The GridGain Systems In-Memory Computing Blog


In-memory computing is a journey that requires up-front planning and preparation to complete. Companies often start with caching to add speed and scale to existing applications. But before you know it, you're building new hybrid transactional/analytical processing (HTAP) applications, new streaming analytics applications, or even starting to implement machine and deep learning. If you don't…

Learn how Kubernetes can orchestrate a distributed database or in-memory computing solutions using Apache® Ignite™ as an example.
Denis Madga, GridGain's director of product management, took one of his most popular meetup talks and turned it into a webinar on July. And he recorded it! His talk is available for playback (along with his slides) here.
In-memory computing technologies such…

With real-time streaming analytics there is no room (or time) for staging or disk.
Denis Magda, GridGain's director of product management and Apache Ignite PMC chair, delivered an excellent webinar Sept. 12 detailing the best practices used for real-time stream ingestion, processing and analytics using Apache® Ignite™, GridGain®, Apache Kafka™, Apache Spark™ and other technologies.
The webinar…


In the previous article in this Machine Learning series, we looked at k-NN Classification with Apache® Ignite™. We’ll now look at another Machine Learning algorithm and conclude our series. In this article, we’ll look at K-Means Clustering using the Titanic dataset. Very conveniently, Kaggle provides the dataset in a CSV form. For our analysis, we are interested in two clusters: whether…
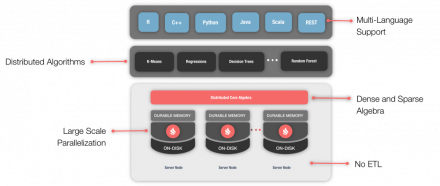
Apache® Ignite™ is a very versatile product that supports a wide-range of integrated components. These components include a Machine Learning (ML) library that supports popular ML algorithms, such as Linear Regression, k-NN Classification, and K-Means Clustering.
The ML capabilities of Ignite provide a wide-range of benefits, as shown in Figure 1. For example, Ignite can work on the data in place…
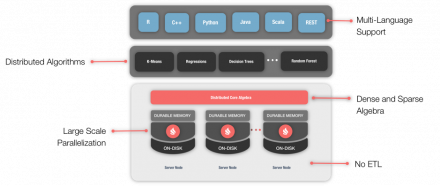
In the previous article in this Machine Learning series, we looked at Linear Regression with Apache® Ignite™. Now let’s take the opportunity to try another Machine Learning algorithm. This time we’ll look at k-Nearest Neighbor (k-NN) Classification. This algorithm is useful for determining class membership, where we classify an object based upon the most common class amongst its k nearest…
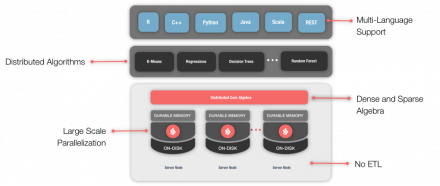
In the previous article in this Machine Learning series, we looked at the Apache® Ignite™ Machine Learning Grid. Now let’s take the opportunity to drill-down further into some of the Machine Learning algorithms that are supported in Apache Ignite and try out some examples using popular datasets.
If we search for suitable datasets to use, we can find many that are available. However, one dataset…
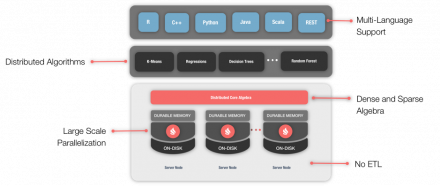
In a previous article, we discussed the Apache® Ignite™ Machine Learning Grid. At that time, a beta release was available. Subsequently, in version 2.4, Machine Learning became Generally Available. Since the 2.4 release, more improvements and developments have been added, including support for Partitioned-Based Datasets and Genetic Algorithms. Many of the Machine Learning examples that are…


In case you hadn’t noticed, this year’s annual Spark conference is, for the first time, the Spark+AI Summit. The fact that Spark and AI should be together is predictable even without… using AI to figure it out. But there’s only one way to add continuous learning to Spark+AI, to make AI learn and adapt to new information in near real-time like a person. It is not the AllSpark, which is used to…

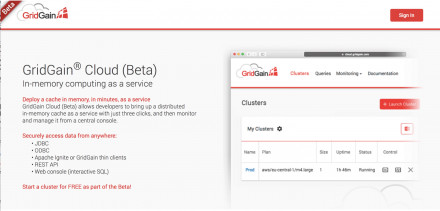
The GridGain in-memory computing platform has always been famous for its ability to be deployed and managed in heterogeneous environments. It doesn’t matter if you’d like GridGain to work on-premise or to operate in the cloud; to scale out across commodity servers or scale up within powerful mainframes. And if need to get GridGain provisioned by Kubernetes or Docker Swarm -- you get…