
This blog post is the second one in the series of articles that provides a step-by-step guide on how to build a fault-tolerant and scalable microservices-based solution with Apache Ignite Service APIs.
In the first post one of the possible architectures was presented and explained as a system consisted of the following layers:
- Apache Ignite Cluster Layer
- Persistent Storage Layer
- Layer Used by External Applications
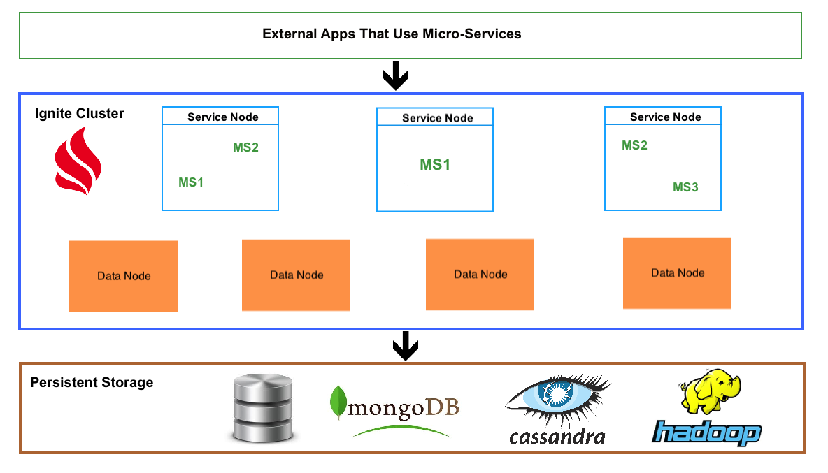
- Configuration and launching of data nodes.
- Exemplary services' implementation using Apache Ignite Service Grid API.
- Configuration and launching of service nodes hosting specific Apache Ignite services.
- A dummy application that connects to the cluster and triggers services execution.
Data Nodes
As it was learned from the first post, a data node is an Apache Ignite server node that holds a portion of the dataset and executes queries and computations coming from application logic side over this dataset. In general, this type of nodes is agnostic to application logic because the nodes simply need to store datasets and process them efficiently when an application talks to the data.
Let's have a look at how a data node can be defined at the implementation layer.
Download the provided GitHub project and locate data-node-config.xml that is used to spawn a new data node. The configuration contains a number of data nodes related sections and parameters.
First, we need to set a special node filter for every Apache Ignite cache that is going to be deployed in the cluster. The filter is called upon a cache startup to define a subset of the cluster nodes where cache data will be stored - data nodes. The same filter will be called every time the cluster topology changes which happen when a new cluster node joins the cluster or an old one leaves it. An implementation of the filter has to be added to the classpath of every Apache Ignite node regardless of the fact whether is node going to be a data node or not.
<bean class="org.apache.ignite.configuration.CacheConfiguration">
...
<property name="nodeFilter">
<bean class="common.filters.DataNodeFilter"/>
</property>
</bean>
Second, the filter has to be implemented. In this example, we use one of the most straightforward implementations. DataNodeFilter decides if an Apache Ignite node should be considered as a data node by checking custom "data.node" parameter. If the node has this parameter set in its attributes map then it will be a data node and the cache data will be hosted on it, otherwise the node will be ignored.
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("data.node");
return dataNode != null && dataNode;
}
And, third, data-node-config.xml adds "data.node" parameter to the attributes map of every node that uses the config at start time. This is how it's done.
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="data.node" value="true"/>
</map>
</property>
At the end, start an instance of a data node use DataNodeStartup file from the example or pass data-node-config.xml to Apache Ignite's ignite.sh/bat scripts. If you prefer the latter then make sure to build a jar file that will contain all the classes from java/app/common directory. The jar has to be added to the classpath of every data node.
Service Nodes
The definition of a service node at the implementation layer is not much different from the approach used for data nodes in the previous section. Basically, we need to establish a way that will specify a subset of Apache Ignite nodes where a particular microservice supposed to be deployed.
Initially, we need to implement a microservice using Apache Ignite Service Grid APIs. For the sake of the blog post let's review one of the existing implementations available in the provided GitHub example - the Maintenance Service.
The service allows scheduling a vehicle maintenance service and see a list of existed appointments. It implements all required Service Grid methods which are init(...), execute(...) and cancel(...) and introduces the new ones in its own unique Java interface:
public interface MaintenanceService extends Service
{
public Date scheduleVehicleMaintenance(int vehicleId);
public List<Maintenance> getMaintenanceRecords(int vehicleId);
}
There are several ways to configure and deploy Maintenance Service on a specific Apache Ignite nodes - service nodes. In our case, every node that might be considered for a Maintenance Service deployment has to be started with maintenance-service-node-config.xml. Let's look in the configuration.
First, to make sure that an instance of Maintenance Service is deployed on specific nodes only we need to set a node filter.
<bean class="org.apache.ignite.services.ServiceConfiguration">
<property name="nodeFilter">
<bean class="common.filters.MaintenanceServiceFilter"/>
</property>
</bean>
Second, the filter that is used for Maintenance Service allows deploying an instance of the service on a node only if the node has "maintenance.service.node" in its attributes map.
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("maintenance.service.node");
return dataNode != null && dataNode;
}
Finally, every node started with maintenance-service-node-config.xml will have this attribute in its map thanks to this XML section:
<property name="userAttributes">
<map key-type="java.lang.String" value-type="java.lang.Boolean">
<entry key="maintenance.service.node" value="true"/>
</map>
</property>
That's it. Start one or more instances of a Maintenance Service node using MaintenanceServiceNodeStartup file or pass maintenance-service-node-config.xml to Apache Ignite's ignite.sh/bat scripts. If you prefer the latter then make sure to build a jar file that will contain all the classes from java/app/common and java/services/maintenance directories. The jar has to be added to the classpath of every node where the service might be deployed.
The example contains one more Apache Ignite Service for Vehicles management. Start at least one instance of a service node where this service can be deployed using VehicleServiceNodeStartup file or ignite.sh/bat script with vehicle-service-node-config.xml configuration. Don't forget to assemble a jar with required classes and add it to the classpath of the node if you go for with ignite.sh/bat approach.
Sample Application
Once we have our data nodes, Maintenance Service and Vehicles Service nodes up and running we're ready to run the first sample application that will talk to our distributed microservices.
Locate and start TestAppStartup file from the example. The application connects to the cluster, fills predefined caches in with dummy data and interacts with the developed services.
MaintenanceService maintenanceService = ignite.services().serviceProxy(MaintenanceService.SERVICE_NAME,
MaintenanceService.class, false);
int vehicleId = rand.nextInt(maxVehicles);
Date date = maintenanceService.scheduleVehicleMaintenance(vehicleId);
If you note, the application works with the services using service proxies. The beauty of the proxies is that the node which is started as a part of the application process doesn't need to have a service implementation in the local classpath and an instance of the service being deployed locally.
To be continued
In this blog post it was shown how to implement Apache Ignite Cluster Layer from the proposed microservices-based architecture. In the next posts from of the series we will look into the implementation details of the layers that are left: