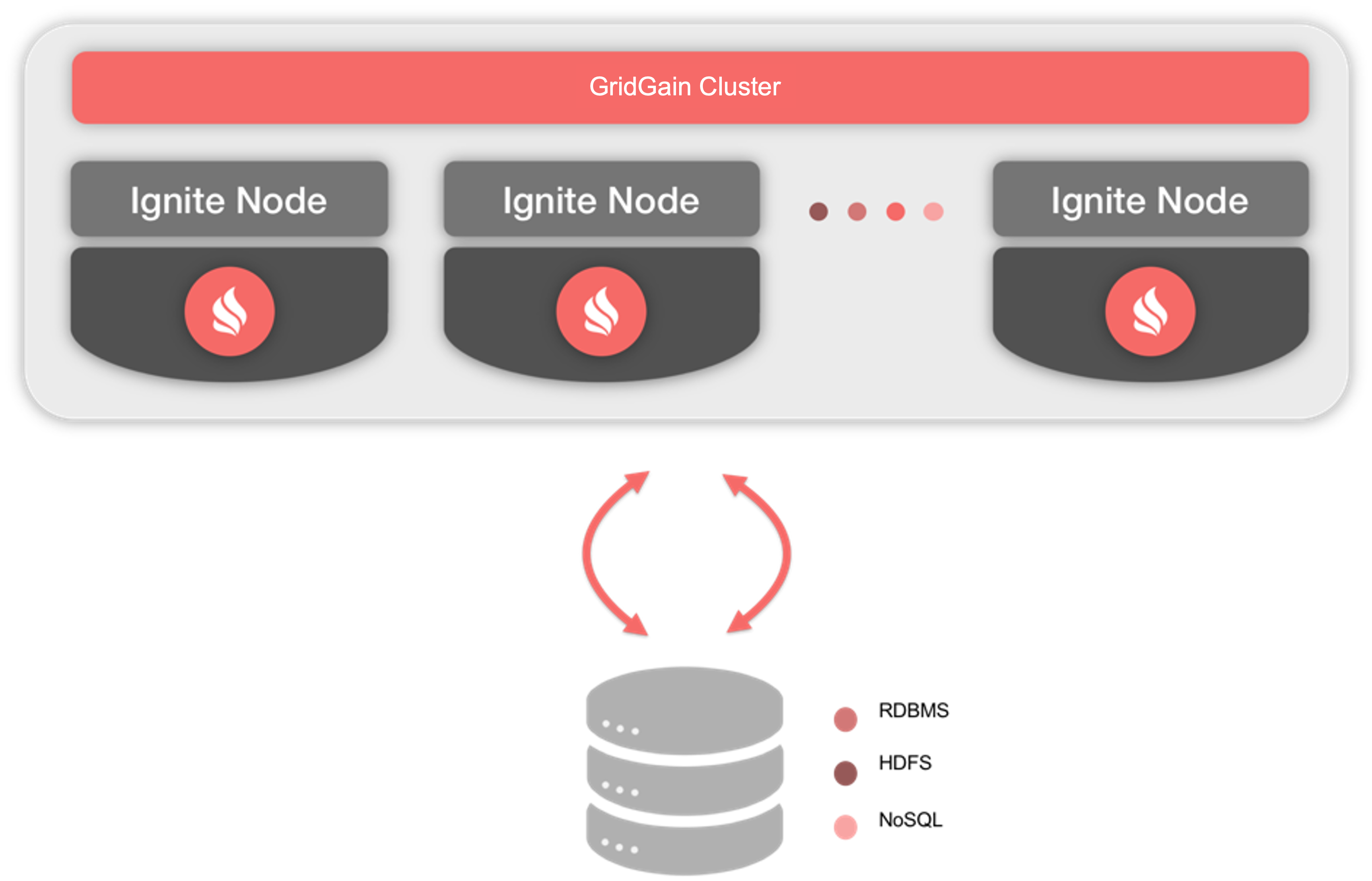
Figure 1. Persistence with Third-Party Stores
However, this approach has some disadvantages which we will discuss in a future article.
As an alternative to third-party persistence stores, GridGain developed a Durable Memory architecture, as shown in Figure 2. This architecture provides for the storage and processing of data and indexes both in-memory and on-disk. This GridGain Persistence feature is easily enabled and helps GridGain achieve in-memory performance with the durability of disk, cluster-wide.
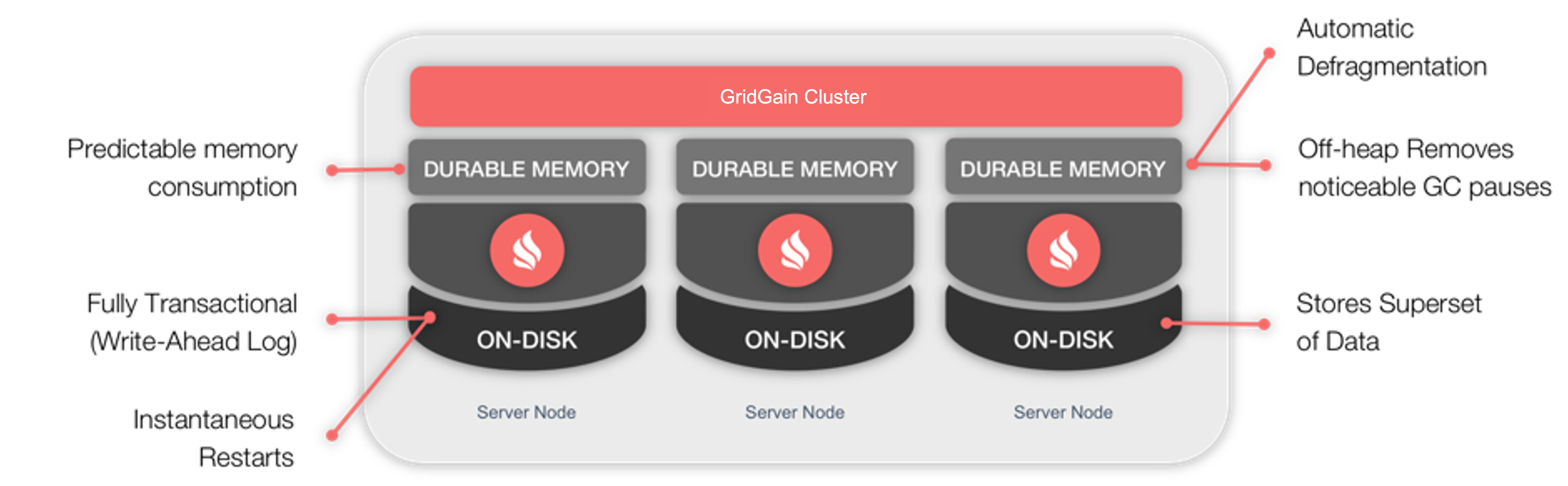
Figure 2. Durable Memory
GridGain’s Durable Memory is built and operates in a similar way to that of Virtual Memory found today in many modern operating systems. However, a key difference is that Durable Memory always keeps the whole data set and indexes on disk if the GridGain Persistence is used, while Virtual Memory only uses the disk for swapping.
Figure 2 also highlights some of the key characteristics of the Durable Memory architecture. For the in-memory part, the benefits include [1]:
- Off-heap: All data and indexes are stored outside of the Java heap. This allows the easy processing of large quantities of cluster data.
- The removal of noticeable Garbage Collection pauses: By storing all data and indexes off-heap, only application code could cause stop-the-world Garbage Collection pauses.
- Predictable memory usage: Memory utilization is fully configurable to suit particular application needs.
- Automatic memory defragmentation: GridGain avoids memory fragmentation by executing defragmentation routines. These routines are performed at the same time as data access and may be termed as lazy defragmentation.
- Improved performance and memory utilization: GridGain uses the same format to represent data and indexes in-memory and on-disk, avoiding the need to convert between different formats.
For the native persistence part, the benefits include [1]:
- Optional persistence: It is easy to configure how data are stored (in-memory, in-memory + disk), or when memory is used as a caching layer for disk.
- Data resiliency: Native persistence stores the full data set, and can survive cluster crashes and restarts, without losing any data and still providing strong transactional consistency.
- Caching hot data in-memory: Durable memory can keep hot data in RAM, and automatically purge cold data from memory when memory space is reduced.
- Execute SQL over data: GridGain can function as a fully distributed transactional SQL database.
- Fast cluster restarts: GridGain can restart and become operational very quickly if there is a major cluster failure.
Furthermore, the Persistent Store is ACID-compliant, and can store data and indexes on Flash, SSD, Intel 3D XPoint and other non-volatile storage. Whether GridGain is used with or without persistence, each cluster node manages a subset of the overall cluster data.
Let's now discuss two mechanisms that GridGain uses to manage persistence and provide transactional and consistency guarantees: Write-Ahead Log (WAL) and Checkpointing. We'll begin with the WAL.
Write-Ahead Log (WAL)
When GridGain Persistence is enabled, for every partition stored on a cluster node, GridGain maintains a dedicated partition file. When data are updated in RAM, the update is not directly written to the appropriate partition file but is appended to the end of a Write-Ahead Log (WAL). Using a WAL provides far superior performance when compared to in-place updates. Furthermore, the WAL provides a recovery mechanism in the event of a node or cluster failure.
The WAL is split into several files, called segments. These segments are filled sequentially. By default, 10 segments are created, and this number is configurable. These segment files are used as follows. When the first segment is full, it is copied to a WAL archive file. This archive is kept for a configurable period of time. As data are being copied from the first segment to the archive, the second segment becomes the active WAL file. This process is repeated for each segment file.
The WAL provides many different modes of operation with varying consistency guarantees, ranging from very strong consistency with no data loss to no consistency and potential data loss.
As previously mentioned, every update is appended to the WAL first. Each update is uniquely identified with a cache ID, and entry key. Therefore, the cluster can always be recovered to the latest successfully committed transaction or atomic update in the event of a crash or restart.
The WAL stores both logical and physical records. The logical records describe transaction behavior and are structured as follows [2]:
- Operation description (DataRecord): This stores information on the operation type (create, update, delete) and (Key, Value, Version).
- Transactional record (TxRecord): This stores information on the transaction (begin prepare, prepared, commit, rollback).
- Checkpoint record (CheckpointRecord): This stores begin checkpointing information.
The structure of the data record is graphically illustrated in Figure 3.
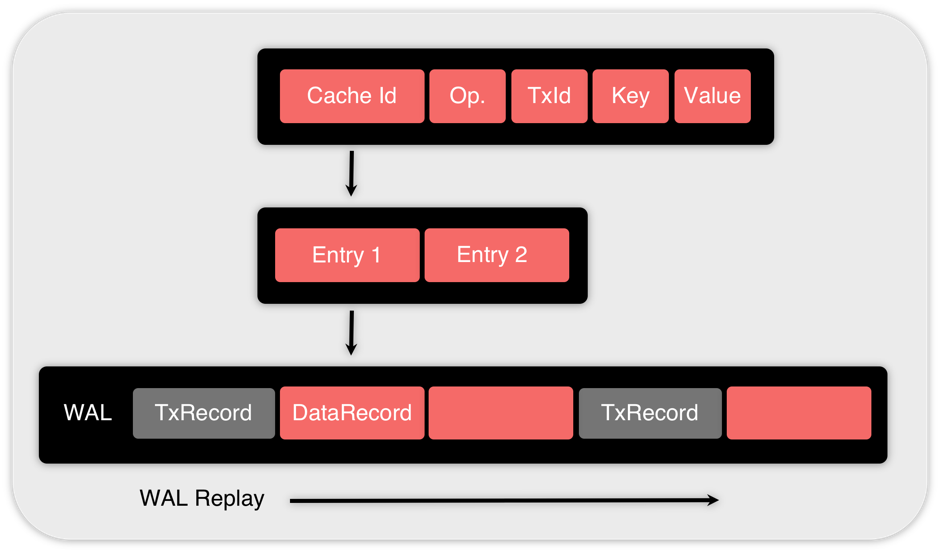
Figure 3. Structure of the DataRecord
As we can see in Figure 3, a DataRecord includes a list of entry operations (e.g. Entry 1, Entry 2). Each entry operation has:
- Cache Id
- Operation type
- Transaction Id
- Key
- Value
The operation type can be one of the following:
- Create: first put in the cache, contains (Key, Value).
- Update: put for existing key, contains (Key, Value).
- Delete: remove key, contains (Key).
If there are several updates for the same key within a transaction, these updates are merged into a single update using the latest values.
Checkpointing
In the event of a cluster failure, recovery could take a long time as the WAL may be quite large. To solve this problem, GridGain uses checkpointing. Checkpointing is also required if all the data cannot fit into memory and must be written to disk so that all the data can be queried.
Recall that updates are appended to the WAL, but updated (dirty) pages in memory still need to be copied to the appropriate partition file. The process of copying these pages from memory to partition files is called checkpointing. The benefits of checkpointing are that pages on disk are kept up-to-date and the WAL archive can be trimmed as old segments are removed.
In Figure 4, we can see the checkpointing process at work.
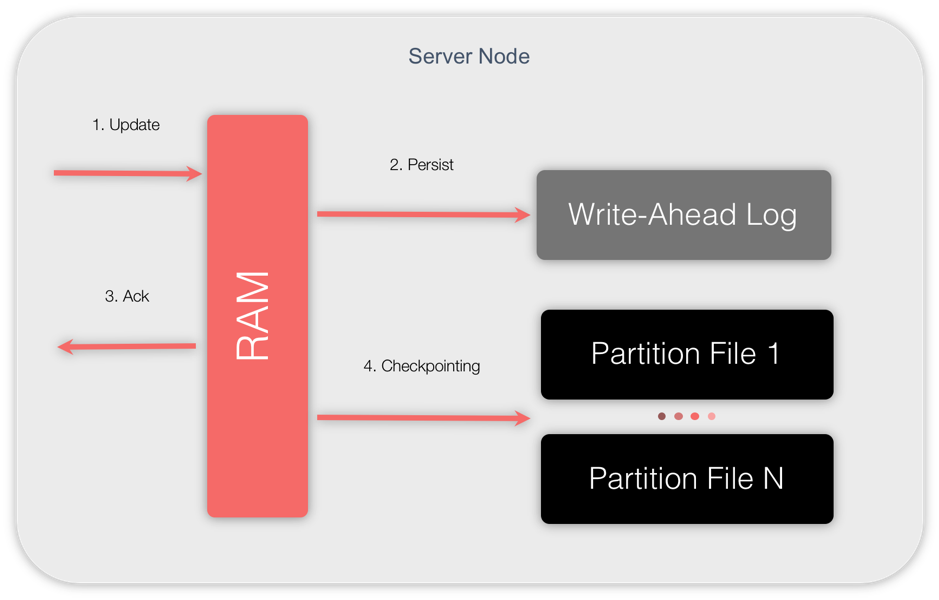
Figure 4. GridGain Native Persistence
The message flows are as follows:
- A cluster node receives an update request (1. Update). The node looks up the data page in RAM where the value is to be inserted or updated. The page is updated and marked as dirty.
- The update is appended to the end of the WAL (2. Persist).
- The node sends an acknowledgment to the initiator of the update, confirming that the operation was successful (3. Ack).
- Periodically, checkpointing is triggered (4. Checkpointing). The frequency of the checkpointing process is configurable. Dirty pages are copied from RAM to disk and passed on to specific partition files.
When considering transactions and checkpointing, GridGain uses a checkpointLock that provides the following warranties [3]:
- 1 begin checkpoint and 0 updates running
- 0 begin checkpoint and N updates running
A begin checkpoint does not wait for a transaction to finish. This means that a transaction may start before a checkpoint, but it will be committed during a running checkpoint process or after a checkpoint process ends.
Snapshots
Another mechanism that can assist with data recovery is snapshots. This is a feature that GridGain provides in its Ultimate Edition. Snapshots are the equivalent of backups in database systems [4].
Summary
GridGain Persistence provides robust features for managing persistent data. The WAL provides superior performance with recovery in the event of node or cluster failure. Checkpointing allows dirty pages to be flushed to disk and keeps the WAL in check. Persistent Store transactional consistency operates in the same way that it does in memory. Snapshots are also available in the commercial version of GridGain, available from GridGain.
Be sure to check out the other articles in this “GridGain Transactions Architecture” series:
- GridGain Transactions Architecture: 2-Phase Commit Protocol
- GridGain Transactions Architecture: Concurrency Modes and Isolation Levels
- GridGain Transactions Architecture: Failover and Recovery
- GridGain Transactions Architecture: Transaction Handling at the Level of 3rd Party Persistence
If you have further questions about GridGain persistence, please Contact Us and we can connect you with an GridGain expert.
References
[1] Durable Memory
[2] Ignite Persistent Store - under the hood: Logical Records
[3] Ignite Persistent Store - under the hood: Checkpointing
[4] Apache® Ignite™ Native Persistence: What about data recovery? Solved!
This post was originally written by Akmal Chaudhri, Technical Evangelist at GridGain.